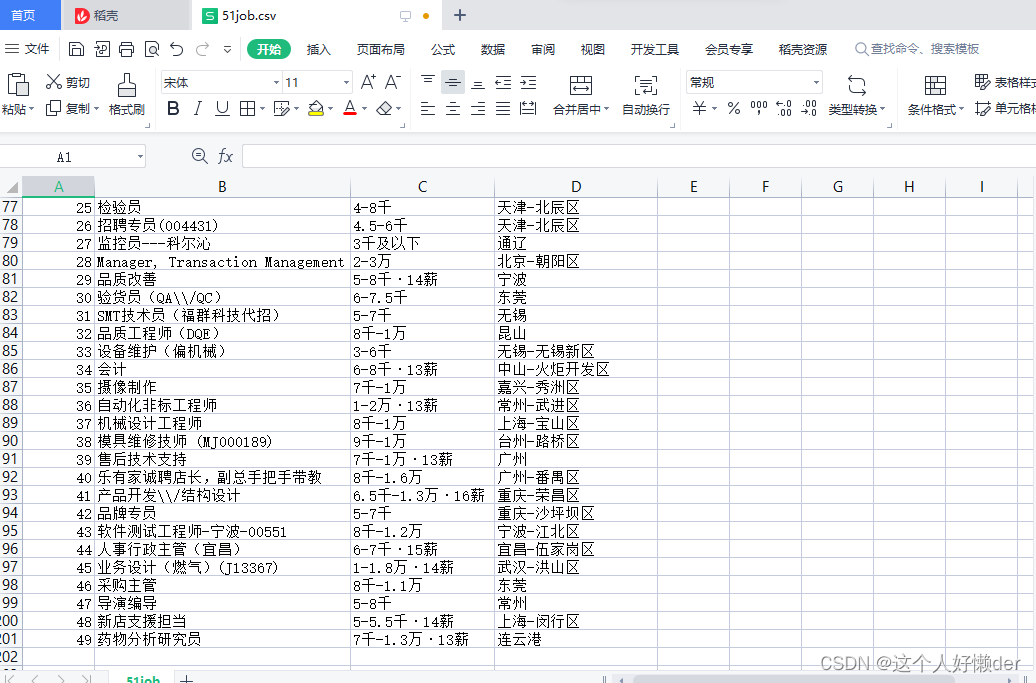
抓取网上的职位招聘信息
https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,1.html
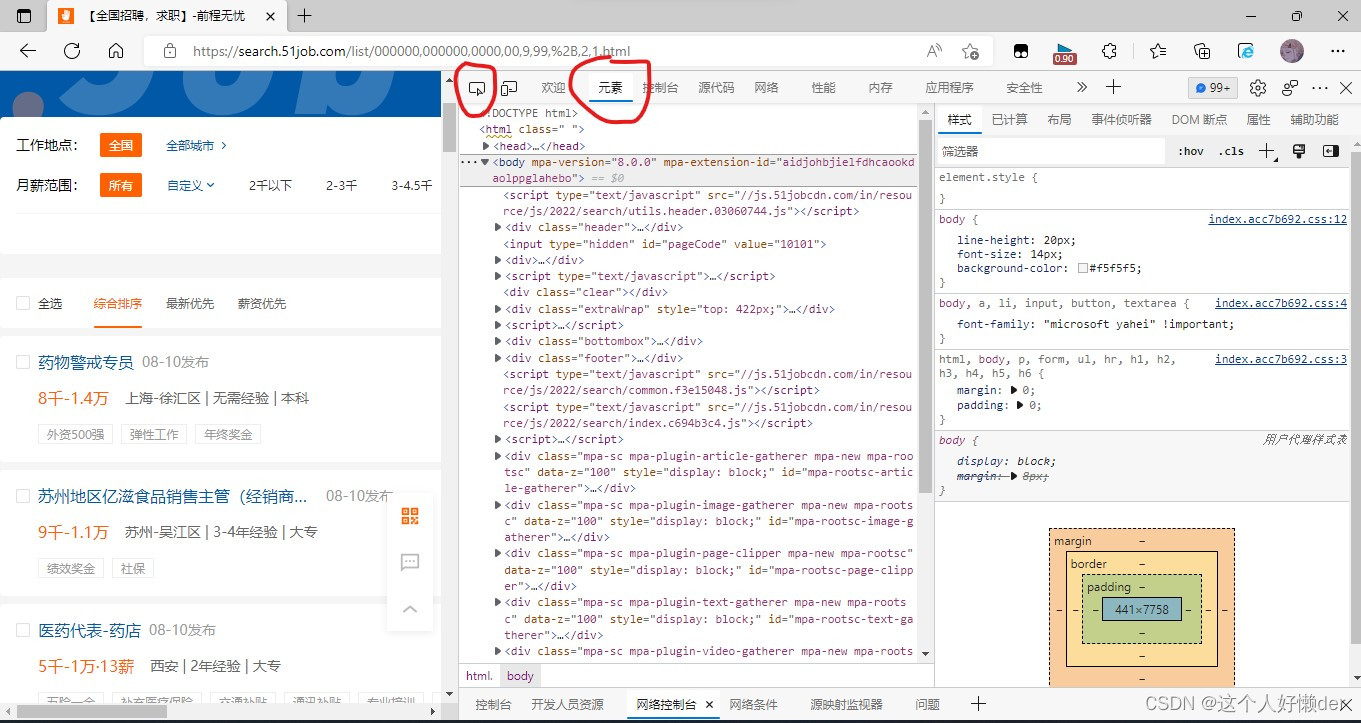
打开界面以后ctrl+shift+i,点击元素,再点击旁边圈起来的那个箭头,可以点击页面相应的部分查看代码,这样就可以看出放在了哪个部分里。
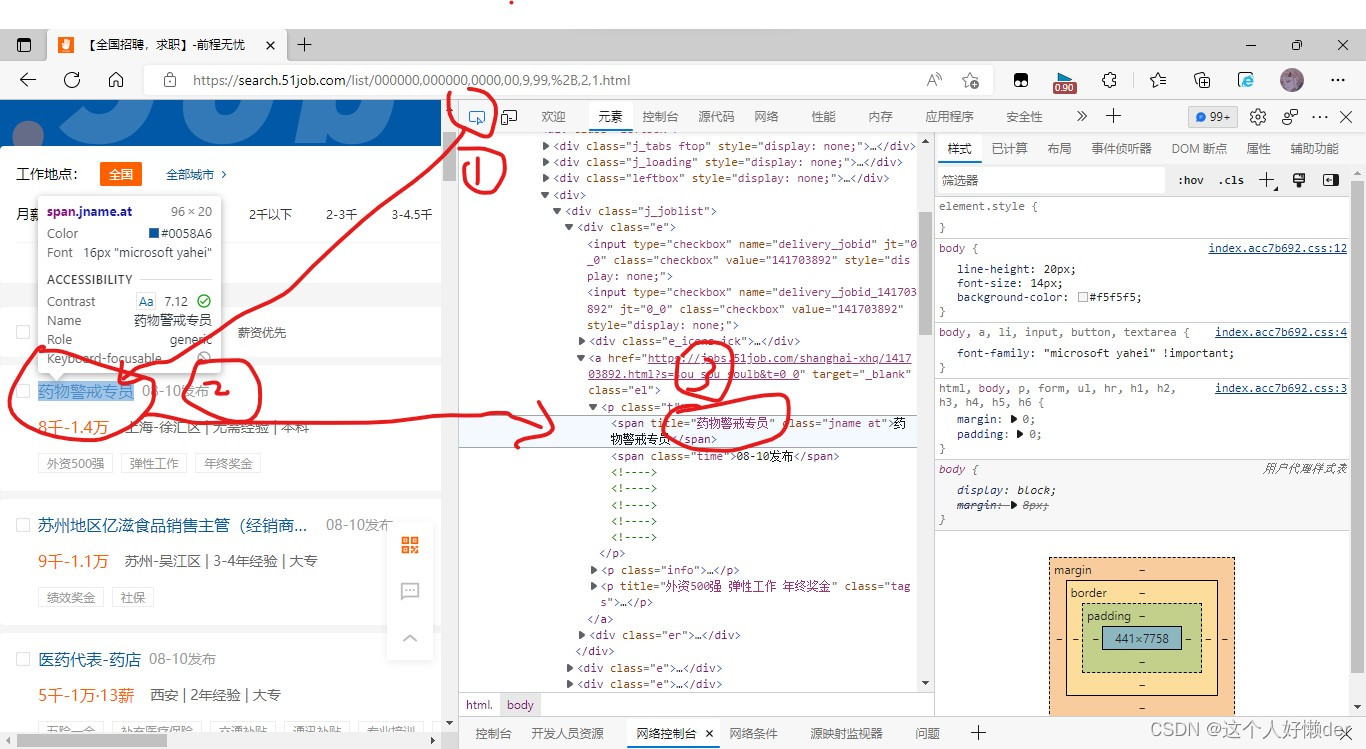
但是这是网页代码,并不是网络响应给我们的代码,应该如下图打开网络---搜索---找到关键字所在页面---ctrl+f查找,就能在这个页面查找到网络实际给我们的响应,对比网页代码,两个是不一样的,使用爬虫抓取的时候其实抓取的是响应中的内容。
使用pycharm实现一下获取响应内容并进行格式转换:
import requests #requests请求
from lxml import etree #XPath提取
import re
url="https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,1.html" #爬取目标
rest=requests.get(url) #获取网页信息
rest.encoding="gbk" #进行编码防止乱码
root=etree.HTML(rest.text) #将获取的文本进行转换,方便使用XPath获取节点
work=root.xpath('//.') #查找到有目标信息的节点
work=str(work) #转换为字符串
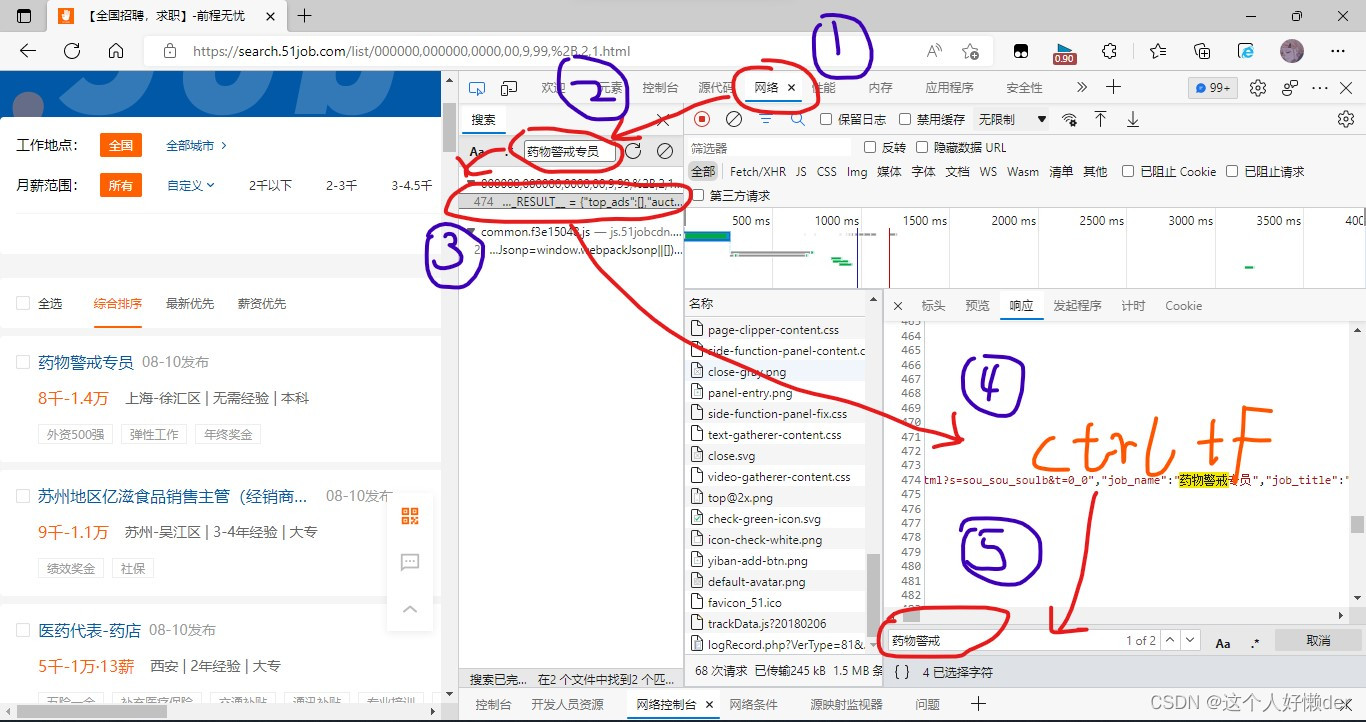
print(work) 上面代码首先获取了网络响应,并将文本使用了etree.HTML转换成Element对象,使用XPath方法显示所有内容,点击下面这个结果界面,ctrl+f也可以搜索想要的文字,这里搜索job_name。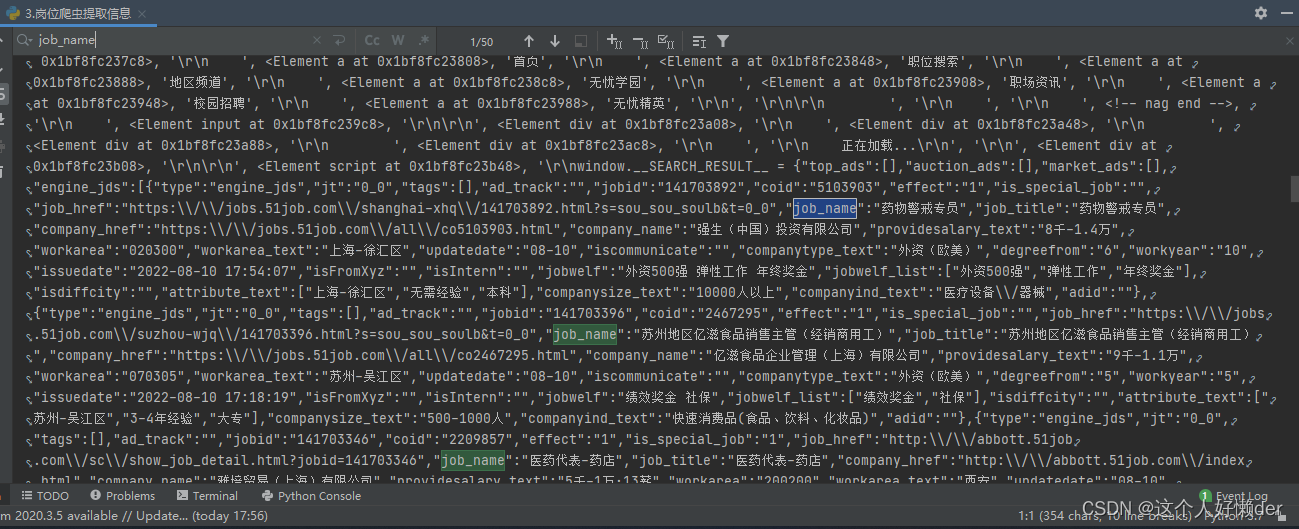
从输出结果可以看出,job_name在script标签内:

也可以在网页界面直接看到标签父子关系以及job_name所在的位置:
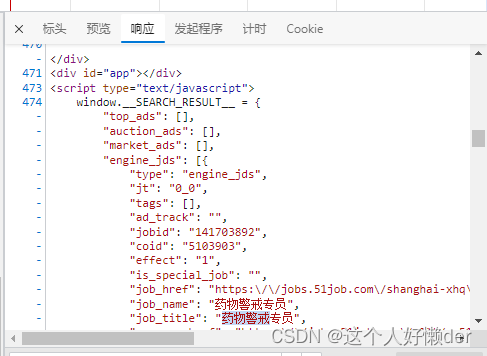
知道了我们需要的内容所在的位置,那么XPath节点选择范围就会变小,如下:
work=root.xpath('//script[@type="text/javascript"]/text()') 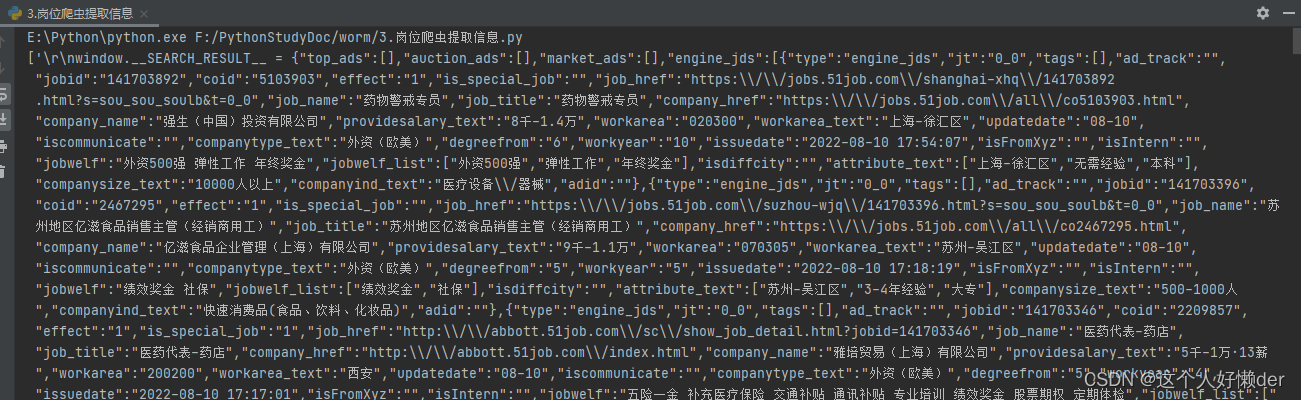
现在获取到的work就是script标签中的所有内容,现在要对其进行筛选,使用正则表达式。先分析一下:要获取所有的工作名称,那就是将匹配的工作名称进行分组,然后使用findall函数返回子串,也就是这个分组,就能获取所有的岗位名称而没有其他的干扰;再看岗位名称,周围有很多字符,但是前面是"job_name":后面是,"job_title" ,那么岗位名称的位置就可以唯一确定,无关紧要的字符使用.*?进行匹配,我们需要的工作岗位使用表达式 "job_name":"(.*?)","job_title" 即可匹配,工作岗位放在了子表达式里,这样就可以匹配完成,这里使用.*?是一个非贪婪匹配,因为这里有很多的job_name和job_title,贪婪匹配会将中间的所有归为,*里面,一直到最后一个job_title前面,才把工作岗位放在子表达式里,这样只会输出最后一个岗位,因此使用非贪婪匹配,完整正则表达式:
result=re.findall(r'.*?"job_name":"(.*?)","job_title".*?',work)完整代码:
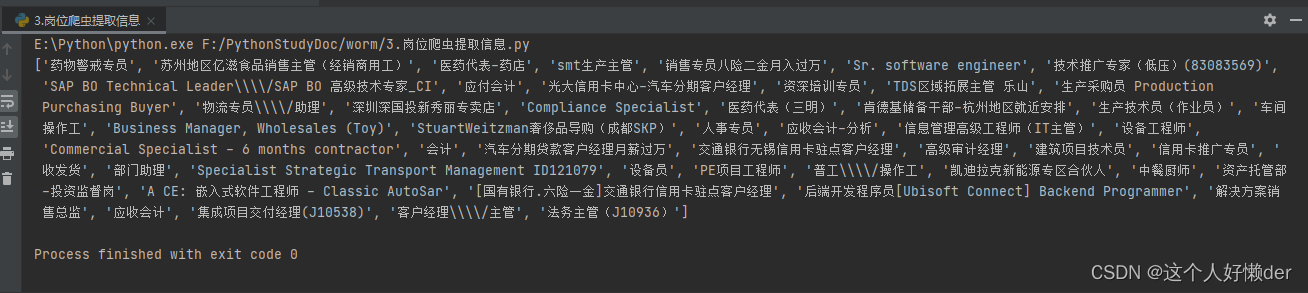
import requests #requests请求 from lxml import etree #XPath提取 import re url="https://search.51job.com/list/000000,000000,0000,00,9,99,%2B,2,1.html" #爬取目标 rest=requests.get(url) #获取网页信息 rest.encoding="gbk" #进行编码防止乱码 root=etree.HTML(rest.text) #将获取的文本进行转换,方便使用XPath获取节点 work=root.xpath('//script[@type="text/javascript"]/text()') #查找到有目标信息的节点 work=str(work) result=re.findall(r'.*?"job_name":"(.*?)","job_title".*?',work) print(result)输出结果:
这样整个网页的工作岗位被获取。
同理可以获取薪资,查看网页找到薪资在哪两个字符之间:
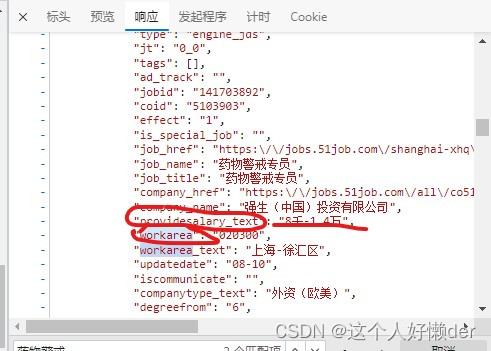
修改正则表达式:
result=re.findall(r'.*?"providesalary_text":"(.*?)","workarea".*?',work)输出结果:

result=re.findall(r'"job_name":"(.*?)"',work)使用这个正则表达式,可以不用确定前后的字符,直接根据job_name就能匹配后面的内容。
多页爬虫
使用爬虫爬取信息的时候不仅仅只有一页,要实现多页爬虫,首先分析网址:
https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,1.html https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,2.html https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,3.html https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,4.html
网站前四页的网址如上,可以看出网址只有最后html前的数字发生了改变,那么可以使用for循环进行网页自增变换:
for i in range(1,5):
url='https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,'+str(i)+'.html'因为网页这一串是字符串,而自增的i是数字,因此使用str(i)将数字转换为字符然后组合到一起,这样就是一个完整的网页,再将之前的获取代码放在for循环里面,就可以进行多页内容的爬取:
import requests #requests请求
from lxml import etree #XPath提取
import re
for i in range(1,5):
url='https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,'+str(i)+'.html'
rest=requests.get(url) #获取网页信息
rest.encoding="gbk" #进行编码防止乱码
root=etree.HTML(rest.text) #将获取的文本进行转换,方便使用XPath获取节点
work=root.xpath('//script[@type="text/javascript"]/text()') #查找到有目标信息的节点
work=str(work)
result=re.findall(r'.*?"job_name":"(.*?)","job_title".*?',work)
print(result)结果:
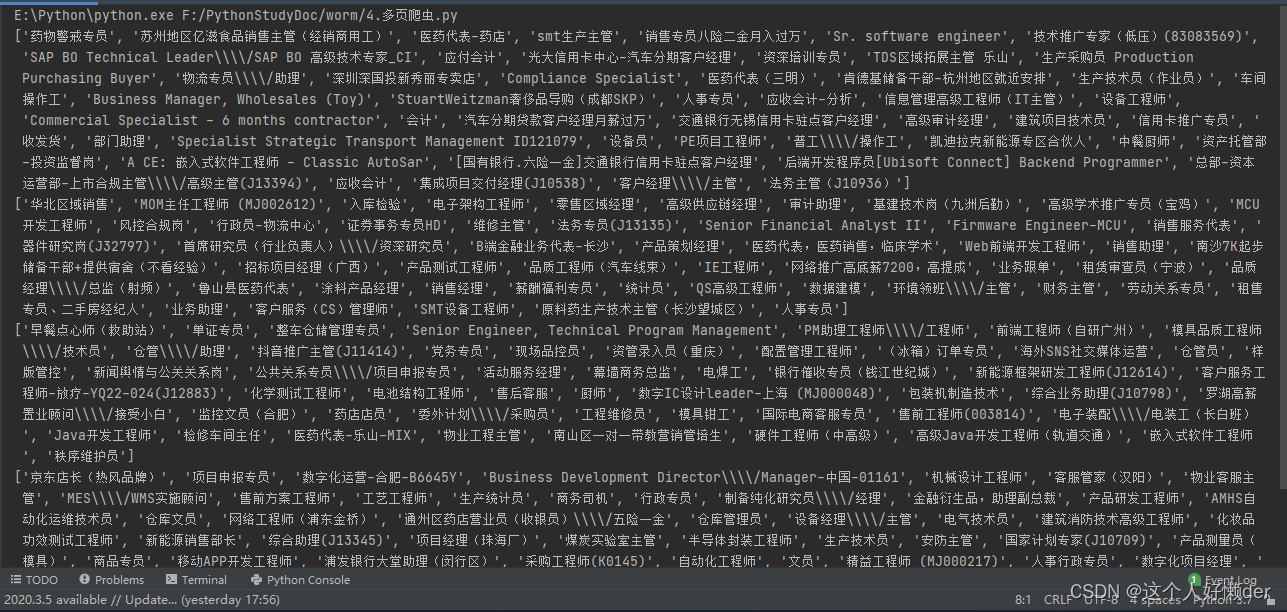
可以看到有四个列表,多页爬取成功。
pandas存放数据
使用pandas库将获取的内容放在表格中:
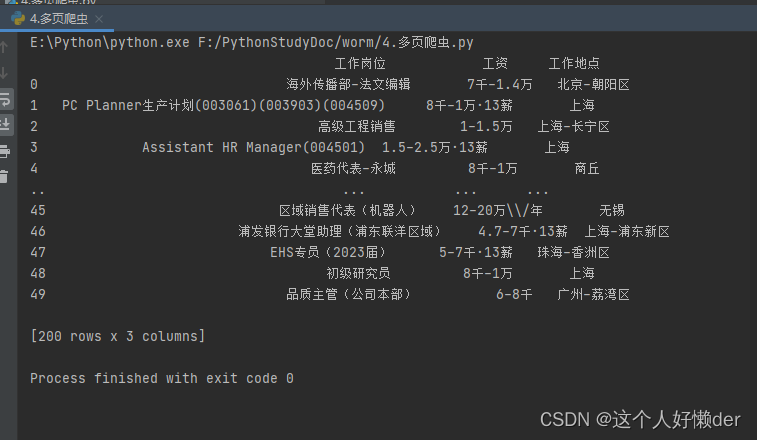
import requests #requests请求 from lxml import etree #XPath提取 import re from pandas import DataFrame import pandas as pd joball=DataFrame() for i in range(1,5): url='https://search.51job.com/list/000000,000000,0000,00,9,99,+,2,'+str(i)+'.html' rest=requests.get(url) #获取网页信息 rest.encoding="gbk" #进行编码防止乱码 root=etree.HTML(rest.text) #将获取的文本进行转换,方便使用XPath获取节点 work=root.xpath('//script[@type="text/javascript"]/text()') #查找到有目标信息的节点 work=str(work) JobName=re.findall(r'.*?"job_name":"(.*?)","job_title".*?',work) #工作岗位 Salary=re.findall(r'.*?"providesalary_text":"(.*?)","workarea".*?',work) #工资 WorkSpace=re.findall(r'.*?"workarea_text":"(.*?)","updatedate".*?',work) #工作地点 job_info=DataFrame([JobName,Salary,WorkSpace]).T job_info.columns=['工作岗位','工资','工作地点'] joball=pd.concat([joball,job_info]) print(joball)
获取了200行,只是中间一部分被折叠起来了。
将获取的内容导出:加入代码
joball.to_csv('51job.csv')在工程文件夹下就可以发现这个文件,里面就是刚刚获取的信息。