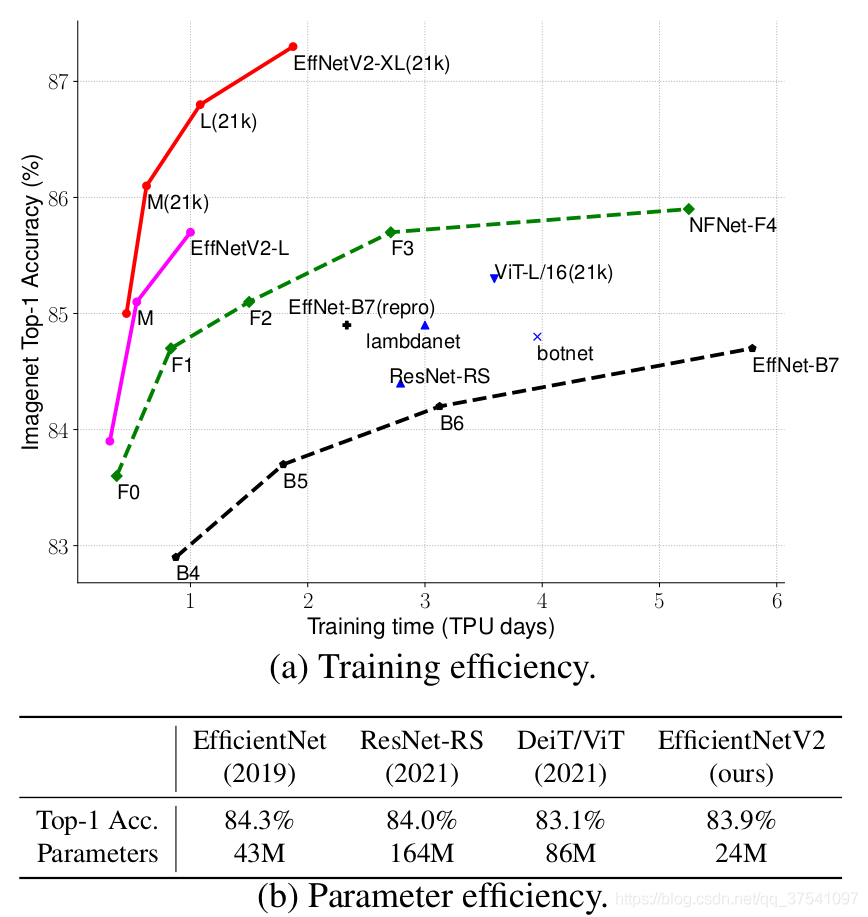
通过上图能够看出EfficientNetV2网络不仅Accuracy达到了当前的SOTA(State-Of-The-Art)水平,而且训练速度更快参数数量更少(比当前火热的Vision Transformer还要强)。EfficientNetV2-XL (21k)在ImageNet ILSVRC2012的Top-1上达到87.3%。在EfficientNetV1中作者关注的是准确率,参数数量以及FLOPs(理论计算量小不代表推理速度快),在EfficientNetV2中作者进一步关注模型的训练速度。
1.解决EfficientNetv1中存在的问题
1)训练图像的尺寸很大时,训练速度非常慢。 使用EfficientNet时发现当使用到B3(img_size=300)- B7(img_size=600)时基本训练不动,而且非常吃显存。通过下表可以看到,在Tesla V100上当训练的图像尺寸为380x380时,batch_size=24还能跑起来,当训练的图像尺寸为512x512时,batch_size=24时就报OOM(out of memory)了。针对这个问题一个比较好想到的办法就是降低训练图像的尺寸,之前也有一些文章这么干过。降低训练图像的尺寸不仅能够加快训练速度,还能使用更大的batch_size.

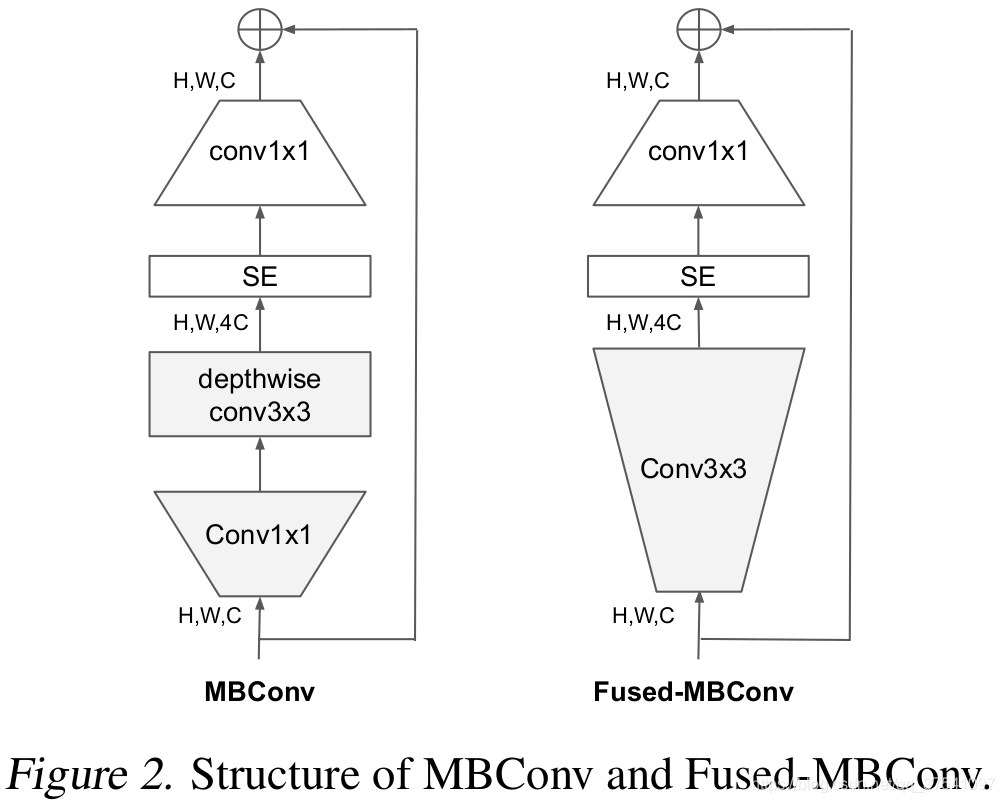
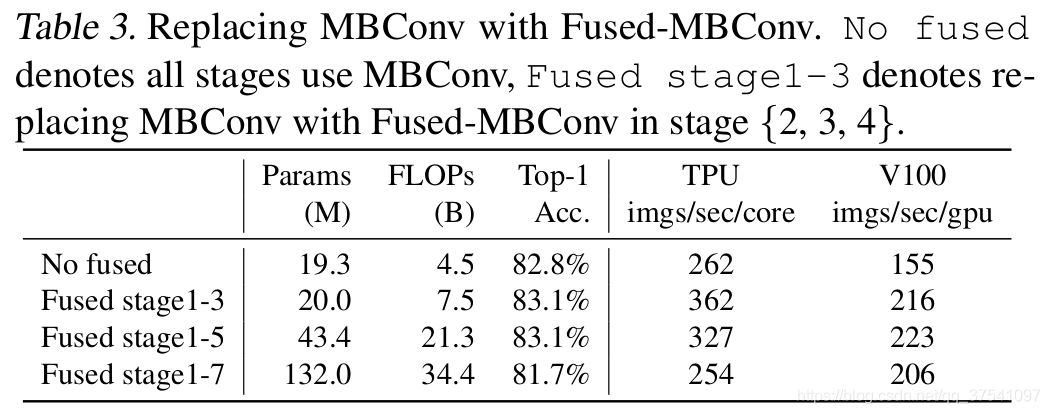
2)在网络浅层中使用Depthwise convolutions速度会很慢。 虽然Depthwise convolutions结构相比普通卷积拥有更少的参数以及更小的FLOPs,但通常无法充分利用现有的一些加速器(虽然理论上计算量很小,但实际使用起来并没有想象中那么快)。在近些年的研究中,有人提出了Fused-MBConv结构去更好的利用移动端或服务端的加速器。Fused-MBConv结构也非常简单,即将原来的MBConv结构主分支中的expansion conv1x1和depthwise conv3x3替换成一个普通的conv3x3,如图2所示。作者也在EfficientNet-B4上做了一些测试,发现将浅层MBConv结构替换成Fused-MBConv结构能够明显提升训练速度,如表3所示,将stage2,3,4都替换成Fused-MBConv结构后,在Tesla V100上从每秒训练155张图片提升到216张。但如果将所有stage都替换成Fused-MBConv结构会明显增加参数数量以及FLOPs,训练速度也会降低。所以作者使用NAS技术去搜索MBConv和Fused-MBConv的最佳组合。
3)同等的放大每个stage是次优的。 在EfficientNetV1中,每个stage的深度和宽度都是同等放大的。但每个stage对网络的训练速度以及参数数量的贡献并不相同,所以直接使用同等缩放的策略并不合理。在这篇文章中,作者采用了非均匀的缩放策略来缩放模型。
2.EfficientNetv2
2.1亮点
1)引入新的网络(EfficientNetv2),该网络在训练速度以及参数数量上都优于先前的一些网络。
2)提出了改进的渐进学习方法,该方法会根据训练图像的尺寸动态调节正则方法(例如dropout、data augmentation和mixup)。通过实验展示了该方法不仅能够提升训练速度,同时还能提升准确率。
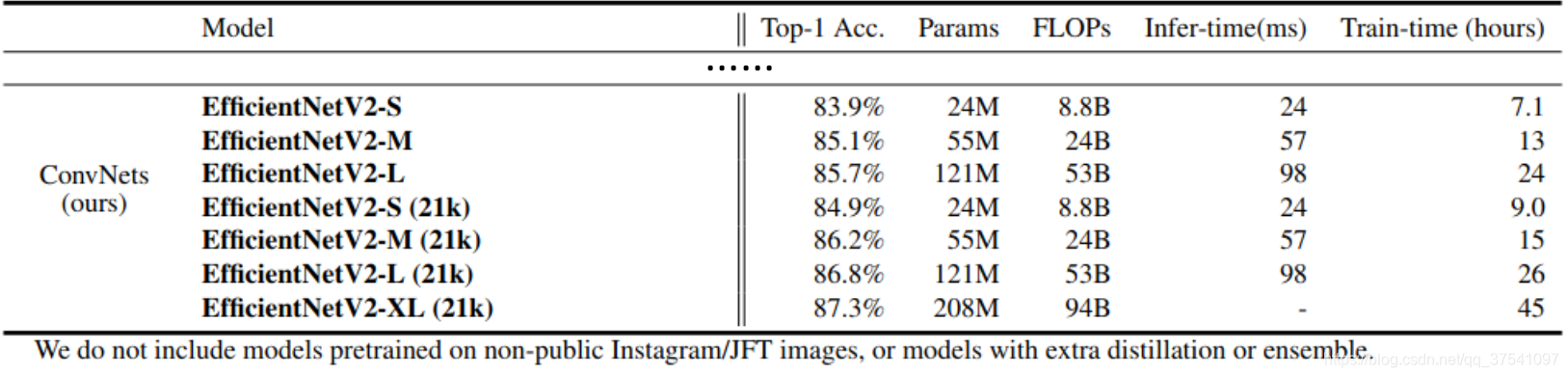
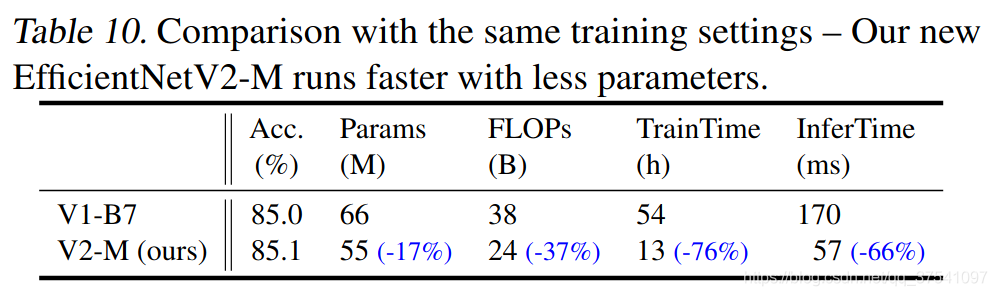
3)通过实验与先前的一些网络相比,训练速度提升11倍,参数数量减少为1/6.8。
3.EfficientNetv2网络结构
1)EfficientNetv2中使用了MBConv和Fused-MBConv模块。
2)EfficientNetV2会使用较小的expansion ratio(MBConv中第一个expand conv1x1或者Fused-MBConv中第一个expand conv3x3)比如4,在EfficientNetV1中基本都是6. 这样的好处是能够减少内存访问开销。
3)EfficientNetV2中更偏向使用更小(3x3)的kernel_size,在EfficientNetV1中使用了很多5x5的kernel_size。
4)移除了EfficientNetV1中最后一个步距为1的stage。

3.1 Conv3x3
就是普通的3x3卷积 + 激活函数(SiLU)+ BN
3.2 Fused-MBConv
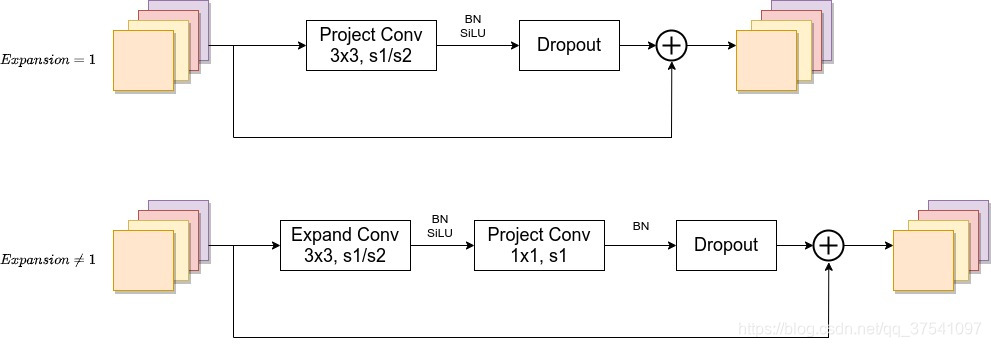
1)官方代码中Fused-MBConv中没有SE注意力模块。
2)当expansion ratio=1时表示channel不进行拓展,所以没有Expand Conv模块。
3)当stride=1且输入输出Channels相等时才有shortcut连接。还需要注意的是,当有shortcut连接时才有Dropout层。
4)表中MBConv4中的4表示expansion ratio的值。
3.3 MBConv

注意
每个Stage中会重复堆叠Operator模块多次,只有第一个Opertator模块的步距是按照表格中Stride来设置的,其他的默认都是1。
表中SE0.25表示表示SE模块中第一个全连接层的节点个数是输入该MBConv模块特征矩阵channels的1/4
#Channels表示该Stage输出的特征矩阵的Channels,
#Layers表示该Stage重复堆叠Operator的次数
#Stride表示每个stage中第一个block的stride
注意,在源码中Stage6的输出Channels是等于256并不是表格中的272,Stage7的输出Channels是1280并不是表格中的1792,后续论文的版本会修正过来
4.Progressive Learning渐进学习策略
训练图像的尺寸对训练模型的效率有很大的影响。所以在之前的一些工作中很多人尝试使用动态的图像尺寸(比如一开始用很小的图像尺寸,后面再增大)来加速网络的训练,但通常会导致Accuracy降低。为什么会出现这种情况呢?作者提出了一个猜想:Accuracy的降低是不平衡的正则化unbalanced regularization导致的。在训练不同尺寸的图像时,应该使用动态的正则方法(之前都是使用固定的正则方法)。
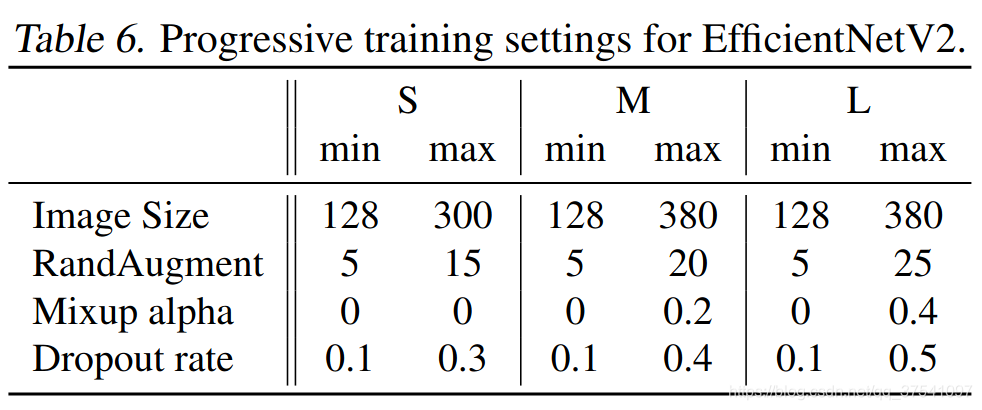
为了验证这个猜想,作者接着做了一些实验。在前面提到的搜索空间中采样并训练模型,训练过程中尝试使用不同的图像尺寸以及不同强度的数据增强data augmentations。当训练的图片尺寸较小时,使用较弱的数据增强augmentation能够达到更好的结果;当训练的图像尺寸较大时,使用更强的数据增强能够达到更好的接果。如下表所示,当Size=128,RandAug magnitude=5时效果最好;当Size=300,RandAug magnitude=15时效果最好:
基于以上实验,作者就提出了渐进式训练策略Progressive Learning。如下图所示,在训练早期使用较小的训练尺寸以及较弱的正则方法weak regularization,这样网络能够快速的学习到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法adding stronger regularization。这里所说的regularization包括dropout rate,RandAugment magnitude以及mixup ratio。

下表给出了EfficientNetV2(S,M,L)三个模型的渐进学习策略参数:
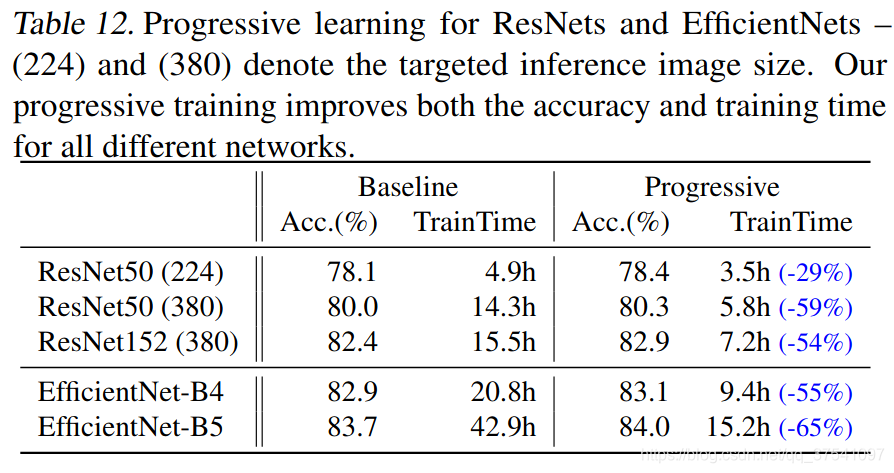
作者还在Resnet以及EfficientNetV1上进行了测试,如下表所示,使用了渐进式学习策略后确实能够有效提升训练速度并且能够小幅提升Accuracy。
5.EfficientNetv2模型代码
from collections import OrderedDict
from functools import partial
from typing import Callable, Optional
import torch.nn as nn
import torch
from torch import Tensor
def drop_path(x, drop_prob: float = 0., training: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
This function is taken from the rwightman.
It can be seen here:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py#L140
"""
if drop_prob == 0. or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class ConvBNAct(nn.Module):
def __init__(self,
in_planes: int,
out_planes: int,
kernel_size: int = 3,
stride: int = 1,
groups: int = 1,
norm_layer: Optional[Callable[..., nn.Module]] = None,
activation_layer: Optional[Callable[..., nn.Module]] = None):
super(ConvBNAct, self).__init__()
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU # alias Swish (torch>=1.7)
self.conv = nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False)
self.bn = norm_layer(out_planes)
self.act = activation_layer()
def forward(self, x):
result = self.conv(x)
result = self.bn(result)
result = self.act(result)
return result
class SqueezeExcite(nn.Module):
def __init__(self,
input_c: int, # block input channel
expand_c: int, # block expand channel
se_ratio: float = 0.25):
super(SqueezeExcite, self).__init__()
squeeze_c = int(input_c * se_ratio)
self.conv_reduce = nn.Conv2d(expand_c, squeeze_c, 1)
self.act1 = nn.SiLU() # alias Swish
self.conv_expand = nn.Conv2d(squeeze_c, expand_c, 1)
self.act2 = nn.Sigmoid()
def forward(self, x: Tensor) -> Tensor:
scale = x.mean((2, 3), keepdim=True)
scale = self.conv_reduce(scale)
scale = self.act1(scale)
scale = self.conv_expand(scale)
scale = self.act2(scale)
return scale * x
class MBConv(nn.Module):
def __init__(self,
kernel_size: int,
input_c: int,
out_c: int,
expand_ratio: int,
stride: int,
se_ratio: float,
drop_rate: float,
norm_layer: Callable[..., nn.Module]):
super(MBConv, self).__init__()
if stride not in [1, 2]:
raise ValueError("illegal stride value.")
self.has_shortcut = (stride == 1 and input_c == out_c)
activation_layer = nn.SiLU # alias Swish
expanded_c = input_c * expand_ratio
# 在EfficientNetV2中,MBConv中不存在expansion=1的情况所以conv_pw肯定存在
assert expand_ratio != 1
# Point-wise expansion
self.expand_conv = ConvBNAct(input_c,
expanded_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_layer)
# Depth-wise convolution
self.dwconv = ConvBNAct(expanded_c,
expanded_c,
kernel_size=kernel_size,
stride=stride,
groups=expanded_c,
norm_layer=norm_layer,
activation_layer=activation_layer)
self.se = SqueezeExcite(input_c, expanded_c, se_ratio) if se_ratio > 0 else nn.Identity()
# Point-wise linear projection
self.project_conv = ConvBNAct(expanded_c,
out_planes=out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity) # 注意这里没有激活函数,所有传入Identity
self.out_channels = out_c
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
if self.has_shortcut and drop_rate > 0:
self.dropout = DropPath(drop_rate)
def forward(self, x: Tensor) -> Tensor:
result = self.expand_conv(x)
result = self.dwconv(result)
result = self.se(result)
result = self.project_conv(result)
if self.has_shortcut:
if self.drop_rate > 0:
result = self.dropout(result)
result += x
return result
class FusedMBConv(nn.Module):
def __init__(self,
kernel_size: int,
input_c: int,
out_c: int,
expand_ratio: int,
stride: int,
se_ratio: float,
drop_rate: float,
norm_layer: Callable[..., nn.Module]):
super(FusedMBConv, self).__init__()
assert stride in [1, 2]
assert se_ratio == 0
self.has_shortcut = stride == 1 and input_c == out_c
self.drop_rate = drop_rate
self.has_expansion = expand_ratio != 1
activation_layer = nn.SiLU # alias Swish
expanded_c = input_c * expand_ratio
# 只有当expand ratio不等于1时才有expand conv
if self.has_expansion:
# Expansion convolution
self.expand_conv = ConvBNAct(input_c,
expanded_c,
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer)
self.project_conv = ConvBNAct(expanded_c,
out_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity) # 注意没有激活函数
else:
# 当只有project_conv时的情况
self.project_conv = ConvBNAct(input_c,
out_c,
kernel_size=kernel_size,
stride=stride,
norm_layer=norm_layer,
activation_layer=activation_layer) # 注意有激活函数
self.out_channels = out_c
# 只有在使用shortcut连接时才使用dropout层
self.drop_rate = drop_rate
if self.has_shortcut and drop_rate > 0:
self.dropout = DropPath(drop_rate)
def forward(self, x: Tensor) -> Tensor:
if self.has_expansion:
result = self.expand_conv(x)
result = self.project_conv(result)
else:
result = self.project_conv(x)
if self.has_shortcut:
if self.drop_rate > 0:
result = self.dropout(result)
result += x
return result
class EfficientNetV2(nn.Module):
def __init__(self,
model_cnf: list,
num_classes: int = 1000,
num_features: int = 1280,
dropout_rate: float = 0.2,
drop_connect_rate: float = 0.2):
super(EfficientNetV2, self).__init__()
for cnf in model_cnf:
assert len(cnf) == 8
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
stem_filter_num = model_cnf[0][4]
self.stem = ConvBNAct(3,
stem_filter_num,
kernel_size=3,
stride=2,
norm_layer=norm_layer) # 激活函数默认是SiLU
total_blocks = sum([i[0] for i in model_cnf])
block_id = 0
blocks = []
for cnf in model_cnf:
repeats = cnf[0]
op = FusedMBConv if cnf[-2] == 0 else MBConv
for i in range(repeats):
blocks.append(op(kernel_size=cnf[1],
input_c=cnf[4] if i == 0 else cnf[5],
out_c=cnf[5],
expand_ratio=cnf[3],
stride=cnf[2] if i == 0 else 1,
se_ratio=cnf[-1],
drop_rate=drop_connect_rate * block_id / total_blocks,
norm_layer=norm_layer))
block_id += 1
self.blocks = nn.Sequential(*blocks)
head_input_c = model_cnf[-1][-3]
head = OrderedDict()
head.update({"project_conv": ConvBNAct(head_input_c,
num_features,
kernel_size=1,
norm_layer=norm_layer)}) # 激活函数默认是SiLU
head.update({"avgpool": nn.AdaptiveAvgPool2d(1)})
head.update({"flatten": nn.Flatten()})
if dropout_rate > 0:
head.update({"dropout": nn.Dropout(p=dropout_rate, inplace=True)})
head.update({"classifier": nn.Linear(num_features, num_classes)})
self.head = nn.Sequential(head)
# initial weights
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x: Tensor) -> Tensor:
x = self.stem(x)
x = self.blocks(x)
x = self.head(x)
return x
def efficientnetv2_s(num_classes: int = 1000):
"""
EfficientNetV2
https://arxiv.org/abs/2104.00298
"""
# train_size: 300, eval_size: 384
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[2, 3, 1, 1, 24, 24, 0, 0],
[4, 3, 2, 4, 24, 48, 0, 0],
[4, 3, 2, 4, 48, 64, 0, 0],
[6, 3, 2, 4, 64, 128, 1, 0.25],
[9, 3, 1, 6, 128, 160, 1, 0.25],
[15, 3, 2, 6, 160, 256, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.2)
return model
def efficientnetv2_m(num_classes: int = 1000):
"""
EfficientNetV2
https://arxiv.org/abs/2104.00298
"""
# train_size: 384, eval_size: 480
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[3, 3, 1, 1, 24, 24, 0, 0],
[5, 3, 2, 4, 24, 48, 0, 0],
[5, 3, 2, 4, 48, 80, 0, 0],
[7, 3, 2, 4, 80, 160, 1, 0.25],
[14, 3, 1, 6, 160, 176, 1, 0.25],
[18, 3, 2, 6, 176, 304, 1, 0.25],
[5, 3, 1, 6, 304, 512, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.3)
return model
def efficientnetv2_l(num_classes: int = 1000):
"""
EfficientNetV2
https://arxiv.org/abs/2104.00298
"""
# train_size: 384, eval_size: 480
# repeat, kernel, stride, expansion, in_c, out_c, operator, se_ratio
model_config = [[4, 3, 1, 1, 32, 32, 0, 0],
[7, 3, 2, 4, 32, 64, 0, 0],
[7, 3, 2, 4, 64, 96, 0, 0],
[10, 3, 2, 4, 96, 192, 1, 0.25],
[19, 3, 1, 6, 192, 224, 1, 0.25],
[25, 3, 2, 6, 224, 384, 1, 0.25],
[7, 3, 1, 6, 384, 640, 1, 0.25]]
model = EfficientNetV2(model_cnf=model_config,
num_classes=num_classes,
dropout_rate=0.4)
return model