0.创建虚拟环境
# 创建虚拟环境
conda create -n ppdet python=3.8 -y
conda activate ppdet
1.安装PaddlePaddle
飞桨PaddlePaddle-源于产业实践的开源深度学习平台
conda install paddlepaddle-gpu==2.3.2 cudatoolkit=11.6 -c https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/Paddle/ -c conda-forge
2.安装PaddleDetection
# 克隆PaddleDetection仓库
cd <path/to/clone/PaddleDetection>
git clone https://github.com/PaddlePaddle/PaddleDetection.git
#安装其他依赖
cd PaddleDetection
pip install -r requirements.txt
#编译安装paddledet
python setup.py install
3.测试安装
3.1建立数据集软连接
ln -s /home/cyp/datasets/hanfeng_coco hanfeng_coco
3.2快速验证
# 设置显卡
export CUDA_VISIBLE_DEVICES=0
# 验证安装
python tools/infer.py -c configs/ppyolo/ppyolo_r50vd_dcn_1x_coco.yml -o use_gpu=true weights=https://paddledet.bj.bcebos.com/models/ppyolo_r50vd_dcn_1x_coco.pdparams --infer_img=demo/000000014439.jpg
4.模型配置参数
4.1 数据配置文件
#configs/datasets/coco_instance.yml
# 数据评估类型
metric: COCO
# 数据集的类别数
num_classes: 3 # 类别数加1
# TrainDataset
TrainDataset:
!COCODataSet
# 图像数据路径,相对 dataset_dir 路径,os.path.join(dataset_dir, image_dir)
image_dir: train2017
# 标注文件路径,相对 dataset_dir 路径,os.path.join(dataset_dir, anno_path)
anno_path: annotations/instances_train2017.json
# 数据文件夹
dataset_dir: dataset/coco
# data_fields
data_fields: ['image', 'gt_bbox', 'gt_class', 'is_crowd']
EvalDataset:
!COCODataSet
# 图像数据路径,相对 dataset_dir 路径,os.path.join(dataset_dir, image_dir)
image_dir: val2017
# 标注文件路径,相对 dataset_dir 路径,os.path.join(dataset_dir, anno_path)
anno_path: annotations/instances_val2017.json
# 数据文件夹
dataset_dir: dataset/coco
TestDataset:
!ImageFolder
# 标注文件路径,相对 dataset_dir 路径,os.path.join(dataset_dir, anno_path)
anno_path: annotations/instances_val2017.json
4.2 优化器配置文件
# configs/solov2/base/optimizer_1x.yml
# 总训练轮数
epoch: 12
# 学习率设置
LearningRate:
# 默认为8卡训学习率
base_lr: 0.01
# 学习率调整策略
schedulers:
- !PiecewiseDecay
gamma: 0.1
# 学习率变化位置(轮数)
milestones: [8, 11]
- !LinearWarmup
start_factor: 0.1
steps: 1000
# 优化器
OptimizerBuilder:
# 优化器
optimizer:
momentum: 0.9
type: Momentum
# 正则化
regularizer:
factor: 0.0001
type: L2
4.3 数据读取配置文件
# configs/solov2/base/solov2_reader.yml
worker_num: 4
TrainReader:
sample_transforms:
- Decode: {}
- Poly2Mask: {}
- Resize: {interp: 1, target_size: [1024, 1280], keep_ratio: True}
- RandomFlip: {}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
- Gt2Solov2Target: {num_grids: [40, 36, 24, 16, 12],
scale_ranges: [[1, 96], [48, 192], [96, 384], [192, 768], [384, 2048]],
coord_sigma: 0.2}
batch_size: 4
shuffle: true
drop_last: true
EvalReader:
sample_transforms:
- Decode: {}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Resize: {interp: 1, target_size: [1024, 1280], keep_ratio: True}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
batch_size: 1
shuffle: false
drop_last: false
TestReader:
sample_transforms:
- Decode: {}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Resize: {interp: 1, target_size: [1024, 1280], keep_ratio: True}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
batch_size: 1
shuffle: false
drop_last: false
4.4模型配置文件
# configs/solov2/solov2_r101_vd_fpn_3x_coco.yml
_BASE_: [
'../datasets/coco_instance.yml',
'../runtime.yml',
'_base_/solov2_r50_fpn.yml',
'_base_/optimizer_1x.yml',
'_base_/solov2_reader.yml',
]
pretrain_weights: checkpoint/solov2_r50_fpn_3x_coco.pdparams
weights: output/solov2_r101_vd_fpn_3x_coco/model_final
epoch: 100
use_ema: true
ema_decay: 0.9998
ResNet:
depth: 101
variant: d
freeze_at: 0
return_idx: [0,1,2,3]
dcn_v2_stages: [1,2,3]
num_stages: 4
SOLOv2Head:
seg_feat_channels: 512
stacked_convs: 4
num_grids: [40, 36, 24, 16, 12]
kernel_out_channels: 256
solov2_loss: SOLOv2Loss
mask_nms: MaskMatrixNMS
dcn_v2_stages: [0, 1, 2, 3]
SOLOv2MaskHead:
mid_channels: 128
out_channels: 256
start_level: 0
end_level: 3
use_dcn_in_tower: True
LearningRate:
base_lr: 0.000125
schedulers:
- !PiecewiseDecay
gamma: 0.1
milestones: [85, 90]
- !LinearWarmup
start_factor: 0.
steps: 500
TrainReader:
sample_transforms:
- Decode: {}
- Poly2Mask: {}
- RandomResize: {interp: 1,
target_size: [[640, 1280], [672, 1280], [704, 1280], [736, 1280], [768, 1280], [800, 1280], [1024, 1280]],
keep_ratio: True}
- RandomFlip: {}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
batch_transforms:
- PadBatch: {pad_to_stride: 32}
- Gt2Solov2Target: {num_grids: [40, 36, 24, 16, 12],
scale_ranges: [[1, 96], [48, 192], [96, 384], [192, 768], [384, 2048]],
coord_sigma: 0.2}
batch_size: 4
shuffle: true
drop_last: true
4.5 运行配置文件
# configs/runtime.yml
use_gpu: true
use_xpu: false
log_iter: 50 # 修改打印信息的迭代次数
save_dir: output
snapshot_epoch: 1
print_flops: false
# Exporting the model
export:
post_process: True # Whether post-processing is included in the network when export model.
nms: True # Whether NMS is included in the network when export model.
benchmark: False # It is used to testing model performance, if set `True`, post-process and NMS will not be exported.
fuse_conv_bn: False
4.6 模型参数配置
# configs/solov2/base/solov2_r50_fpn.yml
architecture: SOLOv2
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/ResNet50_cos_pretrained.pdparams # 加载预训练模型
SOLOv2:
backbone: ResNet
neck: FPN
solov2_head: SOLOv2Head
mask_head: SOLOv2MaskHead
ResNet:
depth: 50
freeze_at: 0
return_idx: [0,1,2,3]
num_stages: 4
FPN:
out_channel: 256
SOLOv2Head:
seg_feat_channels: 512
stacked_convs: 4
num_grids: [40, 36, 24, 16, 12]
kernel_out_channels: 256
solov2_loss: SOLOv2Loss
mask_nms: MaskMatrixNMS
SOLOv2MaskHead:
mid_channels: 128
out_channels: 256
start_level: 0
end_level: 3
SOLOv2Loss:
ins_loss_weight: 3.0
focal_loss_gamma: 2.0
focal_loss_alpha: 0.25
MaskMatrixNMS:
pre_nms_top_n: 500
post_nms_top_n: 100
5.训练、评估、预测
5.1训练
边训练边测试 CPU需要约x小时(use_gpu=false),1080Ti GPU需要约x分钟
-c 参数表示指定使用哪个配置文件
-o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置),这里设置使用gpu
–eval 参数表示边训练边评估,最后会自动保存一个名为model_final.pdparams的模型
export CUDA_VISIBLE_DEVICES=0
python tools/train.py -c configs/solov2/solov2_r101_vd_fpn_3x_coco.yml --eval
5.2评估
评估 默认使用训练过程中保存的model_final.pdparams
-c 参数表示指定使用哪个配置文件
-o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
export CUDA_VISIBLE_DEVICES=0
python tools/eval.py -c configs/solov2/solov2_r101_vd_fpn_3x_coco.yml -o weights=output/solov2_r101_vd_fpn_3x_coco/model_final.pdparams
5.3预测
-c 参数表示指定使用哪个配置文件
-o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
–infer_img 参数指定预测图像路径
export CUDA_VISIBLE_DEVICES=0
python tools/infer.py -c configs/solov2/solov2_r101_vd_fpn_3x_coco.yml -o weights=output/solov2_r101_vd_fpn_3x_coco/model_final.pdparams --infer_img=demo/0580.bmp
5.4可视化
export CUDA_VISIBLE_DEVICES=0
python tools/train.py -c configs/solov2/solov2_r101_vd_fpn_3x_coco.yml --use_vdl=true --vdl_log_dir=vdl_dir/scalar
#使用如下命令启动VisualDL查看日志
visualdl --logdir vdl_dir/scalar/
6.预测部署
6.1导出模型
使用tools/export_model.py脚本导出模型以及部署时使用的配置文件,配置文件名字为infer_cfg.yml。模型导出脚本如下:
cd PaddleDetection
python tools/export_model.py -c configs/solov2/solov2_r101_vd_fpn_3x_coco.yml --output_dir=inference_model -o weights=output/solov2_r101_vd_fpn_3x_coco/model_final.pdparams
预测模型会导出到output_inference/yolov3_mobilenet_v1_roadsign目录下:
infer_cfg.yml
model.pdiparams
model.pdiparams.info
model.pdmodel
6.2模型部署
Step1: 下载源代码
git clone https://github.com/PaddlePaddle/PaddleDetection.git
其中C++预测代码在PaddleDetection/deploy/cpp 目录,该目录不依赖任何PaddleDetection下其他目录
deploy/cpp
|
├── src
│ ├── main.cc # 集成代码示例, 程序入口
│ ├── object_detector.cc # 模型加载和预测主要逻辑封装类实现
│ └── preprocess_op.cc # 预处理相关主要逻辑封装实现
|
├── include
│ ├── config_parser.h # 导出模型配置yaml文件解析
│ ├── object_detector.h # 模型加载和预测主要逻辑封装类
│ └── preprocess_op.h # 预处理相关主要逻辑类封装
|
├── docs
│ ├── linux_build.md # Linux 编译指南
│ └── windows_vs2019_build.md # Windows VS2019编译指南
│
├── build.sh # 编译命令脚本
│
├── CMakeList.txt # cmake编译入口文件
|
├── CMakeSettings.json # Visual Studio 2019 CMake项目编译设置
│
└── cmake # 依赖的外部项目cmake(目前仅有yaml-cpp)
Step2: 下载PaddlePaddle C++ 预测库 paddle_inference
PaddlePaddle C++ 预测库针对不同的CPU和CUDA版本提供了不同的预编译版本,请根据实际情况下载: C++预测库下载列表,解压后D:\projects\paddle_inference目录包含内容为:
paddle_inference
├── paddle # paddle核心库和头文件
|
├── third_party # 第三方依赖库和头文件
|
└── version.txt # 版本和编译信息
Step3: 安装配置OpenCV
- 在OpenCV官网下载适用于Windows平台的3.4.14版本
- 运行下载的可执行文件,将OpenCV解压至指定目录,如
D:\projects\opencv - 配置环境变量,如下流程所示(如果使用全局绝对路径,可以不用设置环境变量)
- 我的电脑->属性->高级系统设置->环境变量
- 在系统变量中找到Path(如没有,自行创建),并双击编辑
- 新建,将opencv路径填入并保存,如
D:\projects\opencv\build\x64\vc14\bin
Step4: 编译
Win10 + VS2019 + CMake3.17.0 + OpenCV3.4.14
新建Paddle_project_Project文件夹,将opencv-3.4.14,paddle_inference,PaddleDetection放下该文件夹
Padle_Project
├── opencv-3.4.14
├── paddle_inference
├── PaddleDetection
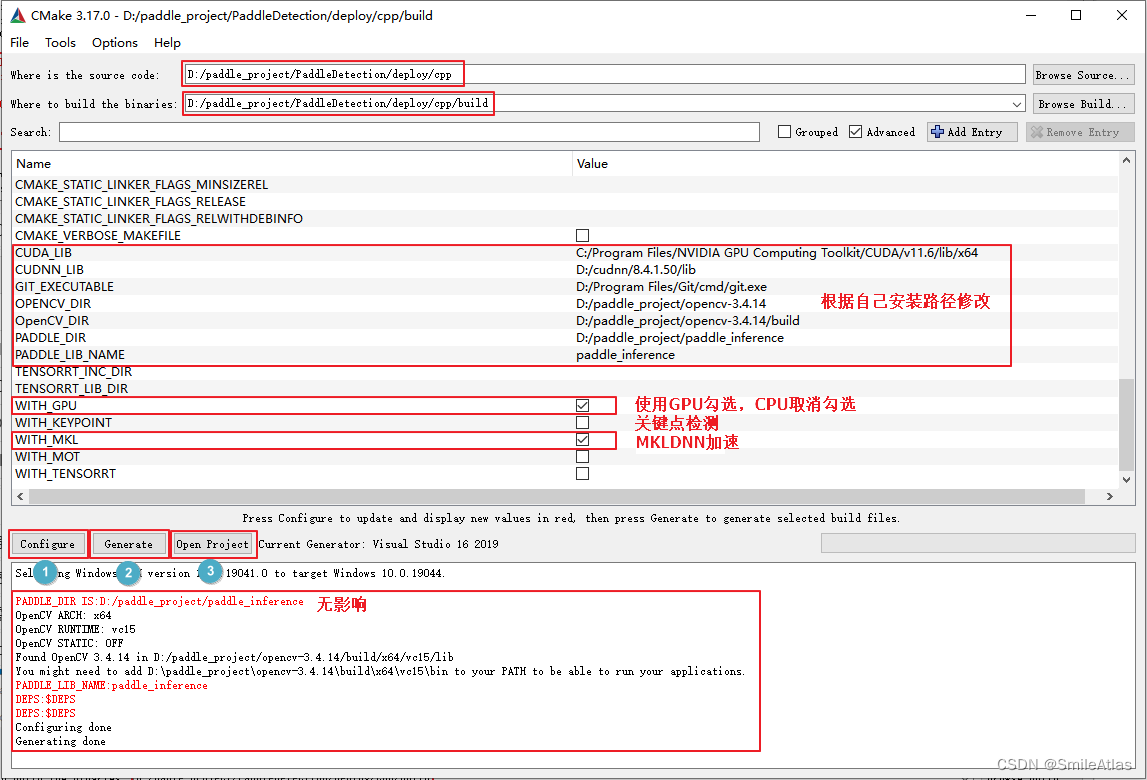
- 打开CMake,

- 点击Configure,选择
Visual Studio 16 2019,x64
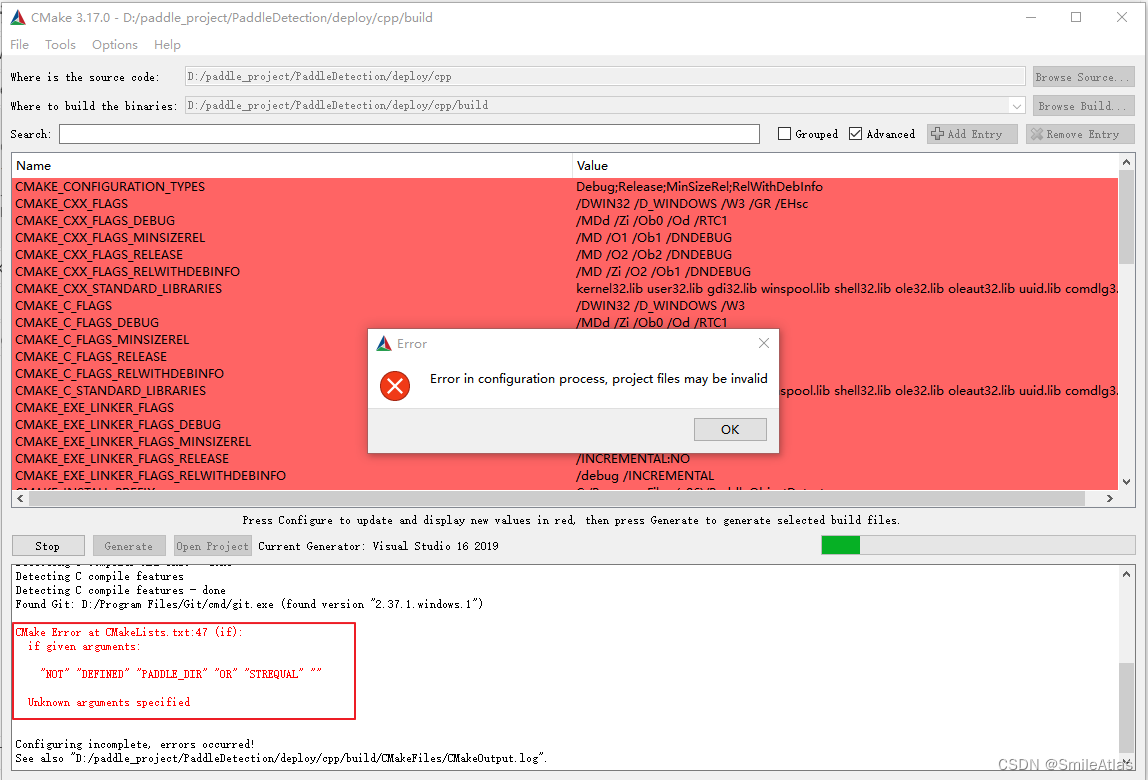
4.出现报错如下报错
5.需填写CUDA CUDNN OPENCV PADDLE的路径,根据自己的安装位置进行修改
| 参数名 | 含义 | 示例 |
|---|---|---|
| CUDA_LIB | CUDA的库路径 | C:/Program Files/NVIDIA GPU Computing Toolkit/CUDA/v11.6/lib/x64 |
| CUDNN_LIB | CUDNN的库路径 | D:/cudnn/8.4.1.50/lib |
| OPENCV_DIR | OpenCV的安装路径, | D:/paddle_project/opencv-3.4.14 |
| PADDLE_DIR | Paddle预测库的路径 | D:/paddle_project/paddle_inference |
| PADDLE_LIB_NAME | Paddle 预测库名称 | paddle_inference |
注意:
- 如果编译环境为CPU,需要下载
CPU版预测库,把WITH_GPU的勾去掉 - 如果使用的是
openblas版本,把WITH_MKL勾去掉 - 如无需使用关键点模型可以把
WITH_KEYPOINT勾去掉 - Windows环境下,
PADDLE_LIB_NAME需要设置为paddle_inference
5.依次按Configure、 Generate
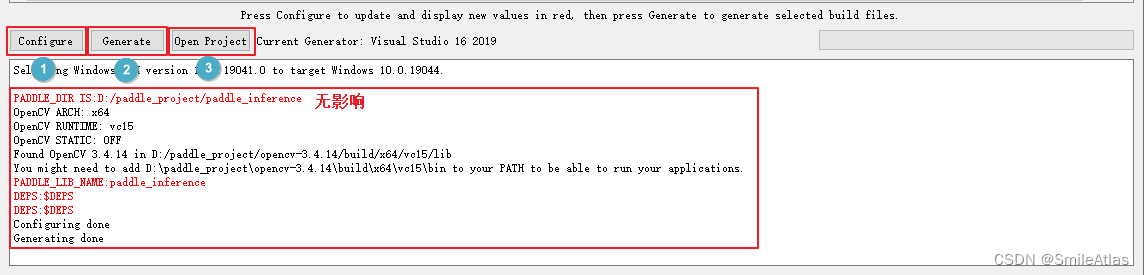
6. 用Visual Studio 16 2019打开cpp文件夹下的PaddleObjectDetector.sln,设置main为启动项,将编译模式设置为Release,点击生成->`全部生成
7.显示下图,编译成功

8. 完整CMAKE操作流程
Step5: 测试
1.经过编译后得到以下文件:
your_path/PaddleDetection/deploy/cpp/build/Release
├──libiomp5md.dll
├──main.exe
├──mkldnn.dll
├──mklml.dll
├──onnxruntime.dll
├──libiomp5md.dll
├──paddle_inference.dll
├──paddle2onnx.dll
2.使用6.1步导出的模型进行测试,文件放置如下:
your_path/PaddleDetection/deploy/cpp/build/Release
├──inference_model
├──├── solov2_r101_vd_fpn_3x_coco
├──├──├── infer_cfg.yml
├──├──├── model.pdiparams
├──├──├── model.pdiparams.info
├──├──├── model.pdiparams.info
├──├──├── model.pdmodel
├──0580.bmp
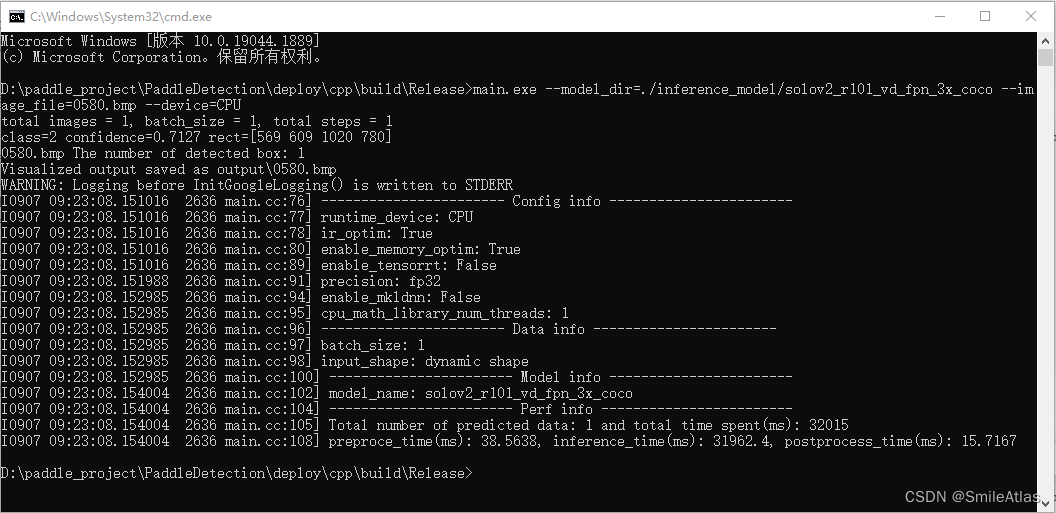
- 运行以下命令进行测试:
main.exe --model_dir=./inference_model/solov2_r101_vd_fpn_3x_coco --image_file=0580.bmp --device=CPU
输出结果:

可执行文件main即为样例的预测程序,其主要的命令行参数如下:
| 参数 | 说明 |
|---|---|
| –model_dir | 导出的检测预测模型所在路径 |
| –model_dir_keypoint | Option |
| –image_file | 要预测的图片文件路径 |
| –image_dir | 要预测的图片文件夹路径 |
| –video_file | 要预测的视频文件路径 |
| –camera_id | Option |
| –device | 运行时的设备,可选择CPU/GPU/XPU,默认为CPU |
| –gpu_id | 指定进行推理的GPU device id(默认值为0) |
| –run_mode | 使用GPU时,默认为paddle, 可选(paddle/trt_fp32/trt_fp16/trt_int8) |
| –batch_size | 检测模型预测时的batch size,在指定image_dir时有效 |
| –batch_size_keypoint | 关键点模型预测时的batch size,默认为8 |
| –run_benchmark | 是否重复预测来进行benchmark测速 | |
| –output_dir | 输出图片所在的文件夹, 默认为output | |
| –use_mkldnn | CPU预测中是否开启MKLDNN加速 |
| –cpu_threads | 设置cpu线程数,默认为1 |
| –use_dark | 关键点模型输出预测是否使用DarkPose后处理,默认为true |