活动地址:CSDN21天学习挑战赛
前言
经过前段时间研究,从LeNet-5手写数字入门到最近研究的一篇天气识别。我想干一票大的,因为我本身从事的就是C++/Qt开发,对Qt还是比较熟悉,所以我想实现一个基于Qt的界面化的一个人脸识别。
对卷积神经网络的概念比较陌生的可以看一看这篇文章:卷积实际上是干了什么
想了解神经网络的训练流程、或者环境搭建的可以看这篇文章:环境搭建与训练流程
ps:由于前段时间有小伙伴反应虽然跟着能正常训练但是好多函数都不明白,所以我这里就对所用到的函数都做一个介绍,不要嫌啰嗦哦。
基本思路
具体步骤如下:
- 首先需要收集数据,我的想法是通过OpenCV调用摄像头进行收集人脸照片。
- 然后进行预处理,主要是对对数据集分类,训练集、验证集、测试集。选取合适的参数,例如损失函数。图像灰度化、归一化等等操作。
- 开始训练模型,提前创建好标签键值对。
- 测试人脸识别效果,通过OpenCV捕获人脸照片然后对图片进行预处理最后传入模型中,然后将识别的结果通过文字的形式打印在屏幕上,以此循环,直到输入q退出。
关于环境
| 库 | 版本 |
|---|---|
| python | 3.7.0 |
| tensorflow | 2.1 |
| OpenCV | 3.4.2 |
| pyQt | 5.15.7 |
OpenCV
OpenCV是一个基于BSD许可(开源)发行的跨平台计算机视觉库,可以运行在Linux、Windows、Android和Mac OS操作系统上。它轻量级而且高效–由一系列 C 函数和少量 C++ 类构成,同时提供了Python、Ruby、MATLAB等语言的接口,实现了图像处理和计算机视觉方面的很多通用算法。
OpenCV用C++语言编写,它的主要接口也是C++语言,但是依然保留了大量的C语言接口。该库也有大量的Python, Java and MATLAB/OCTAVE (版本2.5)的接口。这些语言的API接口函数可以通过在线文档获得。如今也提供对于C#,Ch, Ruby的支持。
OpenCV具有的特征
- 开源计算机视觉库采用C/C++编写;
- 使用目的是开发实时应用程序;
- 独立于操作系统、硬件和图形管理器;
- 具有通用的图像/视频载入、保存和获取模块;
- 具有底层和高层的应用开发包。
OpenCV具有的功能
- 对图像数据的操作,包括分配、释放、复制、设置和转换数据;
- 对图像和视频的输入输出;
- 具有对矩阵和向量的操作以及线性代数的算法程序;
- 可对各种动态数据结构进行操作;
- 具有基本的数字图像处理能力;
- 可对各种结构进行分析;
- 对摄像头的定标;
- 对运动的分析;
- 对目标的识别;
- 具有基本的GUI功能。
安装OpenCV
建议采用Anaconda方式安装更加容易。
关键API
导入方式:import cv2
imread
功能:读取图片文件
函数原型:imread(filename, flags)
参数介绍:
| 参数 | 说明 |
|---|---|
| filepath | 读入imge的完整路径 |
| flags | 标志位,读取图片的形式{cv2.IMREAD_COLOR,cv2.IMREAD_GRAYSCALE,cv2.IMREAD_UNCHANGED} |
这里对flags的参数进行详细介绍:
| 标志位 | 说明 |
|---|---|
| cv2.IMREAD_COLOR | 默认参数,读入一副彩色图片,忽略alpha通道,可用1作为实参替代 |
| cv2.IMREAD_GRAYSCALE | 读入灰度图片,可用0作为实参替代 |
| cv2.IMREAD_UNCHANGED | 顾名思义,读入完整图片,包括alpha通道,可用-1作为实参替代 |
注:alpha通道,又称A通道,是一个8位的灰度通道,该通道用256级灰度来记录图像中的透明度复信息,定义透明、不透明和半透明区域,其中黑表示全透明,白表示不透明,灰表示半透明
namedWindow
功能·:新建一个显示窗口。可以指定窗口的类型。
函数原型:void nameWindow(const string& winname,int flags = WINDOW_AUTOSIZE) ;
参数介绍:
| 参数 | 说明 |
|---|---|
| winname | 窗口的名称 |
| WINDOW_AUTOSIZE | 窗口的标识,默认为WINDOW_AUTOSIZE |
这里对第二个参数进行了详细说明:
| 标识的分类 | 说明 |
|---|---|
| WINDOW_AUTOSIZE | 窗口大小自动适应图片大小,并且不可手动更改。 |
| WINDOW_NORMAL | 用户可以改变这个窗口大小 |
| WINDOW_OPENGL | 窗口创建的时候会支持OpenGL |
示例
使用cv2.imshow()的时候,如果图片太大,会显示不全并且无法调整。因此在cv2.imshow()的前面加上这样的一个语句:cv2.namedWindow('image', 0),得到的图像框就可以自行调整大小,可以拉伸进行自由调整。
这里需要注意的是namedWindow和imshow中的窗口名称需要一致不然会创建多个窗口出来。
waitKey:表示等待时间,单位毫秒。0表示一直等待。
import cv2
import sys
img = cv2.imread("C:\\Users\\Administrator\\Desktop\\9.jpg", 1) # 参数1:图片路径。参数2:显示原图
cv2.namedWindow("aa", 0)
cv2.imshow("aa", img)
cv2.waitKey(0) # 0表示不自动退出 如5000表示等待5秒
运行结果:

cv2.VideoCapture(0)
参数0表示默认为使用电脑的内第一个摄像头,如果需要读取已有的视频则参数改为视频所在路径路径
如
cap=cv2.VideoCapture('video.mp4')
CascadeClassifier
OpenCV下的data\haarcascades中有4个haar特征训练的级联分类器:
- haarcascade_frontalface_alt.xml
- haarcascade_frontalface_alt_tree.xml
- haarcascade_frontalface_alt2.xml
- haarcascade_frontalface_default.xml
这里不对级联分类器展开讨论,有兴趣的小伙伴自己去深入了解一下啦。
在本次项目中采用的是haarcascade_frontalface_alt2.分类器。通过CascadeClassifier函数进行添加分类器。
classfier = cv2.CascadeClassifier("./model/haarcascade_frontalface_alt2.xml")
cap.isOpened()
判断视频对象是否成功读取,成功读取视频对象返回True,失败返回False。
ok, frame = cap.read()
读取一帧数据,返回值ok是布尔类型,正确读取则返回True,读取失败或读取视频结尾则会返回False。frame为每一帧的图像,这里图像是三维矩阵,即frame.shape = (640,480,3),读取的图像为BGR格式。
cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
功能:颜色空间转换函数,参数一是需要转换的图片,参数二是转换成何种格式
格式介绍:
| 格式 | 说明 |
|---|---|
| cv2.COLOR_BGR2RGB | 将BGR格式转换成RGB格式 |
| cv2.COLOR_BGR2GRAY | 将BGR格式转换成灰度图片 |
classfier.detectMultiScale
功能:检测出图片中所有的人脸,并将人脸用vector保存各个人脸的坐标、大小(用矩形表示)
函数原型:void detectMultiScale(const Mat& image,CV_OUT vector
参数介绍:
| 参数 | 说明 |
|---|---|
| image | 待检测图片,一般为灰度图像加快检测速度; |
| objects | 被检测物体的矩形框向量组; |
| scaleFactor | 表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10%; |
| minNeighbors | 表示构成检测目标的相邻矩形的最小个数(默认为3个)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。 如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框, 这种设定值一般用在用户自定义对检测结果的组合程序上; |
| flags | 要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域, 因此这些区域通常不会是人脸所在区域; |
| minSize和maxSize | 用来限制得到的目标区域的范围。 |
cv2.rectangle
功能:通过对角线上的两个顶点绘制简单、指定粗细或者带填充的矩形。
在这里主要用于框出人脸区域。
函数原型:void rectangle(Mat& img, Point pt1,Point pt2,const Scalar& color, int thickness=1, int lineType=8, int shift=0)
参数介绍:
| 参数 | 说明 |
|---|---|
| img | 图像. |
| pt1 | 矩形的一个顶点。 |
| pt2 | 矩形对角线上的另一个顶点 |
| color | 线条颜色 (RGB) 或亮度(灰度图像 )(grayscale image)。 |
| thickness | 组成矩形的线条的粗细程度。取负值时(如 CV_FILLED)函数绘制填充了色彩的矩形。 |
| line_type | 线条的类型。见cvLine的描述 |
| shift | 坐标点的小数点位数。 |
框出人脸区域
通过 OpenCV 的 Harr 分类器检测人脸,并输出识别结果(x,y,w,h)。
图片坐标以左上角为原点;
(x,y)代表人脸区域左上角坐标;
w代表人脸区域的宽度(width);
h代表人脸区域的高度(height)。
x, y, w, h = faceRect # 原图上框出需要保存的图
color = (0, 0, 255) # 识别出人脸后要画的边框的颜色,RGB格式
# frame 是原图,(x - 10, y - 10) 是图片的左上角的那个点,(x + w + 10, y + h + 10)是图片右下角的点 color, 2 颜色和线的宽度
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
imwrite
功能:用于将图像保存到指定的文件,可以为各种格式的图像。
函数原型:imwrite(const String & filename,InputArray img,const std::vector & params = std::vector<int>() )
参数介绍:
| 参数 | 说明 |
|---|---|
| filename | 需要保存图像的文件名,要保存图片为哪种格式,就带什么后缀。 |
| img | 要保存的图像。 |
| params | 表示为特定格式保存的参数编码。 |
编码参数:
| 编码 | 说明 |
|---|---|
| IMWRITE_JPEG_QUALITY Python :cv.IMWRITE_JPEG_QUALITY | 对于JPEG,它可以是从0到100的质量(越高越好)。默认值为95。 |
| IMWRITE_JPEG_PROGRESSIVE Python:cv.IMWRITE_JPEG_PROGRESSIVE | 启用JPEG功能,0或1,默认为False。 |
| IMWRITE_JPEG_OPTIMIZE Python:cv.IMWRITE_JPEG_OPTIMIZE | 启用JPEG功能,0或1,默认为False。 |
| IMWRITE_JPEG_RST_INTERVAL Python:cv.IMWRITE_JPEG_RST_INTERVAL | JPEG重启间隔,0 - 65535,默认为0 - 无重启。 |
| IMWRITE_JPEG_LUMA_QUALITY Python:cv.IMWRITE_JPEG_LUMA_QUALITY | 单独的亮度质量等级,0 - 100,默认为0 - 不使用。 |
| IMWRITE_JPEG_CHROMA_QUALITY Python:cv.IMWRITE_JPEG_CHROMA_QUALITY | 单独的色度质量等级,0 - 100,默认为0 - 不使用。 |
| IMWRITE_PNG_COMPRESSION Python:cv.IMWRITE_PNG_COMPRESSION | 对于PNG,它可以是从0到9的压缩级别。值越高意味着更小的尺寸和更长的压缩时间。如果指定,则策略更改为IMWRITE_PNG_STRATEGY_DEFAULT(Z_DEFAULT_STRATEGY)。默认值为1(最佳速度设置)。 |
| IMWRITE_PNG_STRATEGY Python:cv.IMWRITE_PNG_STRATEGY | 其中一个品种:: ImwritePNGFlags,默认为IMWRITE_PNG_STRATEGY_RLE。 |
| IMWRITE_PNG_BILEVEL Python:cv.IMWRITE_PNG_BILEVEL | 二进制级别PNG,0或1,默认为0。 |
| IMWRITE_PXM_BINARY Python:cv.IMWRITE_PXM_BINARY | 对于PPM,PGM或PBM,它可以是二进制格式标志,0或1.默认值为1。 |
| IMWRITE_WEBP_QUALITY Python:cv.IMWRITE_WEBP_QUALITY | 覆盖EXR存储类型(默认为FLOAT(FP32))对于WEBP,它可以是1到100的质量(越高越好)。默认情况下(不带任何参数),如果质量高于100,则使用无损压缩。 |
| IMWRITE_PAM_TUPLETYPE Python:cv.IMWRITE_PAM_TUPLETYPE | 对于PAM,将TUPLETYPE字段设置为为格式定义的相应字符串值。 |
| IMWRITE_TIFF_RESUNIT Python:cv.IMWRITE_TIFF_RESUNIT | 对于TIFF,用于指定要设置的DPI分辨率单位; 请参阅libtiff文档以获取有效值。 |
| IMWRITE_TIFF_XDPI Python:cv.IMWRITE_TIFF_XDPI | 对于TIFF,用于指定X方向DPI。 |
| IMWRITE_TIFF_YDPI Python:cv.IMWRITE_TIFF_YDPI | 对于TIFF,用于指定Y方向DPI。 |
| IMWRITE_TIFF_COMPRESSION Python:cv.IMWRITE_TIFF_COMPRESSION | 对于TIFF,用于指定图像压缩方案。请参阅libtiff以获取与压缩格式对应的整数常量。注意,对于深度为CV_32F的图像,仅使用libtiff的SGILOG压缩方案。对于其他支持的深度,可以通过此标志指定压缩方案; LZW压缩是默认值。 |
| IMWRITE_JPEG2000_COMPRESSION_X1000 Python:cv.IMWRITE_JPEG2000_COMPRESSION_X1000 | 对于JPEG2000,用于指定目标压缩率(乘以1000)。该值可以是0到1000.默认值是1000。 |
rectangle
功能:是在图像上绘制一个简单的矩形
函数原型:cv2.rectangle(img, pt1, pt2, color[, thickness[, lineType[, shift]]])
参数介绍:
| 参数 | 说明 |
|---|---|
| img | 图片路径 |
| pt1 和 pt2 | 分别代表矩形的左上角和右下角两个点,而且 x 坐标轴是水平方向的,y 坐标轴是垂直方向的。(当pt1坐标的x或者y 大于pt2坐标的x或者y, pt1 和 pt2 参数分别代表矩形的左下角和右上角两个点,pt1,pt2都必须是整型数) |
| color | 矩形边框的颜色 需要注意的是这里的 (0, 0, 255) 三个分别对应 B G R |
| thickness | 矩形边框的厚度 如果为负值,如 CV_FILLED,则表示填充整个矩形 |
| lineType | 算法的通道吧 |
| shift | 点坐标中的小数位数 |
cv2.FONT_HERSHEY_SIMPLEX
哈哈,这个主要是显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着。
cv2.putText
功能:在图片上添加文字
函数原型:cputText(img, text, org, fontFace, fontScale, color, thickness=None, lineType=None, bottomLeftOrigin=None):
参数介绍:
| 参数 | 说明 |
|---|---|
| image | 图片 |
| text | 要添加的文字 |
| org | 文字添加到图片上的位置 |
| fontFace | 字体的类型 |
| fontScale | 字体大小 |
| color | 字体颜色 |
| thickness字体粗细 |
ord()
功能:返回一个字符的ascii值。在这里用于输入q主动结束。
代码
# coding: utf-8
import cv2
import sys
def catch_usb_video(window_name, camera_idx):
'''使用cv2.imshow()的时候,如果图片太大,会显示不全并且无法调整。
因此在cv2.imshow()的前面加上这样的一个语句:cv2.namedWindow('image', 0),
得到的图像框就可以自行调整大小,可以拉伸进行自由调整。'''
cv2.namedWindow(window_name, 0)
# 视频来源,可以来自一段已存好的视频,也可以直接来自USB摄像头
cap = cv2.VideoCapture(camera_idx)
# 告诉OpenCV使用人脸识别分类器 级联分类器
'''
Haar特征是一种反映图像的灰度变化的,像素分模块求差值的一种特征。它分为三类:边缘特征、线性特征、中心特征和对角线特征。
'''
classfier = cv2.CascadeClassifier("./model/haarcascade_frontalface_alt2.xml")
# 识别出人脸后要画的边框的颜色,RGB格式
color = (0, 0, 255)
num = 0
while cap.isOpened():
ok, frame = cap.read() # 读取一帧数据
if not ok:
break
# 将当前帧转换成灰度图像
grey = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# 人脸检测,1.2和2分别为图片缩放比例和需要检测的有效点数
faceRects = classfier.detectMultiScale(grey, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
# faceRects = [405 237 222 222]
if len(faceRects) > 0: # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
# 在原图上框出需要保存的图
x, y, w, h = faceRect
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 将当前帧保存为图片
# frame 是原图,(x - 10, y - 10) 是图片的左上角的那个点,(x + w + 10, y + h + 10)是图片右下角的点
# color, 2 颜色和线的宽度
img_name = '%s/%d.jpg' % ('./deep_learning/zhangmeng', num)
image = frame[y - 10: y + h + 10, x - 10: x + w + 10]
cv2.imwrite(img_name, image)
num += 1
if num > (500): # 如果超过指定最大保存数量退出循环
break
# 画出矩形框
cv2.rectangle(frame, (x - 10, y - 10), (x + w + 10, y + h + 10), color, 2)
# 显示当前捕捉到了多少人脸图片了,这样站在那里被拍摄时心里有个数,不用两眼一抹黑傻等着
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(frame, 'num:%d' % (num), (x + 30, y + 30), font, 1, (255, 0, 255), 4)
# 超过指定最大保存数量结束程序
if num > (500):
break
# 显示图像
cv2.imshow(window_name, frame)
c = cv2.waitKey(1)
if c & 0xFF == ord('q'):
break
# 释放摄像头并销毁所有窗口
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
catch_usb_video("face", 0)
运行结果
我一伙计友情出演 进行识别测试
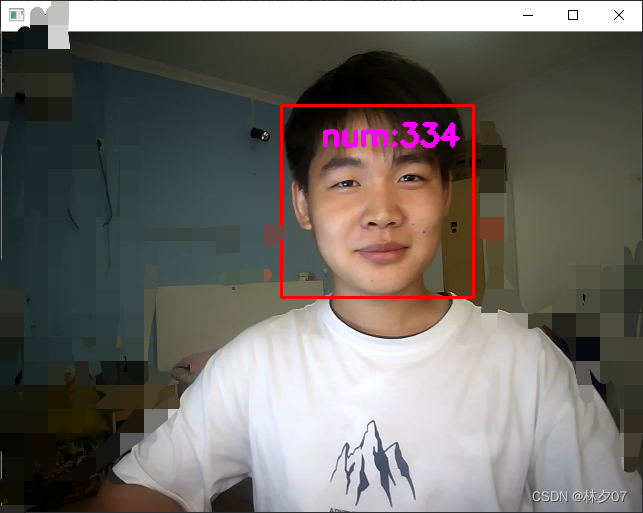
这里也可以看到图片都正常保存了。

总结
那么第一步到这里就完成了,目前来说我感觉最大的难度就是了解OpenCV相关的部分API函数。并没有设计其他过多的技术。