背景意义
研究背景与意义
焊接作为一种广泛应用于制造业和建筑行业的连接技术,其质量直接影响到结构的安全性和耐用性。随着工业自动化和智能制造的不断发展,焊接过程中的缺陷检测和质量控制变得愈发重要。传统的焊接缺陷检测方法主要依赖人工检查和经验判断,这不仅耗时耗力,而且容易受到人为因素的影响,导致检测结果的不准确性。因此,开发一种高效、准确的焊接缺陷检测系统,成为了行业内亟待解决的问题。
近年来,深度学习技术的迅猛发展为图像处理和缺陷检测提供了新的解决方案。尤其是基于卷积神经网络(CNN)的目标检测和分割模型,如YOLO(You Only Look Once)系列,因其在实时性和准确性方面的优势,逐渐成为焊接缺陷检测领域的研究热点。YOLOv8作为YOLO系列的最新版本,结合了多种先进的深度学习技术,具备更强的特征提取能力和更快的推理速度,为焊接缺陷的自动化检测提供了新的可能性。
本研究旨在基于改进的YOLOv8模型,构建一个高效的焊接缺陷分割系统。该系统将利用一个包含1100幅图像的焊接缺陷数据集,数据集中涵盖了三类焊接缺陷:焊接裂纹(CRACK-WELDING)、良好焊接(GOOD-WELDING)和焊接孔洞(PORES-WELDING)。通过对这些数据的深入分析和处理,研究将重点探讨如何利用YOLOv8模型进行实例分割,以实现对不同类型焊接缺陷的精准识别和定位。
在此背景下,研究的意义主要体现在以下几个方面:首先,基于YOLOv8的焊接缺陷分割系统能够大幅提高焊接质量检测的效率和准确性,减少人工检测的工作量和误差,进而提升焊接产品的整体质量。其次,该系统的开发将为焊接行业提供一种新的智能化解决方案,推动焊接技术的现代化和自动化进程,符合当前工业4.0的趋势。此外,通过对焊接缺陷的深入研究和数据集的构建,能够为后续相关领域的研究提供宝贵的数据支持和理论基础,促进焊接缺陷检测技术的进一步发展。
综上所述,基于改进YOLOv8的焊接缺陷分割系统的研究,不仅具有重要的理论价值,还有着广泛的应用前景。通过将深度学习技术与焊接缺陷检测相结合,能够有效提升焊接质量控制的智能化水平,为行业的可持续发展提供有力支持。随着研究的深入,期待该系统能够在实际应用中发挥重要作用,为焊接行业的安全与质量保障贡献力量。
图片效果
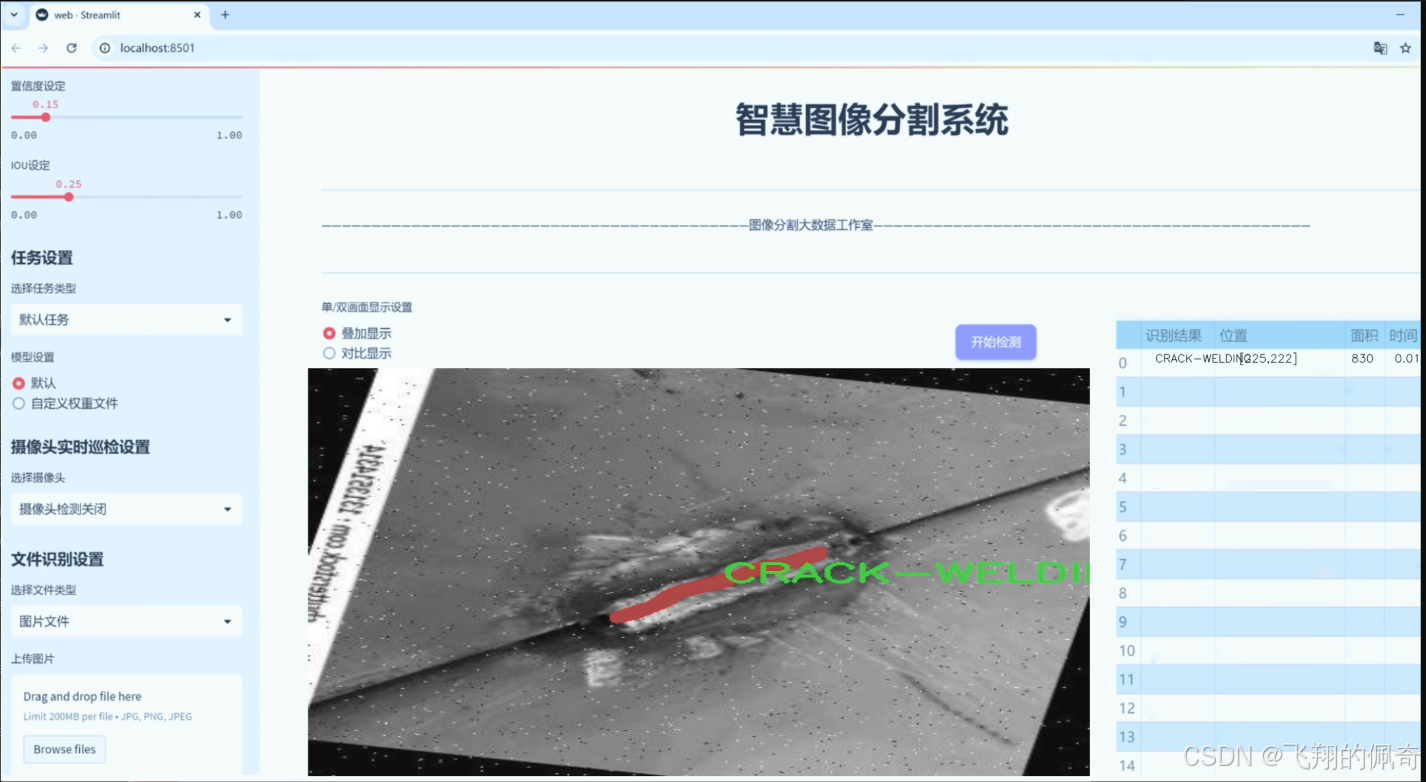
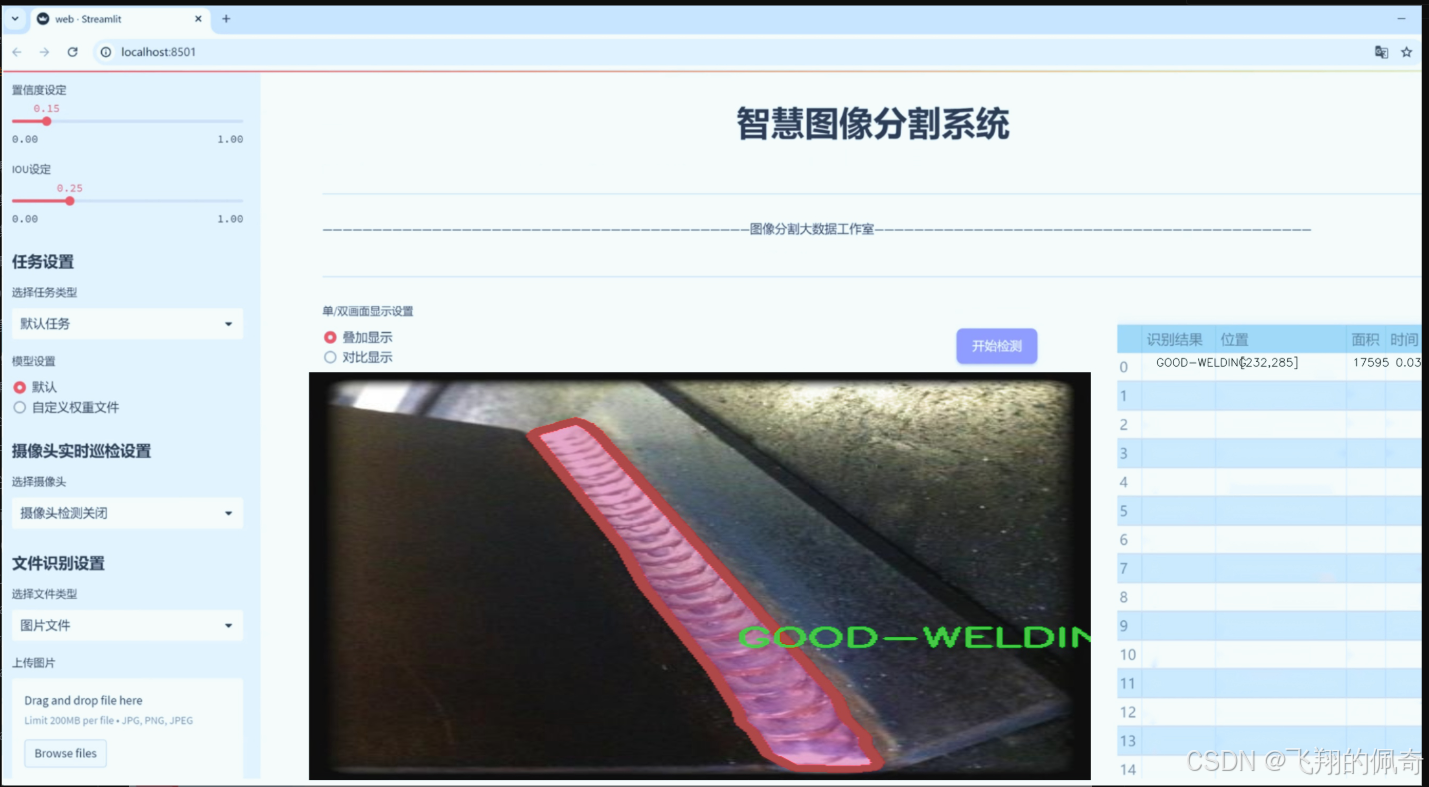
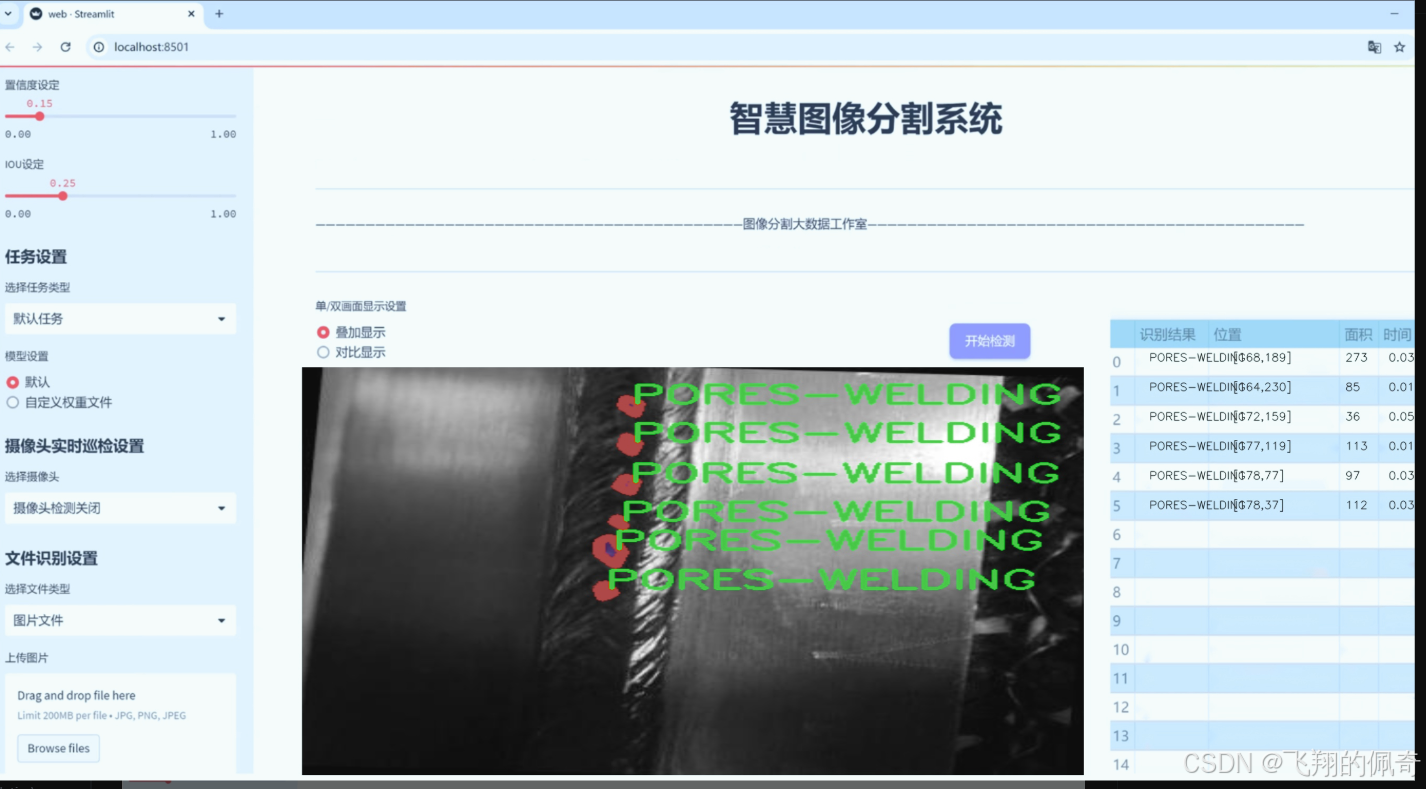
数据集信息
数据集信息展示
在焊接工艺中,焊接缺陷的检测与分割是确保结构完整性和安全性的重要环节。为此,我们构建了一个名为“SOLDADURA”的数据集,旨在为改进YOLOv8-seg模型提供高质量的训练数据,以实现焊接缺陷的精确分割。该数据集包含了多种焊接缺陷的图像,涵盖了焊接过程中可能出现的主要问题,具体包括三类焊接缺陷:裂纹焊接(CRACK-WELDING)、良好焊接(GOOD-WELDING)和气孔焊接(PORES-WELDING)。这些类别的选择基于焊接行业的实际需求,旨在为焊接质量的评估提供全面的支持。
数据集中的每一类焊接缺陷都经过精心标注,确保了图像的准确性和一致性。裂纹焊接类包含了多种不同类型的裂纹,涵盖了从微小裂纹到较大裂纹的多种情况,这些裂纹可能会影响焊接接头的强度和耐久性。良好焊接类则代表了理想的焊接状态,作为对比样本,帮助模型学习到何为正常的焊接质量。气孔焊接类则主要集中在焊接过程中由于气体释放而形成的小孔,这些气孔可能会导致焊接接头的强度下降,进而影响整体结构的安全性。
数据集的构建过程包括了多种焊接工艺的图像采集,确保了数据的多样性和代表性。图像来源于不同的焊接场景,包括工厂生产线、实验室测试以及现场施工等,涵盖了不同的焊接材料和技术。这种多样性使得“SOLDADURA”数据集不仅能够有效反映焊接缺陷的实际情况,还能提高模型在不同环境下的泛化能力。
在数据预处理阶段,我们对图像进行了标准化处理,以确保输入到YOLOv8-seg模型中的数据具有一致的尺寸和格式。此外,为了增强模型的鲁棒性,我们还应用了数据增强技术,包括随机裁剪、旋转、翻转等操作,从而生成更多的训练样本。这些增强样本不仅丰富了数据集的内容,还提高了模型对不同焊接缺陷的识别能力。
通过使用“SOLDADURA”数据集,我们期望能够训练出一个高效的焊接缺陷分割系统,该系统能够准确识别和分割出焊接缺陷区域,从而为焊接质量的自动检测提供支持。最终,我们希望该系统能够在实际应用中帮助焊接工程师快速识别焊接缺陷,提高焊接质量,降低安全隐患。数据集的设计与构建不仅为YOLOv8-seg模型的训练提供了坚实的基础,也为焊接行业的智能化发展贡献了一份力量。




核心代码
以下是经过简化和注释的核心代码部分:
import torch
from torch import nn
from typing import List
class Sam(nn.Module):
“”"
Sam (Segment Anything Model) 是一个用于对象分割任务的模型。它使用图像编码器生成图像嵌入,并使用提示编码器对各种输入提示进行编码。然后,这些嵌入被掩码解码器用于预测对象掩码。
“”"
# 掩码预测的阈值
mask_threshold: float = 0.0
# 输入图像的格式,默认为 'RGB'
image_format: str = 'RGB'
def __init__(
self,
image_encoder: nn.Module, # 图像编码器,用于将图像编码为嵌入
prompt_encoder: nn.Module, # 提示编码器,用于编码输入提示
mask_decoder: nn.Module, # 掩码解码器,用于从图像嵌入和提示中预测掩码
pixel_mean: List[float] = (123.675, 116.28, 103.53), # 图像归一化的均值
pixel_std: List[float] = (58.395, 57.12, 57.375) # 图像归一化的标准差
) -> None:
"""
初始化 Sam 类,以从图像和输入提示中预测对象掩码。
参数:
image_encoder (nn.Module): 用于将图像编码为图像嵌入的基础网络。
prompt_encoder (nn.Module): 编码各种类型输入提示的模块。
mask_decoder (nn.Module): 从图像嵌入和编码提示中预测掩码的模块。
pixel_mean (List[float], optional): 输入图像的像素归一化均值,默认为 (123.675, 116.28, 103.53)。
pixel_std (List[float], optional): 输入图像的像素归一化标准差,默认为 (58.395, 57.12, 57.375)。
"""
super().__init__()
# 初始化图像编码器、提示编码器和掩码解码器
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
# 注册图像归一化的均值和标准差为模型的缓冲区
self.register_buffer('pixel_mean', torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer('pixel_std', torch.Tensor(pixel_std).view(-1, 1, 1), False)
代码说明:
类定义:Sam 类继承自 nn.Module,用于实现对象分割模型。
属性:
mask_threshold:用于掩码预测的阈值。
image_format:指定输入图像的格式。
初始化方法:
接收图像编码器、提示编码器和掩码解码器作为参数,并进行初始化。
pixel_mean 和 pixel_std 用于图像归一化,注册为模型的缓冲区,以便在训练和推理过程中使用。
这个程序文件定义了一个名为 Sam 的类,属于 Ultralytics YOLO 项目的一部分,主要用于对象分割任务。Sam 类继承自 PyTorch 的 nn.Module,这是构建神经网络模型的基础类。
在这个类中,首先定义了一些属性,包括 mask_threshold 和 image_format,分别用于设置掩膜预测的阈值和输入图像的格式(默认为 RGB)。此外,类中还包含了三个重要的组件:image_encoder、prompt_encoder 和 mask_decoder,它们分别用于将图像编码为嵌入、对输入提示进行编码以及从图像和提示嵌入中预测对象掩膜。
在初始化方法 init 中,构造函数接受三个参数:image_encoder、prompt_encoder 和 mask_decoder,这些参数是构建 Sam 类的核心组件。还可以选择性地传入用于图像归一化的均值和标准差,默认值分别为 (123.675, 116.28, 103.53) 和 (58.395, 57.12, 57.375)。
在初始化过程中,调用了父类的构造函数,并将传入的编码器和解码器组件赋值给相应的属性。同时,使用 register_buffer 方法注册了图像归一化所需的均值和标准差,这样这些值就会被包含在模型的状态字典中,但不会被视为模型的可训练参数。
总的来说,这个类的设计目的是为对象分割任务提供一个结构化的框架,通过组合不同的编码器和解码器来实现对图像中对象的精确分割。
12.系统整体结构(节选)
程序整体功能和构架概括
Ultralytics YOLO 项目是一个用于对象检测和分割的深度学习框架,旨在提供高效的模型训练和推理能力。该项目的整体架构由多个模块组成,每个模块负责特定的功能,形成一个完整的工作流。主要功能包括模型的验证、文件管理、环境检查、与 Triton 推理服务器的交互以及对象分割模型的实现。
模型验证:通过 val.py 文件,项目实现了对 YOLO NAS 模型的验证过程,确保模型的预测结果经过后处理,生成准确的检测框。
文件管理:files.py 提供了对文件和目录的操作功能,包括路径处理、文件大小计算等,简化了项目中的文件管理任务。
环境检查:checks.py 文件负责检查和验证项目所需的环境和依赖项,确保系统的兼容性和正确配置。
推理服务器交互:triton.py 文件实现了与 Triton 推理服务器的交互,使得用户可以方便地进行远程模型推理。
对象分割:sam.py 文件定义了一个用于对象分割的核心模型类,整合了图像编码、提示编码和掩膜解码的功能。
文件功能整理表
文件路径 功能描述
ultralytics/models/nas/val.py 实现 YOLO NAS 模型的验证过程,处理模型的预测结果并应用非极大值抑制。
ultralytics/utils/files.py 提供文件和目录的操作功能,包括路径处理、文件大小计算和工作目录管理。
ultralytics/utils/checks.py 检查和验证项目所需的环境和依赖项,确保系统的兼容性和正确配置。
ultralytics/utils/triton.py 实现与 Triton 推理服务器的交互,支持远程模型推理。
ultralytics/models/sam/modules/sam.py 定义对象分割模型的核心类,整合图像编码、提示编码和掩膜解码功能。
通过以上文件的协同工作,Ultralytics YOLO 项目能够高效地处理对象检测和分割任务,提供强大的模型训练和推理能力。
13.图片、视频、摄像头图像分割Demo(去除WebUI)代码
在这个博客小节中,我们将讨论如何在不使用WebUI的情况下,实现图像分割模型的使用。本项目代码已经优化整合,方便用户将分割功能嵌入自己的项目中。 核心功能包括图片、视频、摄像头图像的分割,ROI区域的轮廓提取、类别分类、周长计算、面积计算、圆度计算以及颜色提取等。 这些功能提供了良好的二次开发基础。
核心代码解读
以下是主要代码片段,我们会为每一块代码进行详细的批注解释:
import random
import cv2
import numpy as np
from PIL import ImageFont, ImageDraw, Image
from hashlib import md5
from model import Web_Detector
from chinese_name_list import Label_list
根据名称生成颜色
def generate_color_based_on_name(name):
…
计算多边形面积
def calculate_polygon_area(points):
return cv2.contourArea(points.astype(np.float32))
…
绘制中文标签
def draw_with_chinese(image, text, position, font_size=20, color=(255, 0, 0)):
image_pil = Image.fromarray(cv2.cvtColor(image, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(image_pil)
font = ImageFont.truetype(“simsun.ttc”, font_size, encoding=“unic”)
draw.text(position, text, font=font, fill=color)
return cv2.cvtColor(np.array(image_pil), cv2.COLOR_RGB2BGR)
动态调整参数
def adjust_parameter(image_size, base_size=1000):
max_size = max(image_size)
return max_size / base_size
绘制检测结果
def draw_detections(image, info, alpha=0.2):
name, bbox, conf, cls_id, mask = info[‘class_name’], info[‘bbox’], info[‘score’], info[‘class_id’], info[‘mask’]
adjust_param = adjust_parameter(image.shape[:2])
spacing = int(20 * adjust_param)
if mask is None:
x1, y1, x2, y2 = bbox
aim_frame_area = (x2 - x1) * (y2 - y1)
cv2.rectangle(image, (x1, y1), (x2, y2), color=(0, 0, 255), thickness=int(3 * adjust_param))
image = draw_with_chinese(image, name, (x1, y1 - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param) # 类别名称上方绘制,其下方留出空间
else:
mask_points = np.concatenate(mask)
aim_frame_area = calculate_polygon_area(mask_points)
mask_color = generate_color_based_on_name(name)
try:
overlay = image.copy()
cv2.fillPoly(overlay, [mask_points.astype(np.int32)], mask_color)
image = cv2.addWeighted(overlay, 0.3, image, 0.7, 0)
cv2.drawContours(image, [mask_points.astype(np.int32)], -1, (0, 0, 255), thickness=int(8 * adjust_param))
# 计算面积、周长、圆度
area = cv2.contourArea(mask_points.astype(np.int32))
perimeter = cv2.arcLength(mask_points.astype(np.int32), True)
......
# 计算色彩
mask = np.zeros(image.shape[:2], dtype=np.uint8)
cv2.drawContours(mask, [mask_points.astype(np.int32)], -1, 255, -1)
color_points = cv2.findNonZero(mask)
......
# 绘制类别名称
x, y = np.min(mask_points, axis=0).astype(int)
image = draw_with_chinese(image, name, (x, y - int(30 * adjust_param)), font_size=int(35 * adjust_param))
y_offset = int(50 * adjust_param)
# 绘制面积、周长、圆度和色彩值
metrics = [("Area", area), ("Perimeter", perimeter), ("Circularity", circularity), ("Color", color_str)]
for idx, (metric_name, metric_value) in enumerate(metrics):
......
return image, aim_frame_area
处理每帧图像
def process_frame(model, image):
pre_img = model.preprocess(image)
pred = model.predict(pre_img)
det = pred[0] if det is not None and len(det)
if det:
det_info = model.postprocess(pred)
for info in det_info:
image, _ = draw_detections(image, info)
return image
if name == “main”:
cls_name = Label_list
model = Web_Detector()
model.load_model(“./weights/yolov8s-seg.pt”)
# 摄像头实时处理
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
......
# 图片处理
image_path = './icon/OIP.jpg'
image = cv2.imread(image_path)
if image is not None:
processed_image = process_frame(model, image)
......
# 视频处理
video_path = '' # 输入视频的路径
cap = cv2.VideoCapture(video_path)
while cap.isOpened():
ret, frame = cap.read()
......
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻