一、主要问题
系统中有一张温控终端状态的表tcState,记录了所有温控终端的温控状态,大约有1600万条数据。需求就是通过列表的形式展示出所有温控终端最新的温控终端状态,查询条件有公司id、终端分组id、温控终端id、状态读取时间。
基本的查询逻辑就是根据查询条件、索引筛选数据,对数据根据温控终端进行分组、按照最新时间排序。
但是第一版做出来,发现查询速度很慢,一次查询用了7/8秒钟,完全无法接受,于是开始对整个过程进行拆解分析,找出问题和瓶颈。
二、索引查询
复合索引
首先索引问题,需要检查索引是否命中,可以使用explain()函数查看MongoDB在执行过程的准备过程。
这是我修改后建立的复合索引:
companyId ASC, tcGroupId ASC, tempControllerId ASC, readingTime DESC索引失效:
复合索引生效的原则是前缀生效
以下的场景索引是生效的,因为它们都包含了索引的前缀
db.tcState.find({companyId :18,tcGroupId :1,readingTime :'2022-08-31'})
db.tcState.find({companyId :18,tcGroupId :1})
db.tcState.find({companyId :18})
db.tcState.find({tcGroupId :1,companyId :1})
db.tcState.find({companyId :1,readingTime :'2022-08-31'})以下场景都是无效,因为它们没有包含索引前缀
db.student.find({tcGroupId :1})
db.student.find({tcGroupId :1,readingTime :'2022-08-31'})重复建立索引:

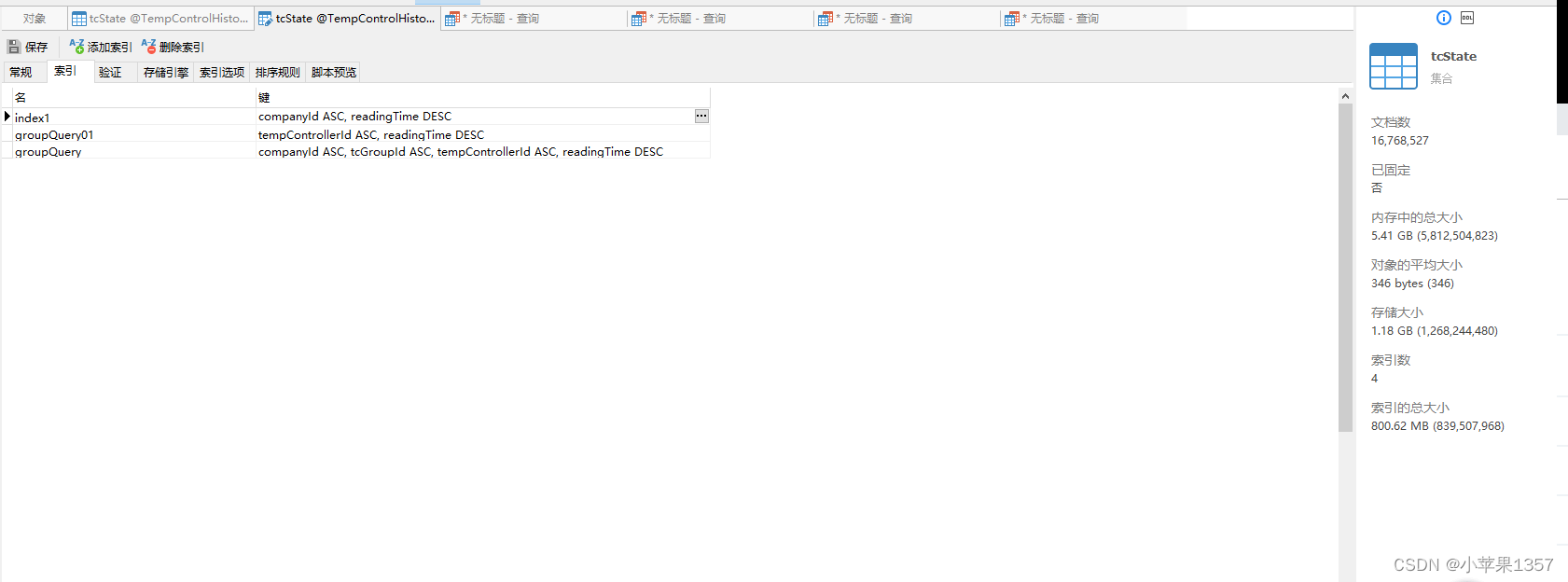
如图所示,index1索引和groupQuery索引
以下的场景使用的索引都是 groupQuery,第一个索引index1永远不会发挥作用,反而浪费了存储和降低了插入性能
db.tcState.find({companyId :1})
db.tcState.find({companyId :1,readingTime :'2022-08-31'})但是,为什么我还是要建立index1这个索引呢?
这是因为我发现,如果我用readingTime 排序的时候,groupQuery索引就无法命中了,具体原因,暂时不太清楚
db.tcState.find({companyId:1}).sort({readingTime:-1})三、排序sort
这里排序出现的主要问题就是到底在什么时候排序?
db.tcState.aggregate([
{ $match : { companyId : 1}},
{ $sort : { readingTime : -1}},
{ $group : { _id : "$tempControllerId",tempControllerId:{$first:"$tempControllerId"}, readingTime:{$first:"$readingTime"}}},
{ $skip : 0},
{ $limit : 20}
]);第一次,我选择了,先查询数据,再根据时间进行排序找到最新数据,最后进行分组 ,但这样其实相当于要对全部数据进行排序,对资源的消耗是巨大的,虽然现在有了索引,但是结合分组时,默认只取第一条数据的逻辑,其实我们可以不用按时间排序,默认分组后,就是获取到的每一个终端最新的一条数据。这样我们就可以把时间排序放在分组后,分组之后的数据量是很小的,速度更快。
db.tcState.aggregate([
{ $match : { companyId : 1}},
{ $group : { _id : "$tempControllerId",tempControllerId:{$first:"$tempControllerId"}, readingTime:{$first:"$readingTime"}}},
{ $sort : { readingTime : -1}},
{ $skip : 0},
{ $limit : 20}
]);四、分组group
使用分组,大家要先对aggregate 管道的相关功能有足够了解,这里我就不详细说明了,直接进行我的分析:
db.tcState.aggregate([
{ $match : { companyId : 1}},
{ $group : { _id : "$tempControllerId",tempControllerId:{$first:"$tempControllerId"}, readingTime:{$first:"$readingTime"}}},
{ $sort : { readingTime : -1}},
{ $skip : 0},
{ $limit : 20}
]);分组,是根据_id 对应的tempControllerId,进行分组的。而_id后边的几个字段,则是你要返回的数据字段,具体返回字段是要你自己写的。
通过first,则可以得到分组后,每一个终端对应的最新的一条数据。
但是在这里同样有一个问题,虽然我们通过建立索引,使查询和排序的速度大大提升,但是在分组这一步还是遇到了瓶颈,索引对于分组并没有作用,这就意味着,我们要把索引查询到的终端对应的所有历史数据一起进行分组。这个分组的是很慢的。
我的解决方案就是:我们其实只需要通过分组留下最新的一条数据,那么我们就可以通过时间字段进行筛选,我们只查询最新的一天或者三天内的数据,通过筛选条件,人为减少分组数据,这样分组的速度就会大大提升。
readingTime : { "$gte" : ISODate("2022-08-29T00:00:00Z"), "$lt" : ISODate("2022-08-31T00:00:00Z") }这就是我认为最核心的一个点,就是通过筛选条件,减少你要操作的数据量。
db.tcState.aggregate([
{ $match : { companyId : 1,
readingTime : { "$gte" : ISODate("2022-08-29T00:00:00Z"), "$lt" : ISODate("2022-08-31T00:00:00Z") }
}},
{ $group : { _id : "$tempControllerId",tempControllerId:{$first:"$tempControllerId"}, readingTime:{$first:"$readingTime"}}},
{ $sort : { readingTime : -1}},
{ $skip : 0},
{ $limit : 20}
]
);五、最终结果
通过以上索引、排序、分组的优化,最终我的查询时间缩减到了几十毫秒之内,完全符合业务需求,虽然只是不到2000万的数据量,但是我觉得优化的思路才是非常重要的。
最后再附上java代码对应的实现方式:
public List<TcState> searchTcStateList(TcStateDto tcStateDto) {
//组织查询条件集合
Criteria[] criteriaArray = getTcStateCriteriaArray(tcStateDto);
Aggregation aggregation = Aggregation.newAggregation(
match(new Criteria().andOperator(criteriaArray)),
Aggregation.group("tempControllerId")
.first("tempControllerId").as("tempControllerId")
.first("companyId").as("companyId")
.first("tcGroupId").as("tcGroupId")
.first("readingTime").as("readingTime")
.first("tempControllerAddress").as("tempControllerAddress")
.first("runningState").as("runningState")
sort(new Sort(Sort.Direction.DESC, "readingTime"))
)
// 解决排序内存不足问题
.withOptions(AggregationOptions.builder().allowDiskUse(true).build());
// 获取分组后的数据
AggregationResults<TcState> groupResults
= mongoTemplate.aggregate(aggregation, TcState.class, TcState.class);
List<TcState> dataList = groupResults.getMappedResults();
return dataList;
}private Criteria[] getTcStateCriteriaArray(TcStateDto tcStateDto) {
// 定义一个存放条件的集合
List<Criteria> criteriaList = new ArrayList<>();
// 定义一个存放条件的数组(暂时不给长度)
Criteria[] criteriaArray = {};
if (null != tcStateDto) {
if (null != tcStateDto.getCompanyId()) {
criteriaList.add(Criteria.where("companyId").is(tcStateDto.getCompanyId()));
}
//根据温控终端多个查询时,无法使用索引
if ((tcStateDto.getTempIdList() != null && tcStateDto.getTempIdList().size() > 0)) {
Criteria c = Criteria.where("tempControllerId").in(tcStateDto.getTempIdList());
criteriaList.add(c);
}else {
//根据温控终端多个查询时,就不需要终端分组的条件
if ((tcStateDto.getIdList() != null && tcStateDto.getIdList().size() > 0)) {
Criteria c = Criteria.where("tcGroupId").in(tcStateDto.getIdList());
criteriaList.add(c);
} else if (null != tcStateDto.getTcGroupId() && (tcStateDto.getIdList() == null || tcStateDto.getIdList().size() <= 0)) {
criteriaList.add(Criteria.where("tcGroupId").is(tcStateDto.getTcGroupId()));
} else if (null != tcStateDto.getTempControllerId() && (tcStateDto.getTempIdList() == null || tcStateDto.getTempIdList().size() <= 0)) {
criteriaList.add(Criteria.where("tempControllerId").is(tcStateDto.getTempControllerId()));
}
}
if (null != tcStateDto.getReadingTime()) {
criteriaList.add(Criteria.where("readingTime").is(tcStateDto.getReadingTime()));
}
if (StringUtils.isNotBlank(tcStateDto.getStartDate()) && StringUtils.isBlank(tcStateDto.getEndDate())) {
criteriaList.add(Criteria.where("readingTime").gte(DateUtil.stringToDate(tcStateDto.getStartDate())));
}
if (StringUtils.isNotBlank(tcStateDto.getEndDate()) && StringUtils.isBlank(tcStateDto.getStartDate())) {
criteriaList.add(Criteria.where("readingTime").lte(DateUtil.stringToDate(tcStateDto.getEndDate())));
}
if (StringUtils.isNotBlank(tcStateDto.getStartDate()) && StringUtils.isNotBlank(tcStateDto.getEndDate())) {
criteriaList.add(Criteria.where("readingTime").gte(DateUtil.stringToDate(tcStateDto.getStartDate()))
.lte(DateUtil.stringToDate(tcStateDto.getEndDate())));
}
}
// 如果有条件
if (criteriaList.size() > 0) {
// 集合的个数就是数组的长度
criteriaArray = new Criteria[criteriaList.size()];
// 遍历添加到数组中
for (int i = 0; i < criteriaList.size(); i++) {
criteriaArray[i] = criteriaList.get(i);
}
}
return criteriaArray;
}