背景意义
研究背景与意义
胃部病变的早期检测对于降低胃癌及其他相关疾病的发病率具有重要意义。随着生活方式的改变和饮食习惯的多样化,胃部疾病的发生率逐年上升,给患者的健康和生活质量带来了严重影响。因此,开发高效、准确的胃部病变检测系统,能够为临床提供及时的诊断支持,进而改善患者的预后。
在众多的计算机视觉技术中,基于深度学习的目标检测方法因其高效性和准确性而受到广泛关注。YOLO(You Only Look Once)系列模型因其实时检测能力和较高的精度,成为了目标检测领域的主流选择。YOLOv11作为该系列的最新版本,具备更强的特征提取能力和更快的推理速度,适合用于复杂的医学图像分析任务。然而,现有的YOLO模型在处理特定领域的医学图像时,往往面临数据稀缺和标注不均的问题。
本研究旨在基于改进的YOLOv11模型,构建一个针对胃部病变的检测系统。我们将利用Gastrix-inst-seg数据集,该数据集包含1753幅经过精细标注的胃部图像,涵盖了多种病变类型,包括中度活动、重度活动和化生等。通过对数据集的深度分析和处理,我们将实施数据增强技术,以提高模型的泛化能力和鲁棒性。
本项目的意义在于,通过结合先进的深度学习技术与丰富的医学图像数据,提升胃部病变的检测精度,进而为临床医生提供更为可靠的辅助诊断工具。这不仅能够加速胃部疾病的早期发现,还将为相关研究提供数据支持,推动胃部疾病检测技术的发展,最终实现提高患者生存率和生活质量的目标。
图片效果
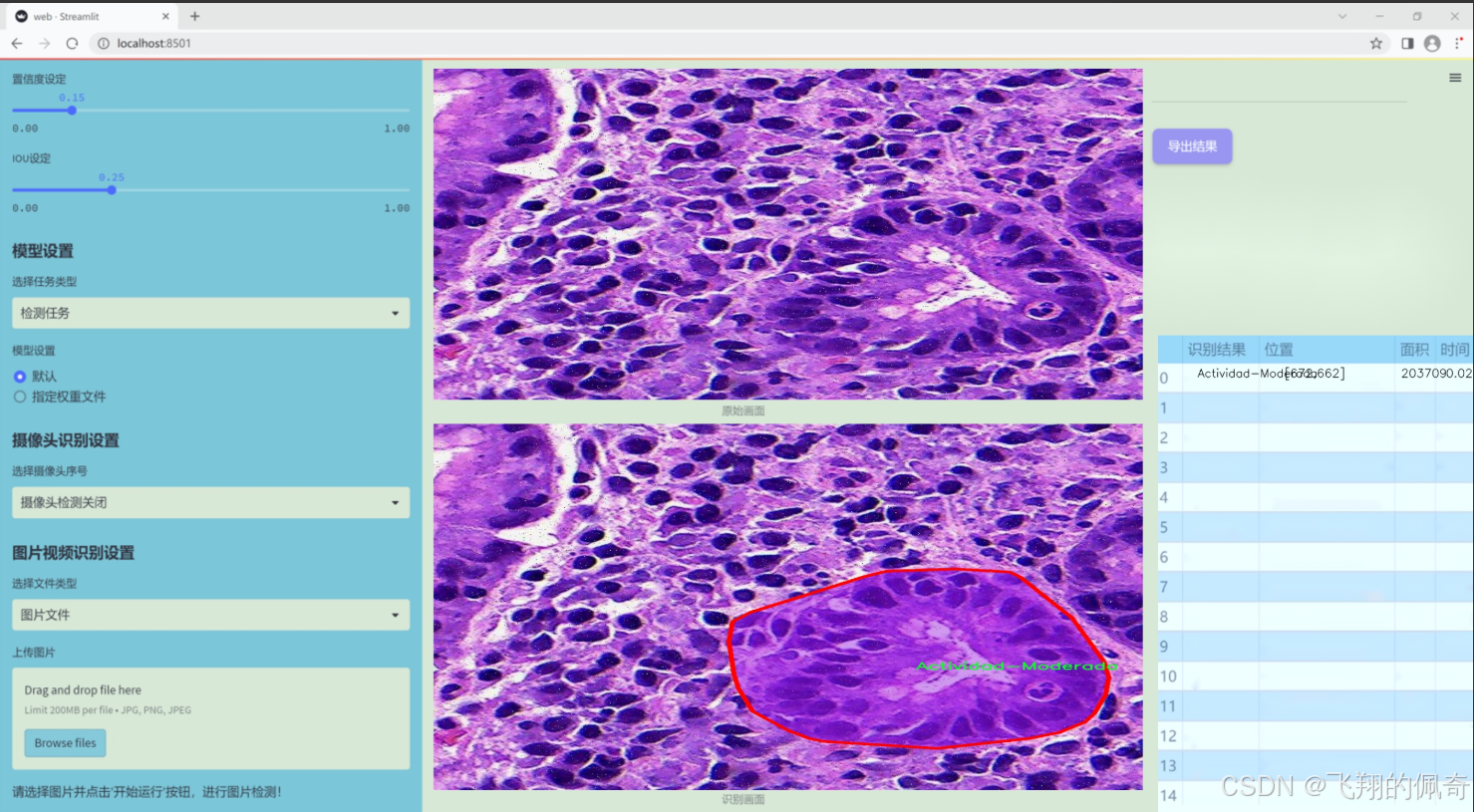
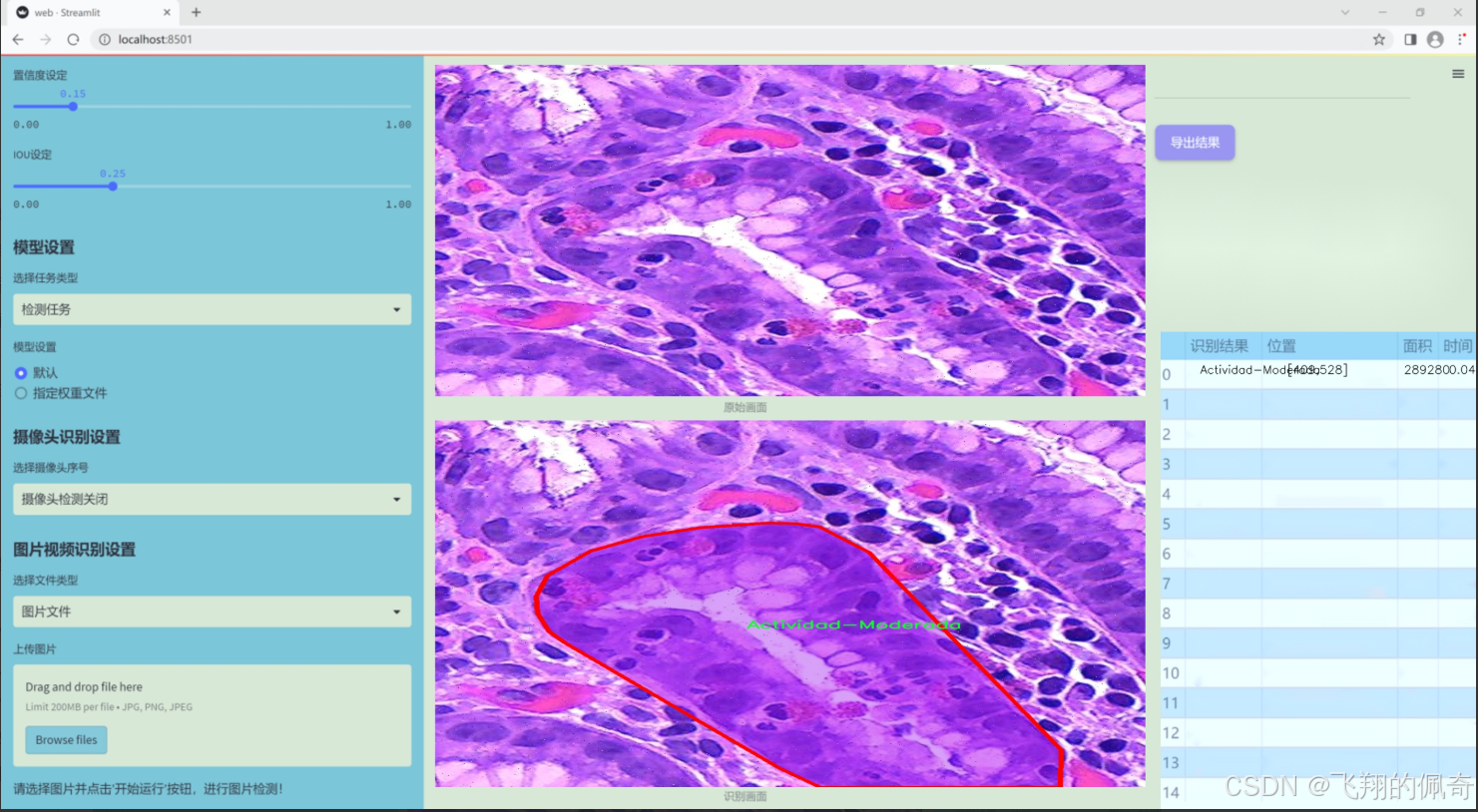
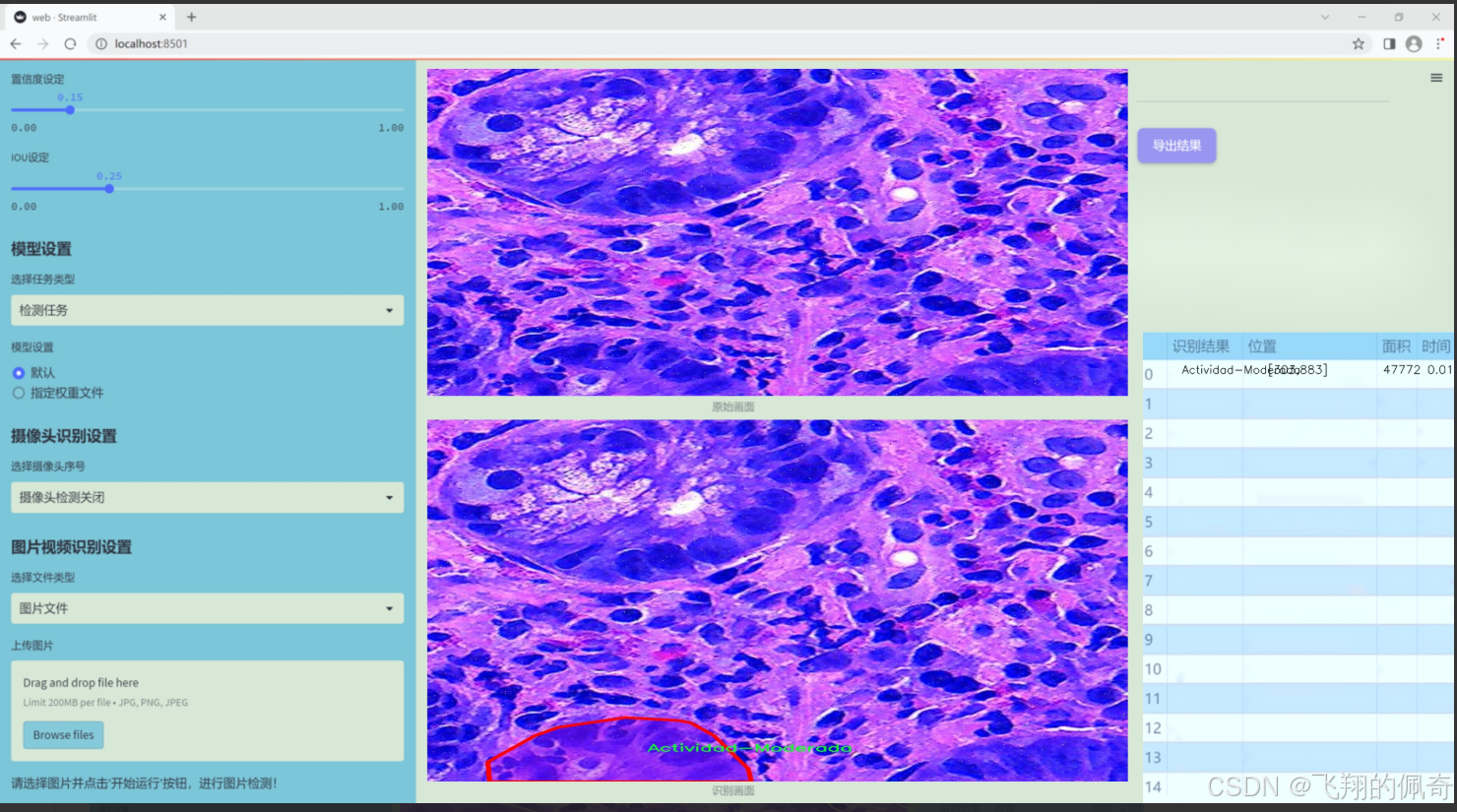
数据集信息
本项目数据集信息介绍
本项目旨在改进YOLOv11的胃部病变检测系统,所使用的数据集名为“Gastrix-inst-seg”。该数据集专注于胃部病变的自动检测与分类,具有重要的临床应用价值。数据集中包含三种主要类别,分别为“Actividad-Moderada”(中度活动)、“Actividad-Severa”(重度活动)和“Metaplasia”(化生)。这些类别涵盖了胃部病变的不同严重程度和类型,为模型的训练提供了丰富的样本和多样化的特征。
在数据集的构建过程中,研究团队收集了大量的胃部内镜图像,并对其进行了精细的标注和分类。每一张图像都经过专业医生的审核,确保标注的准确性和可靠性。这种高质量的标注不仅提升了数据集的实用性,也为后续的模型训练提供了坚实的基础。数据集中包含的样本数量充足,能够有效支持深度学习模型的训练和验证,确保模型在不同场景下的泛化能力。
此外,数据集的设计考虑到了多样性和代表性,涵盖了不同患者的胃部病变情况,包括不同年龄、性别和病史的患者。这种多样性使得模型能够更好地适应临床实际情况,提高其在真实环境中的应用效果。通过对“Gastrix-inst-seg”数据集的深入分析与训练,期望能够显著提升YOLOv11在胃部病变检测中的准确性和效率,为临床医生提供更为可靠的辅助诊断工具,从而改善患者的治疗效果和生活质量。
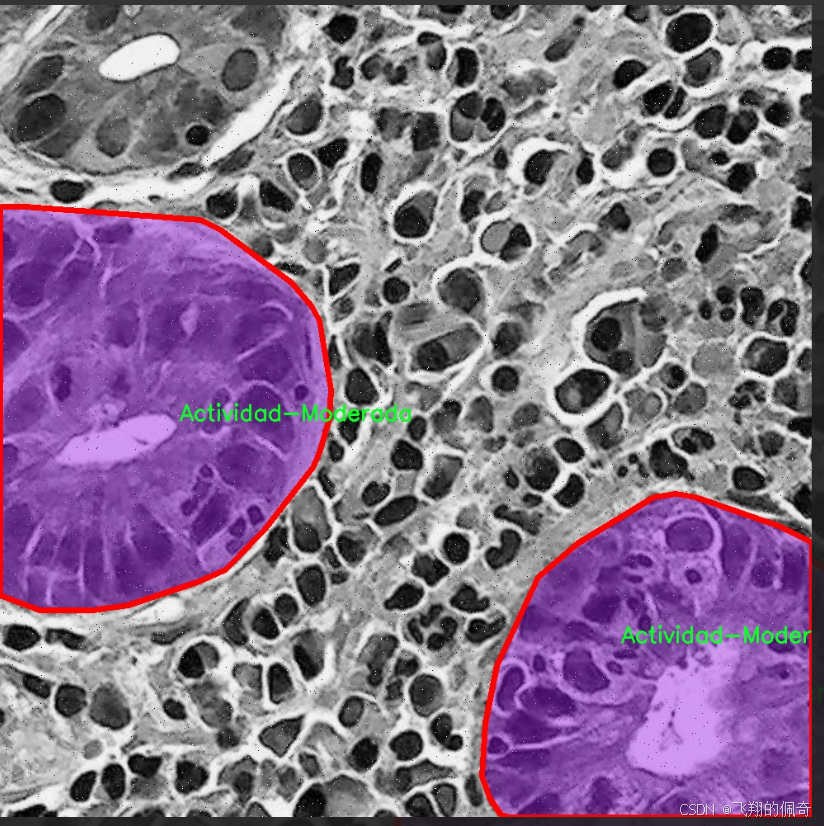
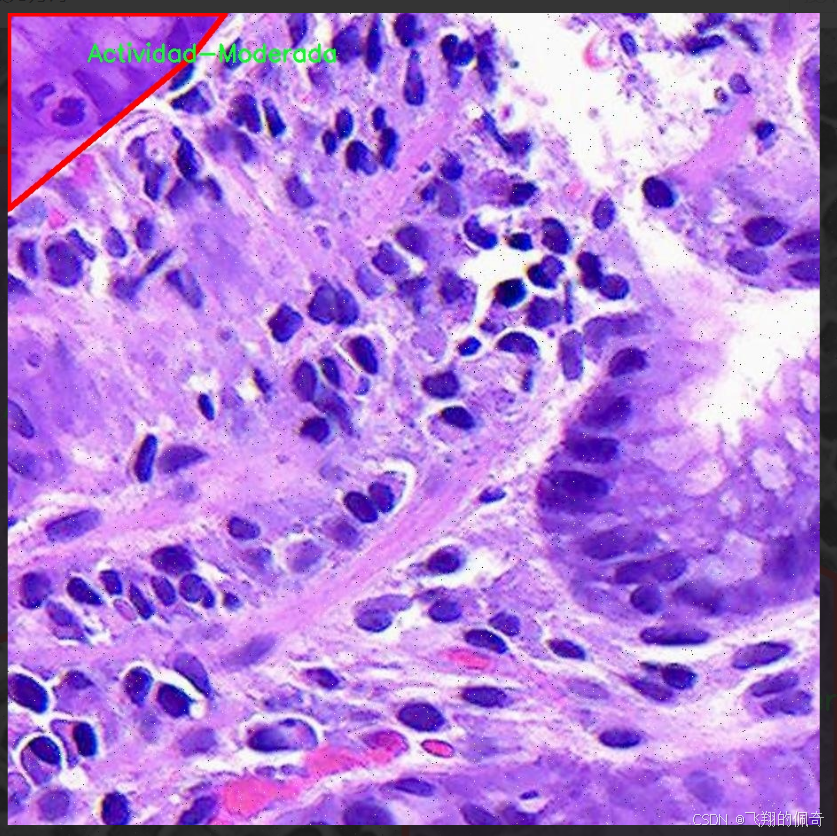
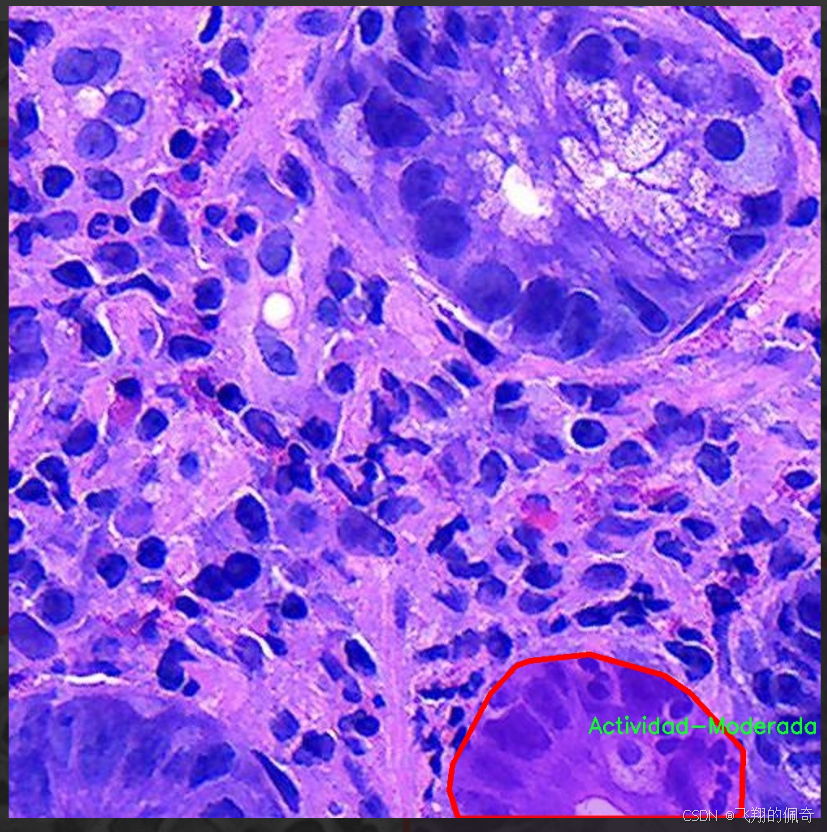
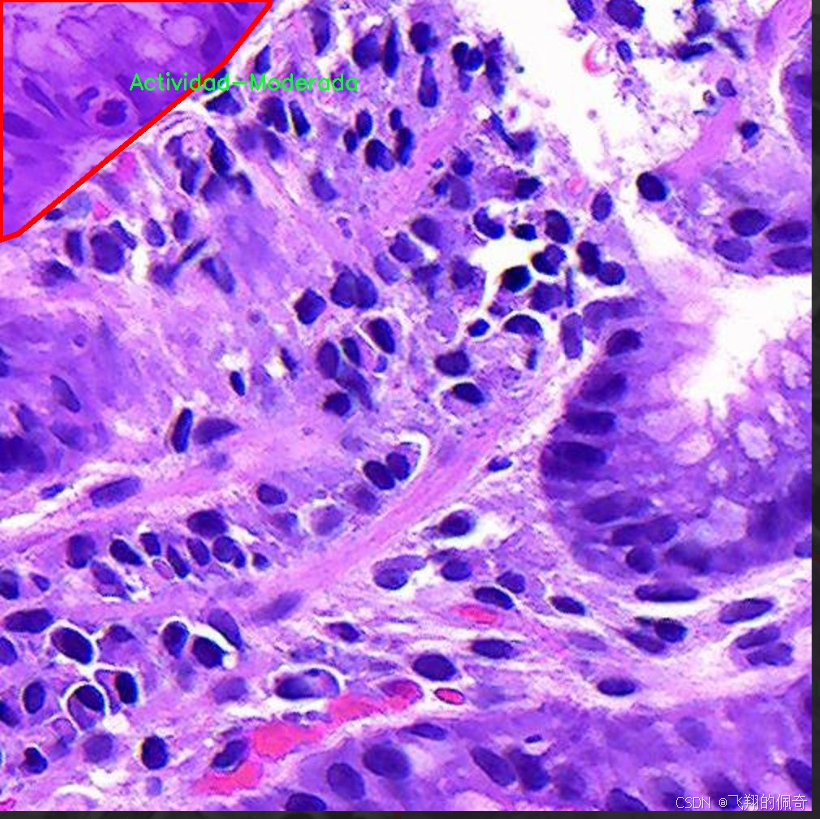
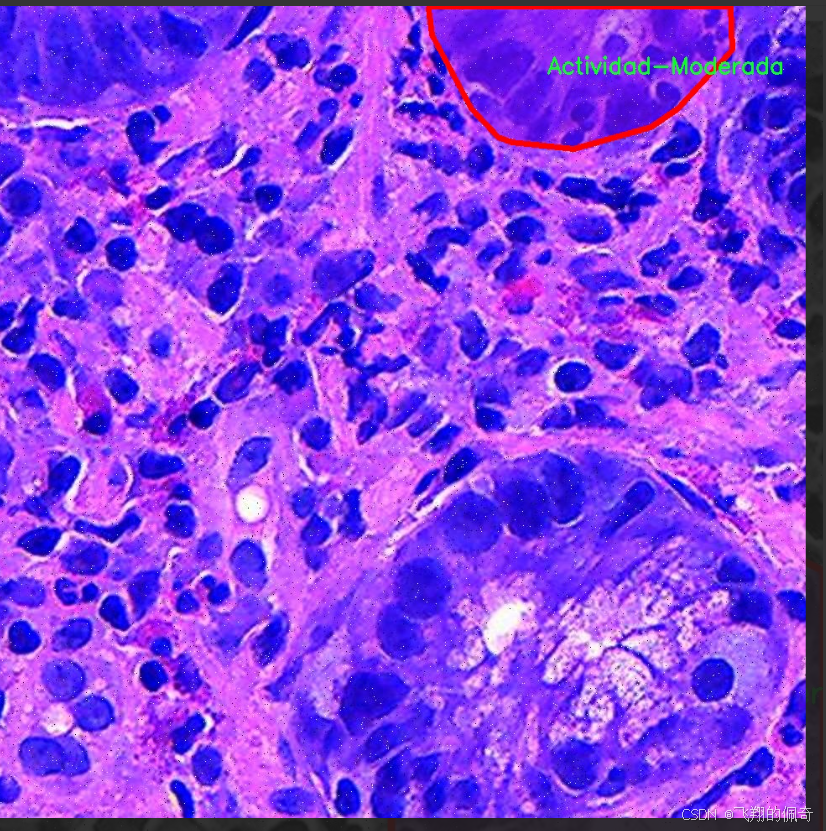
核心代码
以下是经过简化和注释的核心代码部分,主要保留了反向传播和前向传播的逻辑。
import torch
import torch.nn as nn
class ReverseFunction(torch.autograd.Function):
@staticmethod
def forward(ctx, run_functions, alpha, *args):
# 保存运行的函数和alpha参数
ctx.run_functions = run_functions
ctx.alpha = alpha
# 解包输入参数
x, c0, c1, c2, c3 = args
# 使用无梯度计算来进行前向传播
with torch.no_grad():
# 依次调用每个函数并计算输出
c0 = run_functions[0](x, c1) + c0 * alpha[0]
c1 = run_functions[1](c0, c2) + c1 * alpha[1]
c2 = run_functions[2](c1, c3) + c2 * alpha[2]
c3 = run_functions[3](c2, None) + c3 * alpha[3]
# 保存用于反向传播的张量
ctx.save_for_backward(x, c0, c1, c2, c3)
return x, c0, c1, c2, c3
@staticmethod
def backward(ctx, *grad_outputs):
# 从上下文中获取保存的张量
x, c0, c1, c2, c3 = ctx.saved_tensors
run_functions = ctx.run_functions
alpha = ctx.alpha
# 解包梯度输出
gx_right, g0_right, g1_right, g2_right, g3_right = grad_outputs
# 反向传播计算
g3_up = g3_right
g3_left = g3_up * alpha[3] # shortcut
oup3 = run_functions[3](c2, None)
torch.autograd.backward(oup3, g3_up, retain_graph=True)
# 计算特征反向
c3_left = (1 / alpha[3]) * (c3 - oup3)
g2_up = g2_right + c2.grad
g2_left = g2_up * alpha[2] # shortcut
# 继续反向传播
c2_left = (1 / alpha[2]) * (c2 - run_functions[2](c1, c3_left))
g1_up = g1_right + c1.grad
g1_left = g1_up * alpha[1] # shortcut
# 最后一步反向传播
g0_up = g0_right + c0.grad
g0_left = g0_up * alpha[0] # shortcut
# 返回梯度
return None, None, gx_up, g0_left, g1_left, g2_left, g3_left
class SubNet(nn.Module):
def init(self, channels, layers, kernel, first_col, save_memory) -> None:
super().init()
# 初始化网络层
self.level0 = Level(0, channels, layers, kernel, first_col)
self.level1 = Level(1, channels, layers, kernel, first_col)
self.level2 = Level(2, channels, layers, kernel, first_col)
self.level3 = Level(3, channels, layers, kernel, first_col)
def forward(self, *args):
# 前向传播逻辑
if self.save_memory:
return self._forward_reverse(*args)
else:
return self._forward_nonreverse(*args)
def _forward_nonreverse(self, *args):
# 非反向传播的前向计算
x, c0, c1, c2, c3 = args
c0 = self.level0(x, c1)
c1 = self.level1(c0, c2)
c2 = self.level2(c1, c3)
c3 = self.level3(c2, None)
return c0, c1, c2, c3
def _forward_reverse(self, *args):
# 反向传播的前向计算
local_funs = [self.level0, self.level1, self.level2, self.level3]
alpha = [self.alpha0, self.alpha1, self.alpha2, self.alpha3]
return ReverseFunction.apply(local_funs, alpha, *args)
class RevCol(nn.Module):
def init(self, kernel=‘C2f’, channels=[32, 64, 96, 128], layers=[2, 3, 6, 3], num_subnet=5, save_memory=True) -> None:
super().init()
self.num_subnet = num_subnet
self.channels = channels
self.layers = layers
# 初始化网络的stem部分
self.stem = Conv(3, channels[0], k=4, s=4, p=0)
# 初始化多个子网络
for i in range(num_subnet):
first_col = (i == 0)
self.add_module(f'subnet{str(i)}', SubNet(channels, layers, kernel, first_col, save_memory=save_memory))
def forward(self, x):
# 前向传播逻辑
c0, c1, c2, c3 = 0, 0, 0, 0
x = self.stem(x)
for i in range(self.num_subnet):
c0, c1, c2, c3 = getattr(self, f'subnet{str(i)}')(x, c0, c1, c2, c3)
return [c0, c1, c2, c3]
代码说明:
ReverseFunction: 这是一个自定义的反向传播函数,使用了 PyTorch 的 torch.autograd.Function。它实现了前向传播和反向传播的逻辑。
forward 方法计算前向传播的输出,并保存中间结果以便反向传播使用。
backward 方法计算梯度,使用保存的中间结果和输入的梯度输出进行反向传播。
SubNet: 这是一个子网络类,包含多个层级(Level)。根据 save_memory 参数选择是否使用反向传播优化。
RevCol: 这是主网络类,初始化多个子网络,并在前向传播中依次调用它们。通过 stem 层处理输入数据。
这个简化版本保留了反向传播的核心逻辑和网络结构,便于理解和使用。
这个程序文件 revcol.py 是一个基于 PyTorch 的深度学习模型实现,主要用于图像处理任务。它实现了一个名为 RevCol 的网络结构,结合了反向传播和特征融合的机制。以下是对代码的详细说明。
首先,文件导入了必要的 PyTorch 库和一些自定义模块。Conv、C2f、C3、C3Ghost 和 C3k2 是在其他模块中定义的卷积和块结构,可能用于构建网络的不同层。
接下来,定义了一些辅助函数。get_gpu_states 函数用于获取指定 GPU 设备的随机数生成器状态,get_gpu_device 函数则从输入的张量中提取出所有使用的 GPU 设备。set_device_states 函数用于设置 CPU 和 GPU 的随机数生成器状态。detach_and_grad 函数用于分离输入张量并启用梯度计算,确保在反向传播时不会影响原始张量的计算图。get_cpu_and_gpu_states 函数则返回当前 CPU 和 GPU 的随机数生成器状态。
接下来定义了一个名为 ReverseFunction 的类,继承自 torch.autograd.Function,实现了自定义的前向和反向传播逻辑。在 forward 方法中,首先保存输入和一些状态,然后通过多个层的函数计算输出。backward 方法则实现了反向传播的逻辑,计算梯度并处理各层之间的依赖关系。
Fusion 类用于实现特征融合,包含下采样和上采样的操作。Level 类表示网络的一个层级,包含融合和卷积模块。SubNet 类则是一个子网络,包含多个层级的组合,并实现了正向传播的两种方式:非反向传播和反向传播。
RevCol 类是整个模型的主体,初始化时定义了多个子网络和卷积层。它的 forward 方法负责将输入数据通过所有子网络进行处理,并返回最终的特征输出。
整个代码结构清晰,模块化设计使得各个部分易于理解和维护。该模型的设计理念在于通过反向传播和特征融合来提高网络的性能,同时提供了节省内存的选项。通过使用自定义的反向传播函数,模型能够在训练过程中更有效地处理梯度计算,适应更复杂的任务需求。
10.4 SwinTransformer.py
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
“”" 多层感知机 (MLP) 模块。“”"
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features # 输出特征数,如果未指定则与输入特征数相同
hidden_features = hidden_features or in_features # 隐藏层特征数,如果未指定则与输入特征数相同
self.fc1 = nn.Linear(in_features, hidden_features) # 第一层线性变换
self.act = act_layer() # 激活函数
self.fc2 = nn.Linear(hidden_features, out_features) # 第二层线性变换
self.drop = nn.Dropout(drop) # Dropout层
def forward(self, x):
""" 前向传播函数。"""
x = self.fc1(x) # 线性变换
x = self.act(x) # 激活
x = self.drop(x) # Dropout
x = self.fc2(x) # 线性变换
x = self.drop(x) # Dropout
return x
class WindowAttention(nn.Module):
“”" 基于窗口的多头自注意力 (W-MSA) 模块。“”"
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim # 输入通道数
self.window_size = window_size # 窗口大小
self.num_heads = num_heads # 注意力头数
head_dim = dim // num_heads # 每个头的维度
self.scale = qk_scale or head_dim ** -0.5 # 缩放因子
# 定义相对位置偏置参数表
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 位置偏置表
# 计算每个token的相对位置索引
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 生成网格坐标
coords_flatten = torch.flatten(coords, 1) # 展平坐标
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 计算相对坐标
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # 调整维度
relative_coords[:, :, 0] += self.window_size[0] - 1 # 偏移
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # 计算相对位置索引
self.register_buffer("relative_position_index", relative_position_index) # 注册为缓冲区
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias) # 线性变换生成q, k, v
self.attn_drop = nn.Dropout(attn_drop) # 注意力权重的Dropout
self.proj = nn.Linear(dim, dim) # 输出线性变换
self.proj_drop = nn.Dropout(proj_drop) # 输出的Dropout
trunc_normal_(self.relative_position_bias_table, std=.02) # 初始化相对位置偏置
self.softmax = nn.Softmax(dim=-1) # Softmax层
def forward(self, x, mask=None):
""" 前向传播函数。"""
B_, N, C = x.shape # B_: 批量大小, N: token数量, C: 通道数
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # 计算q, k, v
q, k, v = qkv[0], qkv[1], qkv[2] # 分离q, k, v
q = q * self.scale # 缩放q
attn = (q @ k.transpose(-2, -1)) # 计算注意力权重
# 添加相对位置偏置
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # 计算相对位置偏置
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # 调整维度
attn = attn + relative_position_bias.unsqueeze(0) # 加入偏置
if mask is not None: # 如果有mask
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0) # 应用mask
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn) # Softmax
else:
attn = self.softmax(attn) # Softmax
attn = self.attn_drop(attn) # Dropout
x = (attn @ v).transpose(1, 2).reshape(B_, N, C) # 计算输出
x = self.proj(x) # 线性变换
x = self.proj_drop(x) # Dropout
return x
class SwinTransformer(nn.Module):
“”" Swin Transformer 主体。“”"
def __init__(self, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24], embed_dim=96):
super().__init__()
self.embed_dim = embed_dim # 嵌入维度
self.layers = nn.ModuleList() # 存储每一层
# 构建每一层
for i_layer in range(len(depths)):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer), # 当前层的维度
depth=depths[i_layer], # 当前层的深度
num_heads=num_heads[i_layer], # 当前层的注意力头数
window_size=7, # 窗口大小
mlp_ratio=4. # MLP比率
)
self.layers.append(layer) # 添加到层列表中
def forward(self, x):
""" 前向传播函数。"""
for layer in self.layers:
x = layer(x) # 逐层前向传播
return x # 返回最终输出
def SwinTransformer_Tiny(weights=‘’):
“”" 创建一个小型的Swin Transformer模型。“”"
model = SwinTransformer(depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]) # 初始化模型
if weights:
model.load_state_dict(torch.load(weights)[‘model’]) # 加载权重
return model # 返回模型
代码核心部分说明:
Mlp类:实现了一个多层感知机,包括两个线性层和一个激活函数。
WindowAttention类:实现了窗口基础的多头自注意力机制,支持相对位置偏置。
SwinTransformer类:构建了Swin Transformer的主体结构,包含多个基本层(BasicLayer),每层由窗口注意力和MLP组成。
SwinTransformer_Tiny函数:用于创建一个小型的Swin Transformer模型,并可选择加载预训练权重。
这些部分是Swin Transformer模型的核心,构成了模型的主要功能和结构。
这个程序文件实现了Swin Transformer模型的构建,Swin Transformer是一种基于视觉的变换器架构,具有层次化的特性,适用于图像分类等任务。代码主要分为几个部分,下面对各个部分进行详细说明。
首先,导入了必要的库,包括PyTorch的核心库、神经网络模块、功能模块、以及一些用于处理模型层的工具。接着,定义了一个名为Mlp的类,表示多层感知机(MLP),它包含两个线性层和一个激活函数(默认为GELU),并在每个线性层后面添加了Dropout层以防止过拟合。
接下来,定义了两个辅助函数window_partition和window_reverse,用于将输入张量分割成窗口和将窗口合并回原始形状。这是Swin Transformer的关键操作之一,因为它通过窗口内的自注意力机制来处理图像。
然后,定义了WindowAttention类,它实现了基于窗口的多头自注意力机制。该类的构造函数中初始化了输入通道数、窗口大小、注意力头数等参数,并定义了相应的线性层和相对位置偏置表。forward方法实现了自注意力的计算,包括查询、键、值的生成,以及注意力权重的计算和应用。
接着,定义了SwinTransformerBlock类,表示Swin Transformer的基本块。它包含了规范化层、窗口注意力层、以及前馈网络(MLP)。在forward方法中,输入特征经过规范化、窗口分割、注意力计算、窗口合并等步骤,最后通过残差连接和前馈网络输出。
PatchMerging类实现了图像的分块合并,主要用于在不同的层之间降低特征图的分辨率。它将输入特征视为一个二维图像,并将相邻的块合并为一个新块,输出特征的维度减半。
BasicLayer类表示Swin Transformer的一个基本层,包含多个Swin Transformer块,并在必要时添加下采样层。它负责计算注意力掩码,并将输入特征传递给每个块。
PatchEmbed类实现了图像到补丁的嵌入,将输入图像分割成固定大小的补丁,并通过卷积层将其映射到更高维度的特征空间。
SwinTransformer类是整个模型的核心,负责构建Swin Transformer的各个层次。它接受输入图像并通过补丁嵌入、绝对位置嵌入、以及多个基本层进行处理,最终输出不同层次的特征。
最后,定义了update_weight函数,用于更新模型的权重,并提供了一个名为SwinTransformer_Tiny的函数,用于创建一个小型的Swin Transformer模型实例,并可选择加载预训练权重。
总体来说,这个程序文件实现了Swin Transformer的完整结构,包含了从输入图像到特征提取的所有步骤,适合用于计算机视觉任务。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式