🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
PyTorch分布式训练工具包中最强大的功能之一是DistributedDataParallel(DDP),该功能实现了从研究原型到大规模生产模型的扩展。乍看之下,它似乎很简单:封装模型、启动进程,训练就能在多个GPU上扩展。但作为研究人员和工程师,我们需要更深入地理解DDP如何分桶梯度、如何重叠通信与计算,以及如何确保大规模训练的效率。本文将通过一个最小实现来剖析这些内部机制。
在此过程中,我们将逐步理解PyTorch如何处理分布式训练、为什么集体通信操作至关重要,以及性能瓶颈可能出现在哪里。
如果你曾在单GPU上训练模型,但想了解多GPU训练的真正工作原理,那么这篇文章就是为你准备的。
一、为什么是DDP?
最简单的原因:更多的 GPU = 更快的训练速度。但并行训练并不像“简单拆分数据”那么容易。我们需要实现以下功能:
- 在多个 GPU 之间复制模型
- 分配输入批次,使每个 GPU 处理一个数据分片
- 聚合梯度以保持模型同步
- 在所有设备上一致地更新参数
这正是分布式数据并行(Distributed Data Parallel)提供的功能。
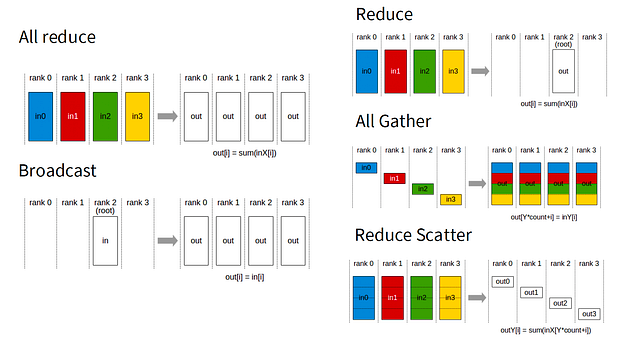
二、基础要素
在我们深入探讨DDP之前,需要先理解集体通信的概念:
- 全归约(All-Reduce):每个GPU提供一个张量,最终所有GPU都获得归约后(如求和或平均)的张量。
- 广播(Broadcast):一个GPU向其他所有GPU发送数据(用于启动时同步模型参数)。
- 规约分散(Reduce-Scatter):类似于全归约,但将归约结果的不同部分分发给各个GPU。
- 全收集(All-Gather):与规约分散相反——将分片聚合成完整张量。
PyTorch的torch.distributed库为这些基础操作提供了接口,当使用NCCL后端时,您将获得专为CUDA GPU高度优化的实现。我发现这个关于环形全归约(ring all-reduce)的解释对于理解GPU间如何高效完成通信很有帮助:GPU组成逻辑环结构,通过传递数据块直到所有节点获得完整结果。
步骤一、DDP的简单实现
让我们通过一个简化版本来了解PyTorch的操作原理。
class NaiveDDP(nn.Module):
def __init__(self, module, world_size):
"""
A simplified DDP implementation.
Args:
module: The model to parallelize
world_size: Number of parallel processes
"""
super().__init__()
self.module = module
self.world_size = dist.get_world_size()
#---步骤1:启动时广播参数---确保所有排名都以相同的参数开头
for param in self.module.parameters():
dist.broadcast(param.data, src=0) # Rank 0 sends to all others
# --- Step 2: Register gradient hooks ---
for p in self.module.parameters():
if p.requires_grad:
p.register_hook(self._make_allreduce_hook(p))
def _make_allreduce_hook(self, p):
"""Create a hook that performs all-reduce on gradients."""
def hook(grad):
# Sum gradients across all processes
dist.all_reduce(grad, op=dist.ReduceOp.SUM)
# Average the gradients (simulating a single large batch)
return grad / self.world_size
return hook
def forward(self, *args, **kwargs):
"""Simply forward through the wrapped module."""
return self.module(*args, **kwargs)模型会被广播到每个GPU上。所有设备初始参数完全相同。每个GPU独立运行前向传播并计算本地梯度。通过全归约操作(all-reduce),所有GPU的梯度会被平均化,使每个设备获得相同的"全局"梯度。各GPU使用平均后的梯度更新参数。由于初始参数相同且使用相同的平均梯度,所有模型在每一步后都能保持同步。
每个参数都需要一次全归约 = 大模型中成千上万次通信调用。每次调用都存在延迟开销,严重影响吞吐量。
步骤二、梯度批处理/平铺
第一个修复方案:将小梯度批处理成一个大张量 → 一次性规约 → 分散回原处
"""Flatten grads -> all_reduce once -> unflatten -> copy back."""
# Collect only grads that exist
params_with_grads = [p for p in self.module.parameters() if p.grad is not None]
grads = [p.grad for p in params_with_grads]
# Flatten all grads into a single contiguous tensor holding all the gradient data
flat_grads = torch._utils._flatten_dense_tensors(grads)
# Single AllReduce across all processes
dist.all_reduce(flat_grads, op=dist.ReduceOp.SUM)
flat_grads.mul_(1.0 / self.world_size) # average
# We use the original `grads` list as a template to unpack `flat_grads`
# back into a list of tensors with the correct original shapes.
synced_grads = torch._utils._unflatten_dense_tensors(flat_grads, grads)
# Now we can copy these correctly-shaped gradients back to the parameters
for p, g in zip(params_with_grads, synced_grads):
p.grad.copy_(g)现在,一个大型通信取代了多个小型通信。这本质上就是用一个巨大的桶进行分桶操作。更少的调用,更低的开销。
但仍然存在顺序性——通信必须等到反向传播完成后才能开始。
步骤三、重叠通信与计算
这里有一个更深的技巧:不要等到所有反向传播完成。在反向传播过程中,梯度是按层计算的。只要某个梯度准备就绪,我们就可以异步启动其All-Reduce操作,同时反向传播继续进行。在PyTorch中实现时,可以使用register_post_accumulate_grad_hook函数,在参数的梯度于反向传播中累积后自动调用相关函数。
将async_op=True设置为启用异步All-Reduce操作,并将它们加入队列。
# Register post-accumulate gradient hook for each parameter
def make_hook(param):
def hook(*_):
handle = dist.all_reduce(param.grad, op=dist.ReduceOp.SUM, async_op=True)
self.handles.append((handle, param))
return hook稍后,我们等待所有句柄完成收集所有归约操作(梯度的求和),然后除以word_size(GPU设备的数量)。
# Block until all outstanding gradient all‑reduces have completed."""
for work, param in self.handles:
work.wait()
param.grad.div_(self.world_size)这允许重叠计算:在NCCL核心通过单独的CUDA流聚合前一层梯度的同时,计算下一层的梯度。
该实现详细版本融合了重叠计算的逻辑。
class DDPOverlap(nn.Module):
"""
A minimal Distributed Data‑Parallel wrapper that overlaps gradient communication with the
computation of the backward pass by immediately launching an asynch `all_reduce` on each
parameter’s gradient as soon as it is produced.
"""
def __init__(self, module: nn.Module):
super().__init__()
self.module = module
self.handles: list[tuple[dist.Work, torch.nn.Parameter]] = []
self.world_size = dist.get_world_size()
# Broadcast parameters from rank 0 to all other ranks
for p in self.module.parameters():
dist.broadcast(p.data, src=0, async_op=False)
# Register post-accumulate gradient hook for each parameter
def make_hook(param: torch.nn.Parameter):
def hook(*_: torch.Tensor):
handle = dist.all_reduce(param.grad, op=dist.ReduceOp.SUM, async_op=True)
self.handles.append((handle, param))
return hook
for p in self.module.parameters():
if p.requires_grad:
p.register_post_accumulate_grad_hook(make_hook(p))
def forward(self, *args, **kwargs):
return self.module(*args, **kwargs)
def finish_gradient_synchronization(self) -> None:
"""Block until all outstanding gradient all‑reduces have completed."""
for work, param in self.handles:
work.wait()
param.grad.div_(self.world_size)
self.handles.clear()反向传播和通信是流水线化的。在步骤2中,我们一次性发送了所有梯度,这需要等待反向传播完成。我们将尝试通过将参数组织到桶中(减少总通信调用次数)并在每个桶的组成张量准备就绪时进行全规约(使我们能够重叠通信与计算),从而兼顾两者的优势。
步骤四、分桶 + 重叠
最终优化:将参数分组到桶中,当桶填满时启动异步全归约操作。
- 分桶机制能减少调用次数。
- 异步全归约将通信延迟隐藏在计算过程背后。
- 反向参数排序模拟反向传播遍历顺序。
模型参数按照预设桶大小分配到不同桶中,并根据参数逆序注册梯度钩子——因为梯度计算通常从最后一层向第一层推进(除非存在分支结构或复杂模型架构)。
# (Reverse order to mimic backward pass order of grad computation)
buckets = assign_parameters_to_buckets(model.parameters(), bucket_size)
for each parameter bucket:
register a hook so that:
when all grads in the bucket are ready:
flatten them
launch async all-reduce
mark this bucket as "pending"
#After backward() is done
for each pending bucket:
wait for the async all-reduce to finish
average the results
unflatten back into grads上述代码展示了该思想的核心。在实际应用中,我们需要管理桶的状态(跟踪有多少梯度已准备就绪、存储句柄、张量的扁平化/反扁平化等操作)。以下是一个实现了这些功能的精简PyTorch实现。
class DDPOverlapBucket(nn.Module):
"""
bucketed, overlap DDP wrapper that:
• broadcasts params once
• groups params into buckets
• launches async all-reduce when a bucket’s grads are ready
• waits/unflattens/averages at sync()
"""
def __init__(self, module: nn.Module, bucket_size_mb: float = 25.0):
super().__init__()
self.module = module
self.world_size = dist.get_world_size()
# --- Broadcast initial parameters from rank 0 ---
for p in self.module.parameters():
dist.broadcast(p.data, src=0)
# --- Build buckets (fixed order, sized by num elements) ---
dtype = next(self.module.parameters()).dtype
bytes_per_param = dtype.itemsize
bucket_cap = int(bucket_size_mb * 1024**2 / bytes_per_param)
self.buckets = [] # each: {"params": [...], "need": int, "ready": int, "handle": None, ...}
cur = {"params": [], "need": 0, "ready": 0, "handle": None,
"flat": None, "grads": None} # bucket state
# reverse order ≈ backward visitation order
for p in reversed(list(self.module.parameters())):
if not p.requires_grad:
continue
n = p.numel()
if cur["need"] > 0 and cur["need"] + n > bucket_cap:
self.buckets.append(cur)
cur = {"params": [], "need": 0, "ready": 0, "handle": None,
"flat": None, "grads": None} # bucket state zero out after it is filled
cur["params"].append(p)
cur["need"] += n
if cur["need"] > 0: # add the last bucket
self.buckets.append(cur)
# mark each param with its bucket index and add a post-accumulate hook
for b_idx, bucket in enumerate(self.buckets):
for p in bucket["params"]:
p._bucket_idx = b_idx # simple tag
p.register_post_accumulate_grad_hook(self._make_hook(p))
# track pending buckets to finalize at sync()
self._pending = []
def _make_hook(self, param: torch.nn.Parameter):
def hook(*_):
b = self.buckets[param._bucket_idx]
b["ready"] += param.numel() # number of grads in this bucket that are ready to be all-reduced
# If the whole bucket's grads are now ready → flatten + async all-reduce
if b["ready"] == b["need"]:
grads = [p.grad for p in b["params"] if p.grad is not None]
if len(grads) == 0:
# reset for next iteration and skip
b["ready"] = 0
return
flat = torch._utils._flatten_dense_tensors(grads)
handle = dist.all_reduce(flat, op=dist.ReduceOp.SUM, async_op=True)
# remember what to unflatten into and the handle to wait on
b["grads"] = grads
b["flat"] = flat
b["handle"] = handle
self._pending.append(b)
# reset ready counter for next iteration
b["ready"] = 0
return hook
def forward(self, *a, **kw):
return self.module(*a, **kw)
@torch.no_grad()
def finish_gradient_synchronization(self):
"""
Wait for in-flight all-reduces, average, and scatter back to .grad tensors.
Call once per iteration AFTER loss.backward() and BEFORE optimizer.step().
"""
for b in self._pending:
b["handle"].wait()
b["flat"].div_(self.world_size)
unflat = torch._utils._unflatten_dense_tensors(b["flat"], b["grads"])
for g_dst, g_src in zip(b["grads"], unflat):
g_dst.copy_(g_src)
# clear transient state
b["handle"] = None
b["flat"] = None
b["grads"] = None
self._pending.clear()当一个桶“满”时:
- 扁平化 → 异步全规约 → 随后解扁平化并分散回传。
- 通信与剩余的反向计算重叠。
这本质上就是PyTorch DDP当前的工作原理:梯度分桶 + 重叠优化
三、为何这很重要
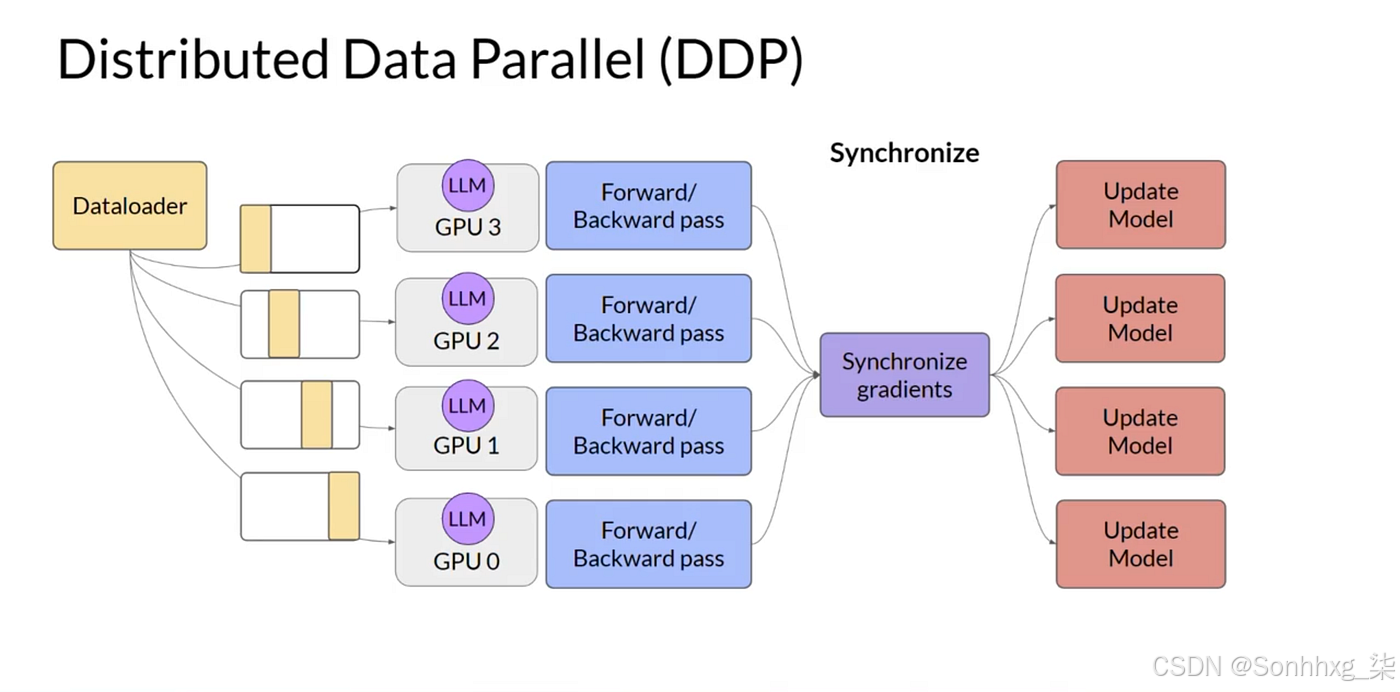
- 朴素DDP:正确但低效。
- 扁平化处理:减少通信调用但仍为串行。
- 重叠操作:掩盖延迟但存在过多细碎操作。
- 分桶+重叠:兼顾两者优势,可扩展至超大模型。
四、梯度累积(进一步优化)
有时我们希望模拟比GPU内存能容纳的更大批次的训练。诀窍是在同步和优化器更新之前,通过多个小批次累积梯度。
在上述最小化实现中,可以简单地延迟调用finish_gradient_synchronization(),直到经过一定数量的小批次。这样,梯度会在每个GPU上持续本地累积,而我们只需为每个"有效批次"执行一次昂贵的all_reduce操作。
在PyTorch官方的DistributedDataParallel中,这是通过no_sync上下文管理器实现的。在no_sync代码块内,梯度会在无通信的情况下累积。退出该代码块后,下一次反向传播将执行梯度同步,从而产生与我们最小化实现相同的效果。
with ddp_model.no_sync():
for _ in range(accumulation_steps - 1):
loss = ddp_model(inputs).backward()
# gradients accumulate locally, no all_reduce
# Synchronization happens here
loss = ddp_model(inputs).backward()
optimizer.step()
optimizer.zero_grad()PyTorch的DDP并非魔法,而是一套精心调校的系统,其核心机制包括:
- 单次参数广播
- 梯度分桶管理(将梯度划分为可处理的数据块)
- 异步全量规约操作(实现通信与计算重叠)
五、Mini-DDP
但生产级DDP系统远不止于此。以下是实现规模化应用的关键优化策略:
先进的梯度桶分配策略 高效处理批标准化层及复杂模型架构 梯度压缩技术——采用低精度(FP16/8位)传输梯度或仅发送最大幅度更新以节省带宽 分片式/轻量级优化器——优化器状态可能非常庞大;采用类似ZeRO的方案将其分散到多个GPU上可保持内存使用可控 这些优化共同降低了通信成本和内存开销,使得DDP系统能够从桌面级的多GPU配置扩展到大规模GPU集群。