一、TL;DR
- 为什么要做:传统的referring分割无法使用音频模态,本文提出Reference audio-visual Segmentation
- 本文怎么做:构建首个 Ref-AVS 基准数据集+通过充分利用多模态提示,将音频信息通过和文本融合作为载体,在时序上提供精准的分割
- 什么结果:在三个测试子集上进行定量与定性实验,证明结果有效
paper:https://www.ecva.net/papers/eccv_2024/papers_ECCV/papers/09443.pdf
code:https://github.com/GeWu-Lab/Ref-AVS
二、方法介绍
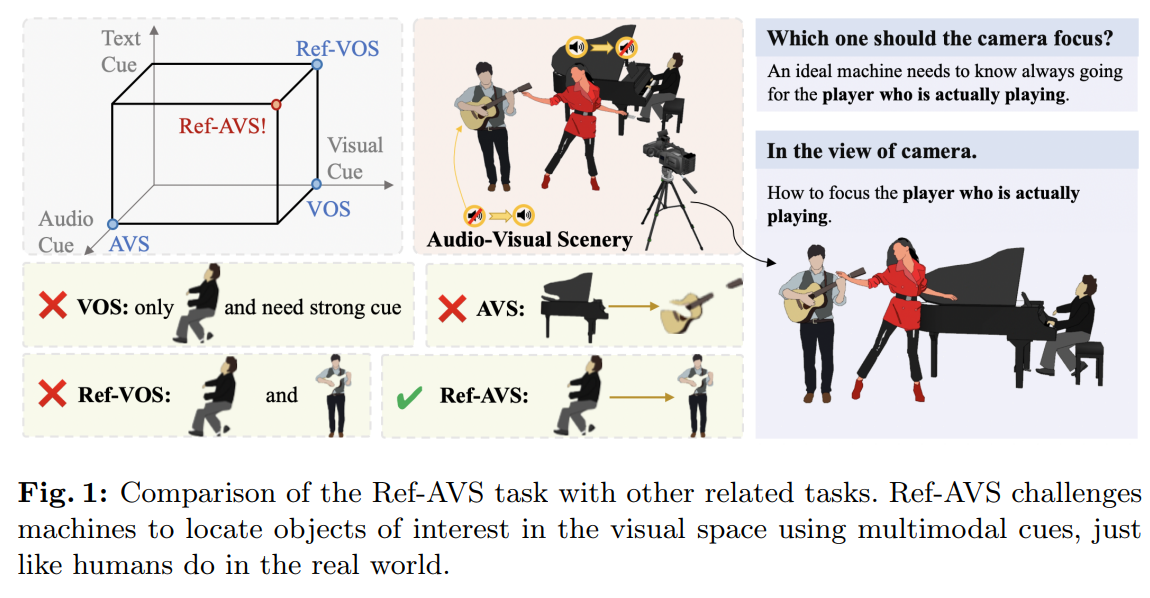
当前对指代分割(reference segmentation)的探索仍局限于较窄的场景。如图 1 的坐标系所示,当前针对不同模态的分割方法主要有三大研究方向:
基于视觉提示的方向:视频对象分割(Video Object Segmentation, VOS)以 “带标注的第一帧掩码” 为参考,引导后续视频帧中特定对象的分割。严重依赖 “第一帧的精准标注”导致在实际应用中既困难又耗时。
基于文本提示的方向:指代视频对象分割(Referring Video Object Segmentation, R-VOS)以 “属性描述语句” 为引导,探索分割能力。R-VOS 成功用自然语言替代了 VOS 中的掩码标注,提供了更易获取、更用户友好的参考形式,在 “更自然的动态音视频场景” 中定位对象的能力仍有限。
基于音频提示的方向:音视频分割(Audio-Visual Segmentation, AVS)以音频为引导,分割 “发出声音的对象”。该方法有效解决了 “动态音视频场景中对象定位” 的难题,但存在局限:无法聚焦于 “不发声的普通对象”,也难以有效定位 “特定感兴趣的对象”。
motivation:
- 现有研究尚无法让机器在 “自然动态音视频场景” 中定位感兴趣对象。
- 例如,如图 1 所示,机器如何长期精准定位 “真正在演奏乐器的人”?这需要机器推断 “哪件乐器在发声” 以及 “谁在演奏这件乐器”。
- 提出一项 “探索自然动态音视频场景中感兴趣对象定位可能性” 的任务具备实际应用价值
怎么做:
提出像素级分割任务-指代音视频分割(Ref-AVS):
- 要求网络密集预测 “每个像素是否对应给定的多模态提示描述语句”(该语句包含动态音视频信息)。
- 图 1 左上角清晰展示了 Ref-AVS 与现有任务的区别:它要求网络在 “更复杂、更立体的模态空间” 中精准定位并分割对象。
- 因此需要一个具备 “全面多模态理解能力” 的计算模型。
数据集:
本文引入Ref-AVS 基准测试集(Ref-AVS Bench):
- 首个 “基于指代多模态提示描述语句定位并分割感兴趣对象” 的基准。
- 考虑到现实音视频场景的复杂性,从 YouTube 收集了约 4000 个含音频的视频片段(其中 60% 以上为 “多源声音场景”),并由专家收集、验证了超过 20000 条指代描述语句 —— 这些语句通过多模态提示,描述不同动态音视频场景中的对象。
- 为评估模型在 “零样本场景需求增长” 下的泛化能力,本文设计了一个 “未见过的测试集(unseen test set)”。
贡献总结如下:
- 提出 Ref-AVS 这一具有挑战性的场景理解任务 —— 基于多模态提示描述语句分割感兴趣对象,并提供相应的 Ref-AVS 基准测试集,用于模型的训练与性能验证;
- 为 Ref-AVS 设计端到端框架 —— 通过跨模态 Transformer 高效处理多模态提示,为未来研究提供可行的基础框架;
- 开展大量实验,验证 “在视觉分割中考虑多模态提示” 的优势,同时证明本文方法在所有测试子集上的性能优越性。
三、核心框架-Ref-AVS 数据集
3.1 对象类别
为确保被指代对象的多样性,精心筛选了涵盖48 类可发声对象与3 类静态无声音对象的丰富类别体系。其中,可发声对象具体分类如下:
- 乐器类:20 个类别;
- 动物类:8 个类别;
- 机械类:15 个类别;
- 人类类:5 个类别。
针对人类这一特殊类别,考虑到其外貌、声音与动作的多样性,我们采用 “形态学分类思路”,基于年龄与性别将人类划分为 5 个细分类别。
3.2 视频筛选
在视频收集过程中,采用文献 [3, 46] 提出的技术(回头仔细看下),确保音视频片段与目标语义的一致性。每段视频均被剪辑为 10 秒时长。在人工收集阶段,刻意排除以下几类视频(详见附录):
- 含大量相同语义实例的视频;
- 经大量剪辑、频繁切换镜头的视频;
- 含合成特效的非真实场景视频。
为更贴近现实场景分布,重点筛选 “能丰富数据集场景多样性” 的视频:
- 尤其优先选择 “包含多对象交互” 的视频(如乐器、人类、交通工具等对象间的互动场景)。
除多样性外,我们还通过筛选确保数据集包含 “更高复杂度、更多对象数量” 的场景:
- 具体而言,56% 的视频包含 2 个及以上对象,13% 的视频包含 3 个及以上对象。
3.3 描述语句
描述语句的多样性是 Ref-AVS 数据集构建的核心要素之一。每条描述语句融合音频、视觉、时间三个维度的信息:
- 音频维度:包含音量、节奏等特征;
- 视觉维度:涵盖对象的外观、空间布局等属性;
- 时间维度:融入时序提示(如 “先发声的那个”“后出现的那个”)。
通过整合音、视、时三维信息,我们构建了丰富的描述语句库 —— 既准确反映多模态场景,又能满足用户 “精准指代” 的特定需求。图 2 展示了不同模态组合的描述语句示例。
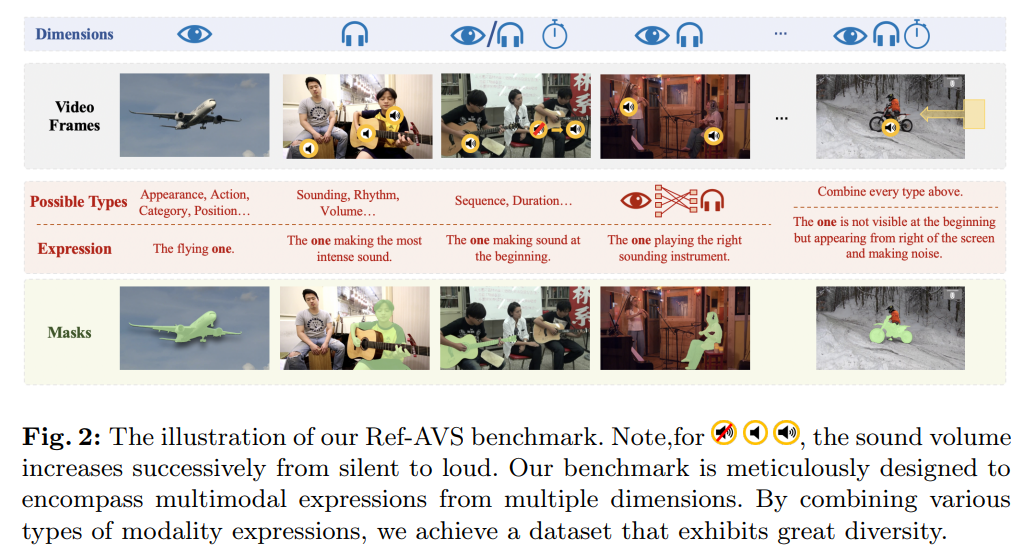
描述语句的准确性同样是核心关注点。我们遵循三条规则生成高质量描述语句:
- 唯一性:一条描述语句仅能指代一个对象,不可同时对应多个对象;
- 必要性:可使用复杂语句进行指代,但句中每个形容词需能 “缩小目标对象范围”,避免冗余、不必要的对象描述;
- 清晰性:部分描述模板涉及主观因素(如 “声音更大的那个”),仅当场景足够明确、无歧义时,才可使用此类语句。
除多样性与准确性外,我们还根据 “描述语句包含的提示数量” 对其难度进行分级:简单(easy)、中等(medium)、困难(hard)样本在数据集中的占比分别为 20%、60%、20%。这种难度分级可为 “课程学习(curriculum learning)” 等未来研究提供支持,详见补充材料。
3.4 分割掩码
我们将每段 10 秒视频均分为 10 个 1 秒片段,标注目标是获取每个片段 “首帧的掩码”。对于这些采样帧,真值标签为 “基于描述语句与多模态信息生成的二值掩码”,用于标识目标对象。
掩码生成流程如下:
- 关键帧手动筛选:为每段 10 秒视频手动选择 “目标对象清晰可见” 的关键帧(关键帧可位于视频开头、中间或结尾,取决于目标对象的最佳可见时刻);
- 自动分割与人工校验:利用 Grounding SAM 对关键帧进行分割与标注,随后通过人工检查与修正,生成关键帧中多个目标对象的掩码与标签;
- 跨帧跟踪补全:基于关键帧掩码,采用跟踪算法对前后帧中的目标对象进行跟踪,最终得到 10 帧序列中目标对象的完整掩码与标签。
3.5 数据集统计
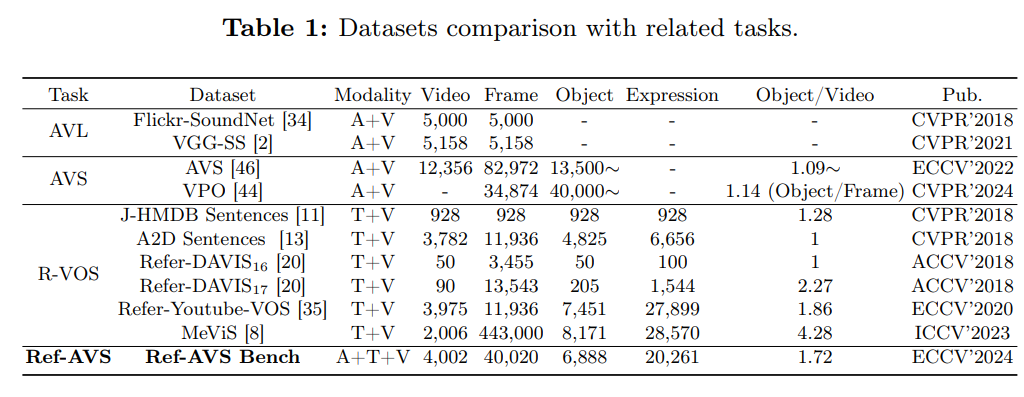
表 1 将 Ref-AVS 与其他主流音视频基准数据集进行对比,关键差异如下:
- 标注精度与数量:Flickr-SoundNet 与 VGG-SS仅提供 “(patch-level)边界框标注”,帧级标注量约 5000 个;而 Ref-AVS 提供像素级标注,标注数量显著更高;
- 场景复杂度:与 AVS 数据集相比,Ref-AVS视频的 “平均对象数量” 更高(约 1.72 个 / 视频),意味着包含更多 “多声源、多语义” 的复杂场景 —— 此类场景中,Ref-AVS 基准的价值尤为突出,因其能有效聚焦 “真正感兴趣的对象”;此外,Ref-AVS 的视频时长更统一,筛选流程更精细;
- 数据规模:相较于 R-VOS 任务的现有数据集 [8, 11, 13, 20, 35],Ref-AVS 在视频数量上保持优势,且包含更海量的 “对象、描述语句与复杂场景” 数据。
总体而言,Ref-AVS 数据集包含4000 段视频、20000 条描述语句与像素级标注,总时长超 11 小时。
3.6 数据集划分
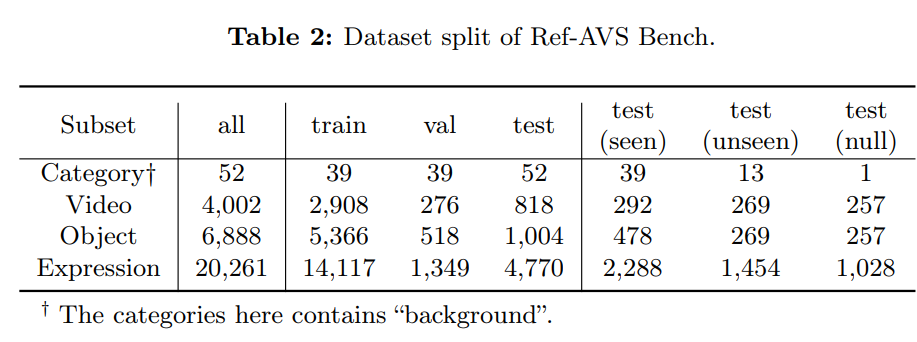
如表 2 所示,完整数据集分为三部分:训练集(2908 段视频)、验证集(276 段视频)、测试集(818 段视频)。其中,测试集的视频及其对应标注均经过资深标注人员的 “细致审核与重新标注”。
为全面评估模型在 Ref-AVS 任务上的性能,测试集进一步划分为三个功能不同的子集:
已见子集(Seen)
“已见子集” 包含的对象类别均在训练集中出现过,用于评估模型的 “基础性能” 与 “对熟悉类别对象的泛化能力”。
未见子集(Unseen)
说人话:做开集分割的
为应对 “开放世界场景下模型泛化能力” 的需求增长,专门构建 “未见子集” 以评估模型对 “未见过的音视频场景” 的适应能力。该子集的对象类别未在训练集中出现,但它们的 “超类别(如动物、交通工具)” 可能在训练集中存在 —— 旨在测试模型 “利用超类别知识,对新对象类别进行泛化” 的能力。
空指代子集(Null)
“空指代问题” 指 “描述语句所指代的对象在当前场景中不存在或不可见”。若模型能准确理解描述语句的引导,在空指代场景中不应分割任何对象 。基于此,我们设计 “空指代子集” 以测试模型的鲁棒性:该子集的对象类别虽在训练集中出现,但描述语句与场景完全不匹配 —— 视频帧中的所有对象均与指代内容无关,因此真值掩码为空,模型需避免分割任何对象。
4 基于多模态提示的描述语句增强
Expression Enhancing with Multimodal Cues:
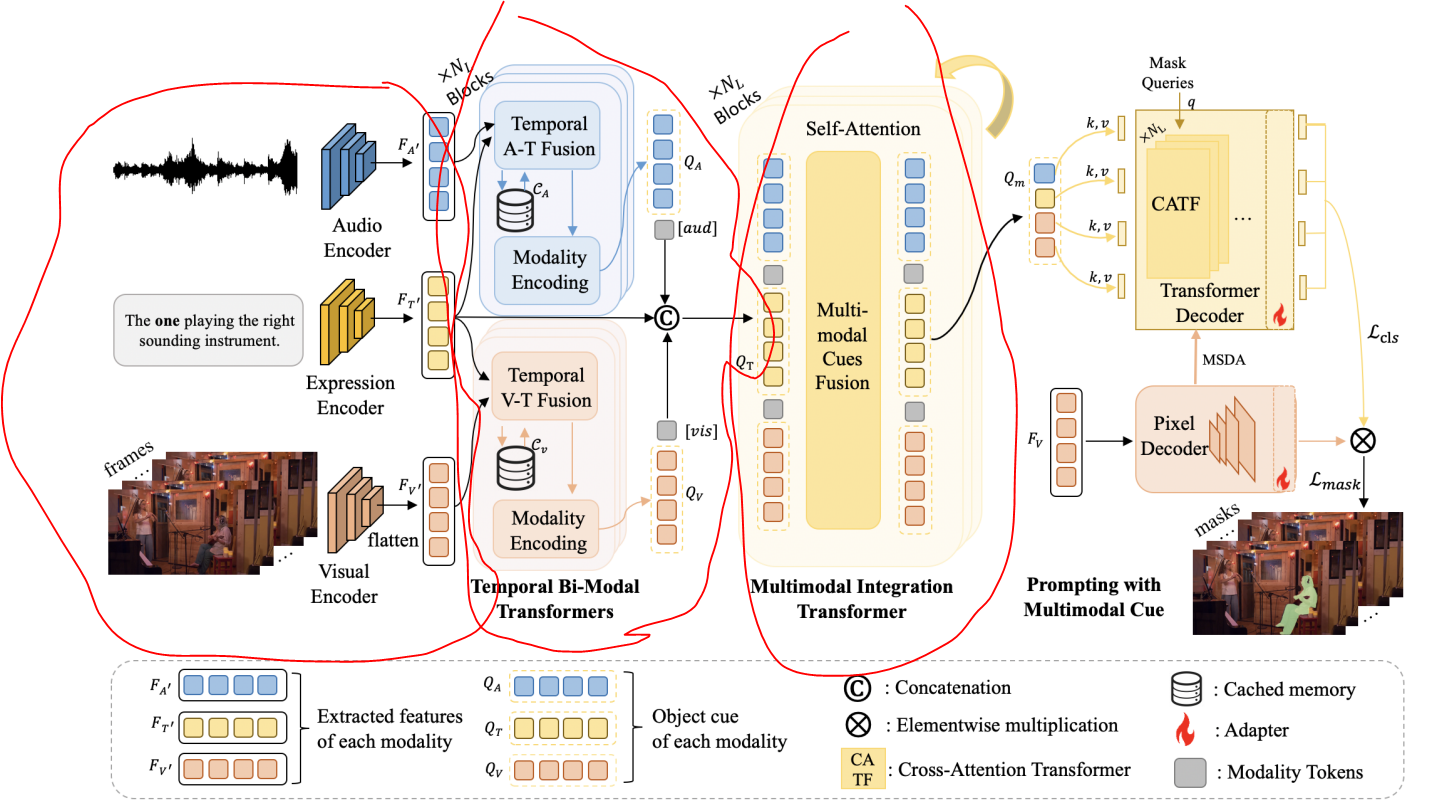
4.1 整体架构
Ref-AVS的目标:
- “利用多模态提示,在动态音视频场景中定位感兴趣对象”。
方法:
- 提出基于多模态提示的描述语句增强(EEMC)方法
- 核心思路是将 “动态音视频场景中的多模态信息” 融入 “含对应多模态提示的指代描述语句”,形成全面的多模态指代特征;
- 同时,通过注意力机制将 “多模态指代提示” 作为 “视觉基础模型的提示信号”,辅助完成最终的分割过程。
4.2 多模态表征
4.2.1 音频表示(Audio)
- 与视频处理方式类似,将音频输入按 1 秒间隔切分为片段。
- 音频表征F_A通过 VGGish 模型 编码得到(t为音频时长,单位为秒,且与视频帧数一致)。
- 音频表征通过离线方式提取,音频编码器不进行微调。
4.2.2 视觉表示(Visual)
- 从视频输入中按 1 秒间隔采样t帧,利用预训练的 Swin-base 模型提取视觉F_V。
- 视觉编码器不进行微调。
4.2.3 描述语句表示(Expression)
- 采用 RoBERTa 模型作为文本编码器,提取描述语句特征F_T。
- caption表征直接采用预训练模型的离线提取结果,不进行微调。
4.3 时序双模态 Transformer
4.3.1 时序A-T与V-T融合
该模块用于提取 “与caption语句相关的各模态信息”。首先,为便于后续多模态融合,我们对各模态特征进行预处理:


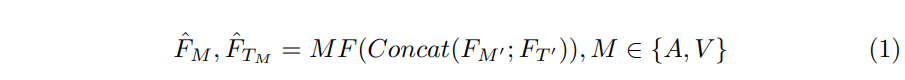
4.3.2 缓存记忆-Cached Memory
说人话:缓存历史时序上的特征均值作为时序信息

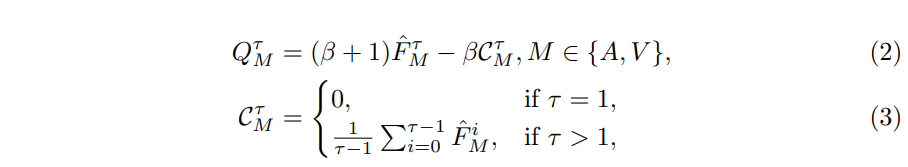

4.3.3 模态编码-Modality Encoding
说人话:将不同模态引入标识token进行区分,然后自注意力得到新的token

4.4 基于多模态提示的引导(Prompting with Multimodal Cues)
说人话:从图上来看,使用全模态Qm+input-mask的query得到qQ新特征,再结合当前帧的视觉特征,就得到了新的mask输出

五、Experiments
5.1 实现细节
本文采用 Mask2Former作为视觉基础模型,提供常用的 “基于 Transformer 的分割解码器”。默认设置如下:
- 输入视频帧均缩放至 384×384 分辨率;
- 视觉特征维度为 [H=64, W=64, d_V=256],为降低计算成本,采用 8 倍下采样;
- 音频特征从单声道波形中提取,维度 d_A=128;
- 文本特征维度为 [L=25, d_T=768](L 为描述语句长度);
- 为统一处理,将所有模态的特征维度均映射至 d_V;
- 超参数 β 默认设为 1;
- “时序双模态 Transformer”“多模态整合 Transformer” 与 “交叉注意力 Transformer(CATF)” 的 Transformer 层数(N_L)默认均设为 4;
- 掩码查询数量(N_q)固定为 100。
5.2 评价指标
为全面评估 Ref-AVS 方法的性能,采用以下指标:
- 交并比(Jaccard Index, J)与F 分数(F-score, F):作为核心性能指标,用于衡量分割结果与真值的匹配度;
- 空指代指标(S):仅用于 “空指代测试集”,评估模型对描述语句引导的遵循能力。S 的计算方式为 “预测掩码面积与背景面积比值的平方根”——S 值越高,表明预测掩码占背景的比例越大,意味着模型对描述语句的精准引导能力越弱。
5.3 定量结果
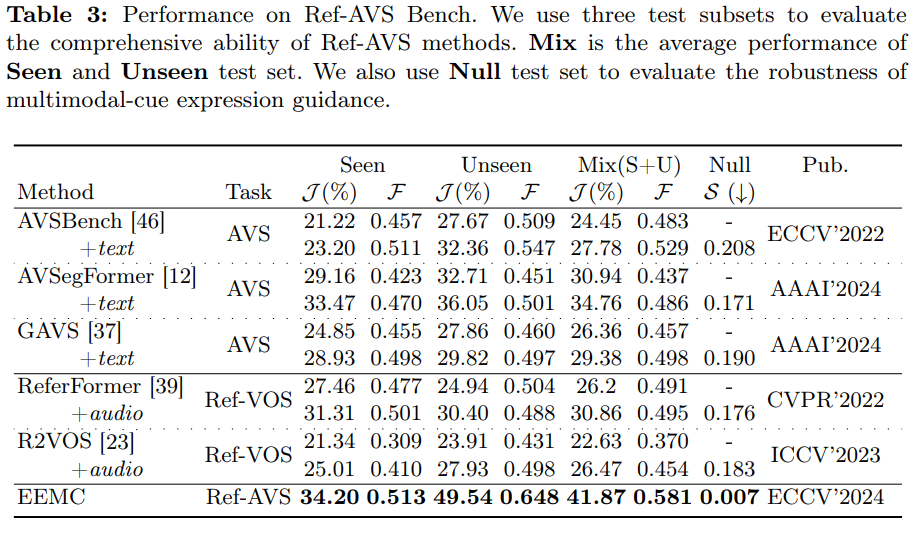
在 Ref-AVS 基准上,我们将本文方法与相关领域的现有方法进行对比,关键结果如下:
已见测试集(Seen):本文方法表现显著优于其他方法。简单的模态融合不足以解决 Ref-AVS 任务中 “多模态提示理解” 的难题;而本文方法未直接融合音视频信息,而是选择 “文本表示” 作为多模态信息的载体 —— 因其包含与 “当前音视频环境” 相关的丰富语义与提示,故能更有效利用多模态信息。
未见测试集(Unseen)与空指代测试集(Null):为验证模型的泛化能力与 “多模态提示遵循能力”,我们在这两个子集上进行测试:
- Unseen测试集:本文方法仍保持领先 —— 原因在于我们以 “具有高度抽象语义能力的文本” 作为多模态信息载体,而非直接融合音视频信息,因此生成的多模态提示能提供更稳健的语义引导;
- Null测试集:本文方法在所有方法中表现最优,表明模型能较精准地感知多模态提示,避免在 “无目标对象” 场景中错误分割。
5.4 定性结果
我们在 Ref-AVS 基准的测试集上可视化分割掩码,并与 AVSegFormer(AVS 任务方法)、ReferFormer(R-VOS 任务方法)进行对比(如图 4 所示)。从定性结果可观察到:

- AVSegFormer 与 ReferFormer 均无法精准分割 “描述语句所指向的对象”:
- AVSegFormer:难以完全理解描述语句,倾向于直接分割 “声源对象”。例如左下角样本中,该方法错误分割吸尘器,而非描述语句指向的 “男孩”;
- ReferFormer:无法充分理解音视频场景,易出现语义误判。例如右上角样本中,该方法误将 “学步儿童” 识别为 “钢琴演奏者”;
- 本文 Ref-AVS 方法:具备 “同时处理多模态描述语句与场景” 的优势,能准确解读用户指令,分割出目标对象。
5.5 消融实验
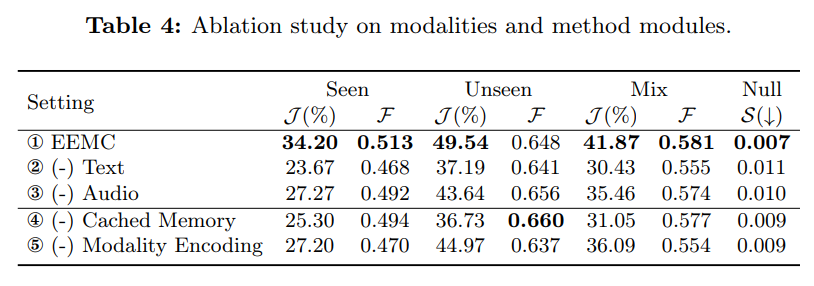
为验证 “音频、文本双模态信息” 对 Ref-AVS 任务的影响,以及本文方法各模块的有效性,我们开展消融实验,结果如表 4 所示:
5.5.1 双模态信息的影响
- 移除文本信息(设置②):J 值下降 11.44%,F 值下降 2.60%,性能降幅显著;
- 移除音频信息(设置③):J 值下降 6.41%,F 值下降 0.70%,降幅远小于移除文本的情况。
这一现象的核心原因是:文本信息作为 “指代源” 具有清晰性与直接性;而仅依赖音频信息时,模型易忽略 “指代内容”,转而聚焦于 “视觉上与发声行为相关的对象”,导致分割偏差。
5.1.2 各模块的有效性
- 缓存记忆(Cached Memory):用于捕捉时序域内的显著变化;
- 模态编码(Modality Encoding):用于从多模态提示中提取 “更独特、更全面的特征”,增强模态感知能力。
表 4 中 “设置④(移除缓存记忆)” 与 “设置⑤(移除模态编码)” 的结果表明,这两个模块的移除会导致性能下降,验证了它们对模型性能的提升作用。