gpt 语言模型
GPT-3 has takeover the NLP world in a very short period of time. It has proved the theory that increasing number of parameters will increase the accuracy of model.
GPT-3在很短的时间内接管了NLP世界。 从理论上证明了增加参数数量将提高模型的准确性。

什么是语言模型? (What is Language Model?)
Language model tries to predict the next word given the m words. It assigns the probability to the next word which makes the sentence more probable.
语言模型会尝试根据给定的m个单词来预测下一个单词。 它将概率分配给下一个单词,使句子更有可能出现。
什么是GPT-3? (What is GPT-3?)
It’s the successor of GPT-2 language model which has highest number of parameters to trained. GPT-3 model is created by OpenAI and it proves that the language model size is proportional to the accuracy and hence, more we increase the model size more the accuracy.
它是GPT-2语言模型的后继者,该模型具有要训练的最多参数。 GPT-3模型是由OpenAI创建的,它证明了语言模型的大小与准确性成正比,因此,我们增加模型大小的准确性越多。
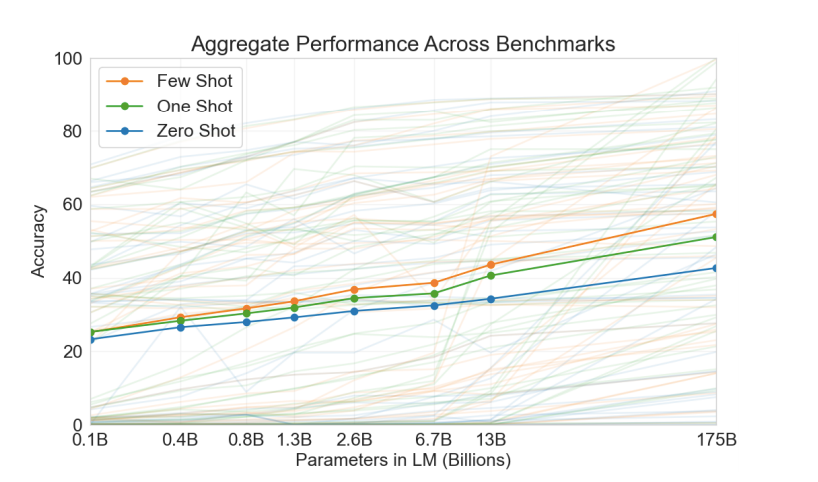
As we can see from the graph that increasing number of language models proportionally increases the accuracy. Therefore, it is possible to obtain higher accuracy by adding more parameters to the model.
从图中可以看出,越来越多的语言模型会成比例地提高准确性。 因此,可以通过向模型添加更多参数来获得更高的精度。
GPT-3 is the largest language model present with 175 billion parameters 10 times bigger than the Turing-NLG model which has 17 billion parameters.
GPT-3是目前最大的语言模型,具有1,750亿个参数,是具有170亿个参数的Turing-NLG模型的10倍。
In this blog, we’ll go through the research paper of GPT-3 and will deduce why it’s just the another language model and why it cannot be called as the model that can imitate human at any level. It’s the best language model present but not the model that can understand and can learn the human language.
在此博客中,我们将遍历GPT-3的研究论文,并推论为什么它只是另一种语言模型,以及为什么不能将其称为可以在任何水平上模仿人类的模型。 它是目前最好的语言模型,但不是可以理解和学习人类语言的模型。
测试模型的设置: (Settings on which model is tested:)
Few-Shot (FS) refers that few examples are given to the model along with the task descriptions. So instead of full-fledged dataset for the specific task the model was given description along with some k example and then was asked the question. k examples was in range from 10 to 100 and the model was not allowed to do any weight change based on the example. The advantage was that the model does not require large dataset to learn the specific task but still the accuracy was not comparable to the state-of-the-art task specific models.
很少(FS)表示很少将示例与任务描述一起提供给模型。 因此,不是为特定任务提供完整的数据集,而是为模型提供了描述以及一些k示例,然后提出了问题。 k个示例的范围是10到100,并且不允许基于该示例对模型进行任何重量更改。 优点是该模型不需要大量数据集即可学习特定任务,但准确性仍无法与最新的特定任务模型相提并论。

One-Shot (OS) is similar to few-shot where k is equal to one. So the models need to understand the task based on one example only. This type of learning is similar to how human learns. In this too, model was not allowed to change weights.
一击(OS)类似于几次射击,其中k等于1。 因此,模型仅需要基于一个示例来了解任务。 这种学习方式类似于人类的学习方式。 在这种情况下,也不允许模型更改权重。

Zero-Shot (ZS) has value of k as zero. No example is provided to the model. Model needs to understand just from the task description what the model needs to do.
零射(ZS)的k值为零。 没有为模型提供示例。 模型仅需要从任务描述中了解模型需要做什么。
The accuracy of the model was compared to the state-of-the-art task specific model also known as fine-tuning models. The disadvantage of this model is just that they need huge task-specific dataset to be trained on. This type of models are task specific and will perform poorly on other tasks.
将模型的准确性与最新的任务特定模型(也称为微调模型)进行了比较。 该模型的缺点在于,他们需要训练庞大的特定于任务的数据集。 这种类型的模型是特定于任务的,在其他任务上的执行效果会很差。

训练数据集 (Training Dataset)
The dataset used by GPT-3 was huge almost containing everything present on the internet. The did the fuzzy search on the training dataset to remove anything related to the test and validation dataset which will help to give more accurate results. They created this dataset from merging various dataset and through crawling.
GPT-3使用的数据集非常庞大,几乎包含了Internet上存在的所有内容。 他们对训练数据集进行了模糊搜索,以删除与测试和验证数据集相关的所有内容,这将有助于提供更准确的结果。 他们通过合并各种数据集并通过爬网来创建此数据集。

训练过程 (Training Process)
They used gradient noise scale to find out the right batch size to be used. The architecture was similar to the GPT-2 with minor modifications.
他们使用梯度噪声标度来找出要使用的正确批次大小。 该架构与GPT-2相似,只是做了一些小改动。
结果 (Results)
The GPT-3 was evaluated on various natural language tasks and on various datasets.
在各种自然语言任务和各种数据集上对GPT-3进行了评估。
语言建模,完形填空和完成任务 (Language Modeling, Cloze, and Completion Tasks)
Lambada数据集 (Lambada Dataset)
Context: “Yes, I thought I was going to lose the baby.” “I was scared too,” he stated, sincerity flooding his eyes. “You were ?” “Yes, of course. Why do you even ask?” “This baby wasn’t exactly planned for.” Target sentence: “Do you honestly think that I would want you to have a _______ ?” Target word: miscarriageIn this dataset the context is given than sentence is given to the model with the blank which needs to be completed by the model. The word chosen should be based on the context given rather than the past knowledge model has. This dataset proves that model can understand the context and provides the answers based on that.
在该数据集中 ,给定上下文而不是给句子提供模型,空格由模型来完成。 选择的单词应基于给定的上下文,而不是过去的知识模型。 该数据集证明模型可以理解上下文,并基于此提供答案。
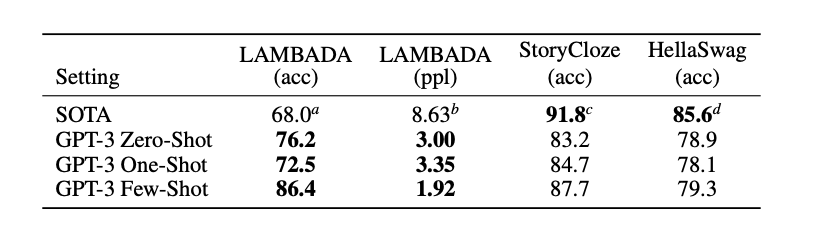
As we can see that all settings of GPT-3 surpasses the accuracy of SOTA on this dataset. GPT-3 one-shot accuracy is less than the accuracy of zero-shot. We can imply that GPT-3 predicts more accurately with any example than when given one example. It is possible that GPT-3 had the knowledge of the dataset through training set and in few-shot method the model can know which weights to use more accurately. Because when you do google search for Yes, of course. Why do you even ask?"This baby wasn't planned for.” you can get various links with answer to the statement.
我们可以看到,在该数据集上,GPT-3的所有设置都超过了SOTA的准确性。 GPT-3单发精度低于零发精度。 我们可以暗示GPT-3的任何示例预测都比给出的示例更准确。 GPT-3可能通过训练集掌握了数据集,并且通过几次射击方法,模型可以知道要更准确地使用哪些权重。 因为,当您执行google搜索时 Yes, of course. Why do you even ask?"This baby wasn't planned for.” Yes, of course. Why do you even ask?"This baby wasn't planned for.” 您可以获得各种链接以及对声明的回答。
HellaSwag数据集 (HellaSwag Dataset)
A woman is outside with a bucket and a dog. The dog is running around trying to avoid a bath. She … A. rinses the bucket off with soap and blow dry the dog’s head.
B. uses a hose to keep it from getting soapy.
C. gets the dog wet, then it runs away again.
D. gets into a bath tub with the dog.These are multiple choice questions in which model needs to select the most suitable option. This dataset is used to test the common sense of the model. The GPT-3 FS achieved the accuracy of 79.3 around 6 percent below the SOTA which is fine-tuned multi-task model ALUM.
这些是多项选择题,模型需要选择最合适的选项。 该数据集用于测试模型的常识。 GPT-3 FS的精确度比SOTA(精调的多任务模型ALUM)低7%左右,达到79.3%。
故事完结数据集 (Story Cloze Dataset)
Context: Sammy’s coffee grinder was broken. He needed something to crush up his coffee beans. He put his coffee beans in a plastic bag. He tried crushing them with a hammer. Right Ending: It worked for Sammy. Wrong Ending: Sammy was not that much into coffee.These dataset is also used for common sense test. In this the model is given the context and the model has to predict the right ending from the two options provided. GPT-3 FS has achieved the accuracy of 87.7% well below the SOTA but has shown a great improvement in GPT-3 ZS by 10%.
这些数据集也用于常识测试。 在这种情况下,为模型提供了上下文,并且模型必须根据提供的两个选项来预测正确的结局。 GPT-3 FS的精度达到了87.7%,远低于SOTA,但GPT-3 ZS却显示出10%的巨大改进。
已关闭的书问答 (Closed Book Question Answering)
Open Book Question Answering is used in search engines which can search the relevant information and can extract the answer from it. In closed book the model is not allowed to search and doesn’t have any context or excerpt provided to know what model is actually asking.
在搜索引擎中使用“开卷提问”,该引擎可以搜索相关信息并从中提取答案。 在closed book该模型不允许搜索,并且没有提供任何上下文或摘录来知道实际在询问什么模型。
This dataset is a fact based that is the answer are the facts rather than any context depended. So, we can say that this dataset tests the memory of the model as GPT-3 is trained on wikipedia text too.
该数据集是基于事实的,答案是事实而不是依赖于上下文的事实。 因此,可以说,当GPT-3也在维基百科文本上进行训练时,该数据集也测试了模型的内存。

The model is asked question and is expected the answer based on facts. Excerpt is only for our knowledge it is not feed to the model. Multiple answers are also allowed for example, if the answers is name Bill Gates the answer can be Bill, Gates, Bill Gates, Microsoft founder Bill Gates.
该模型是一个问题,应根据事实来回答。 摘录只是出于我们的知识,它不能提供给模型。 例如,还允许有多个答案,如果答案的名称是Bill Gates,则答案可以是Bill,Gates,Bill Gates,Microsoft创始人Bill Gates。
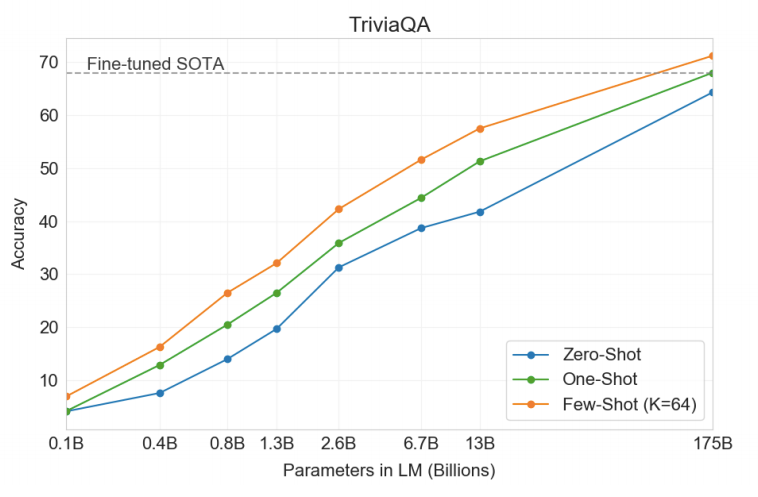
We can see that GPT-3 has surpassed the fine-tuned open book SOTA. So we can say that GPT-3 is more efficient as an information retrieval engine for facts.
我们可以看到,GPT-3已经超过了经过微调的开放书SOTA。 因此,可以说GPT-3作为事实信息检索引擎更为有效。
WebQuestions (WebQA)
WebQuestions (WebQA)
This dataset is similar to TriviaQA but the dataset consist of the real-world questions asked by the actual users in real world. So, it tests the model in real world scenario.
此数据集与TriviaQA相似,但数据集由现实世界中实际用户提出的现实问题组成。 因此,它可以在实际场景中测试模型。

The GPT-3 FS has similar accuracy to the fine-tuned SOTA models.
GPT-3 FS的精度与微调的SOTA模型相似。
Natural Questions (NQs)
自然问题 (NQs)
This dataset is provided by the Google for testing the Question Answering model in real world. All the questions are searched by users on the google search. In the model tries to predict the paragraph from the wikipedia page which may contain the answer to the question. And model also predicts the short answer which will the exact answer to the question. But the short answer must be present in the paragraph selected also known as long answer.
该数据集由Google提供,用于在现实世界中测试问答模型。 用户在google搜索中搜索了所有问题。 在模型中,尝试从Wikipedia页面中预测可能包含问题答案的段落。 模型还预测了简短的答案,这将是对该问题的确切答案。 但是短答案必须出现在所选的段落中,也称为长答案。

The accuracy fo GPT-3 FS setting is 29.9% well below the fine-tuned SOTA. This dataset tests the limit of model to retain the information of wikipedia.
GPT-3 FS设置的精度为29.9%,远低于微调的 SOTA。 该数据集测试模型的限制,以保留Wikipedia的信息。
Through this tests we can say that the bigger the model more the information can be retained and hence, higher the accuracy.
通过此测试,我们可以说模型越大,可以保留的信息越多,因此准确性也越高。
翻译 (Translation)
The accuracy of GPT-3 in language translation is a surprise. As 93% words of the training set are English. So, the model will be biased toward English language more than the other language. GPT-3 is the upgrade over GPT-2 and is tested for machine translation for languages French, German, and Romanian other than English.
GPT-3在语言翻译中的准确性令人惊讶。 培训中有93%的单词是英语。 因此,该模型将比其他语言更偏向英语。 GPT-3是GPT-2的升级版本,并且经过了针对机器翻译的测试,测试语言包括英语,法语,德语和罗马尼亚语。
The model efficiency for the Machine Translation task is measured in BLEU rather than as accuracy. We’ll look into it some other time.
机器翻译任务的模型效率以BLEU衡量,而不是准确性。 我们将在其他时间进行调查。
BLEU is calculated on 6 language pairs:
BLEU是根据6种语言对计算得出的:
- English to French (En→Fr) 英语译成法语(En→Fr)
- French to English (Fr→En) 法语译成英语(Fr→En)
- English to German (En→De) 英文译成德文(En→De)
- German to English (De→En) 德语到英语(De→En)
- English to Romanian (En→Ro) 英语到罗马尼亚语(En→Ro)
- Romanian to English (Ro→En) 罗马尼亚文译成英文(Ro→En)
The training dataset had around 92.5% of words in English, 1.8% of words in French, 1.5% in German and 0.16% of words in Romanian.
训练数据集包含约92.5%的英语单词,1.8%的法语单词,1.5%的德语单词和0.16%的罗马尼亚单词。
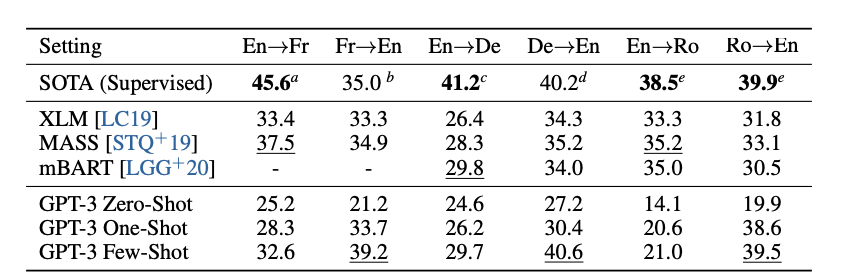
We can see that the GPT-3 model is almost or better than the SOTA when translating any text to English.
我们可以看到,将任何文本翻译成英文时,GPT-3模型几乎或优于SOTA。
Zero-Shot Example:
零拍示例:
Q: What is the {language} translation of {sentence} A: {translation}.As we can see, only the description text is provided to the model along with the sentence and the targeted language.
如我们所见,只有描述文本以及句子和目标语言被提供给模型。
One- and Few-Shot Example:
一枪少打的例子:

For Few-Shot around 64 examples were given to the model before asking the question.
对于Few-Shot,在提出问题之前,给模型提供了大约64个示例。
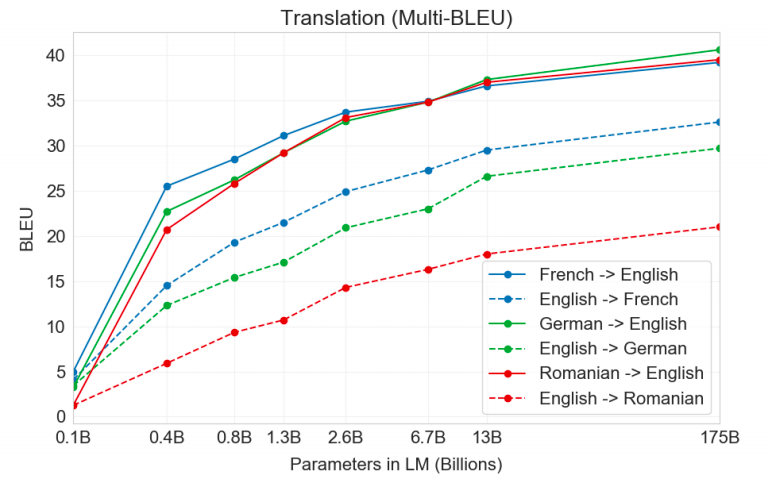
As we can see as the data increased the BLEU score of the model increased. The score of English->French is greater than English->German which is greater than English->Romanian and is proportional to the percentage of words present of each language in the dataset.
正如我们所看到的,随着数据的增加,模型的BLEU得分也随之增加。 英语->法语的分数大于英语->德语的分数,英语->德语的分数大于英语->罗马尼亚语的分数,并且与数据集中每种语言存在的单词的百分比成比例。
Winograd风格的任务 (Winograd-Style Tasks)
This type of tasks involves determining what the pronoun used in the sentence resemble. The pronoun is ambiguous for the computer but unambiguous for humans. The partial evaluation method was used for evaluation about which you can read here.
这类任务涉及确定句子中使用的代词相似。 代词对计算机来说是模棱两可的,而对人类来说则是歧义的。 部分评估方法用于评估,您可以在此处阅读。
"sentence": "The city councilmen refused the demonstrators a permit because [they] feared violence.", "answer1": "The demonstrators"
"answer0": "The city councilmen""sentence_switched": "The demonstrators refused the city councilmen a permit because [they] feared violence."The answer for the sentence must be answer1 but once we switch the sentence the answer should also change to answer0
句子的答案必须是answer1但是一旦我们切换句子,答案也应该更改为answer0
Winograd Dataset
Winograd 数据集

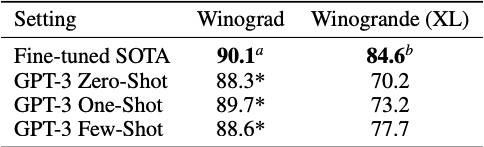
GPT-3 performance on this dataset is below SOTA. Some examples of the test set was also found in the training dataset.
此数据集上的GPT-3性能低于SOTA。 在训练数据集中还可以找到一些测试集的示例。
Winogrande Dataset
Winogrande 数据集
This dataset is similar to winograde dataset but more advanced and difficult.
该数据集类似于winograde数据集,但更高级,更困难。

常识推理 (Common Sense Reasoning)
This test is conducted to test how the model applies the common sense in real world questions. For example, if we ask the human what’s the time? Human will respond the current time such as 5:30 PM rather than explain the concept of time. We check whether the model can answer such questions using common sense. Previous all tasks where mostly dependent on the data and probability rather than how much the model actually understands the inner concepts. Here, we test how much the model understand the human language.
进行此测试以测试模型如何在现实世界中的问题中应用常识。 例如,如果我们问人类现在几点了? 人类将响应当前时间,例如5:30 PM,而不是解释时间的概念。 我们检查模型是否可以使用常识回答此类问题。 优先执行所有任务,这些任务主要取决于数据和概率,而不是模型实际了解内部概念的程度。 在这里,我们测试了模型对人类语言的理解程度。
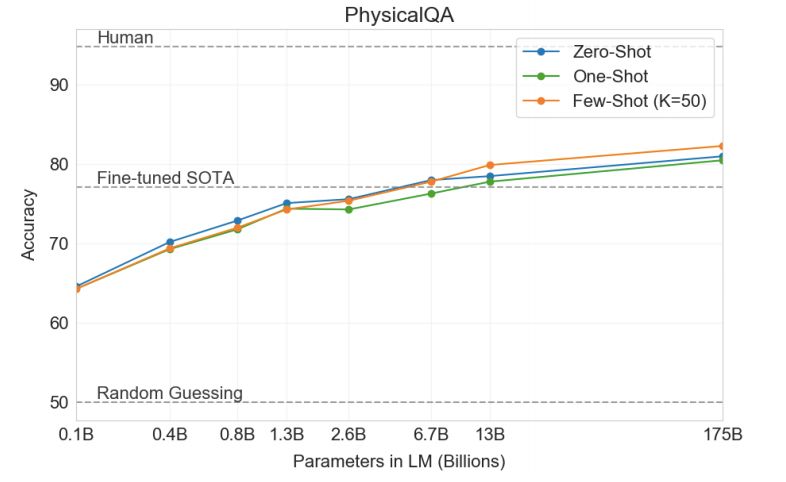
PhysicalQA Dataset
PhysicalQA 数据集

For all types of tuning GPT-3 beats the SOTA on this dataset with a small margin. But the confidence on this result was not much due to possibly data contamination.
对于所有类型的调整,GPT-3在此数据集上击败SOTA的幅度很小。 但是由于可能的数据污染,对该结果的信心并不高。
Our analysis flagged PIQA for a potential data contamination issue (despite hidden test labels), and we therefore conservatively mark the result with an asterisk.
我们的分析将PIQA标记为潜在的数据污染问题(尽管隐藏了测试标签),因此我们保守地用星号标记结果。
AI2 Reasoning Challenge Dataset (ARC)
This dataset consist of the multiple-choice science questions of 3rd to 9th grade. The dataset is divided into parts: 1. Easy version 2. Challenge version. The challenge set consist of the questions which were wrongly answered by the retrieval-based algorithms.
该数据集包含3至9年级的多项选择题。 数据集分为以下部分:1.简单版本2.挑战版本。 挑战集由基于检索的算法错误回答的问题组成。
GPT-3 performance on this dataset was very much below the SOTA achieved by UnifiedQA.
该数据集上的GPT-3性能大大低于UnifiedQA达到的SOTA。

OpenBookQA Dataset
OpenBookQA 数据集
This dataset are similar to open book tests and the answer to the question is combination of fact and common sense.
这个数据集类似于开卷考试,问题的答案是事实和常识的结合。


As GPT-3 is trained on all the text present on internet it’s a good question to answer that whether GPT-3 has applied common sense to answer this questions and not just retrieved the information available somewhere in the training dataset.
由于对GPT-3进行了互联网上所有现有文本的培训,因此很好地回答GPT-3是否已运用常识回答了这一问题,而不仅仅是检索了培训数据集中某处的可用信息。
阅读理解 (Reading Comprehension)
Here, we test the ability of the model on understanding the passage and answering the questions based on the information provided in the passage.
在这里,我们测试了该模型在理解文章和根据文章中提供的信息回答问题方面的能力。
In this dataset the passage is provided and the questions asked are based on the conversation among humans.
在此数据集中,提供了段落,并且根据人类之间的对话提出了问题。

This dataset is very interesting as in this the student does not see the passage but asks questions which are answered by the teacher. The student asks the basic question and teacher answer with some extra context based on which the student asks another question. The interaction ends if the teacher is not able to answer too many question or if student does not ask any relevant question.
该数据集非常有趣,因为在这种情况下,学生看不到段落,而是提出了由老师回答的问题。 学生提出基本问题,并根据教师提出的其他问题回答老师的其他问题。 如果老师不能回答太多问题或学生没有提出任何相关问题,则互动结束。

In this dataset a model must resolve references in a question, perhaps to multiple input positions, and perform discrete operations over them such as addition, counting, or sorting.
在此数据集中,模型必须解析问题中的引用(可能是对多个输入位置的引用),并对它们执行离散操作,例如加法,计数或排序。
Passage: Although the movement initially gathered some 60,000 adherents, the subsequent establishment of the Bulgarian Exarchate reduced their number by some 75%.Question: How many adherents were left after the establishment of the Bulgarian Exarchate?Correct Answer: 15,000As we can see here the model needs to understand the passage and question in order to answer it correctly and it should also perform some operations on it rather than just retrieve the information.
正如我们在这里看到的那样,该模型需要理解段落和问题才能正确回答,并且还应该对其进行一些操作,而不仅仅是获取信息。
In this along with the questions for which the answer is present in the passage the questions for which there is no answer present in the passage are also asked. The model is expected not to answer the question for which the passage does not contain the answer.
在此,以及在段落中存在答案的问题以及在段落中不存在答案的问题。 期望模型不回答段落不包含答案的问题。

This dataset consists the passages from the English exams for middle and high school Chinese students in the age range between 12 to 18 designed to evaluate the students reasoning capability. The dataset is divided into two sections: 1. RACE-m dataset consist of the passages of middle school 2. RACE-h dataset consists the passages of high school.
该数据集包含12至18岁年龄段的中高中学生英语考试的段落,旨在评估学生的推理能力。 数据集分为两部分:1. RACE-m数据集由中学阶段构成。2. RACE-h数据集由中学阶段构成。


强力胶 (SuperGLUE)
It can be considered as the standardized test for all the NLP model which are able to perform multiple language modeling tasks. It gives the single result based on how model performed in different tasks. As the result is ingle value it’s easy to compare with different models on same scale.
可以将其视为所有能够执行多种语言建模任务的NLP模型的标准化测试。 它基于模型在不同任务中的执行方式给出单个结果。 由于结果是ingle值,因此很容易与相同规模的不同模型进行比较。
This benchmark includes the following tasks:
该基准测试包括以下任务:
- Question Answering (QA) 问题解答(QA)
- Natural Language Inference (NLI) 自然语言推论(NLI)
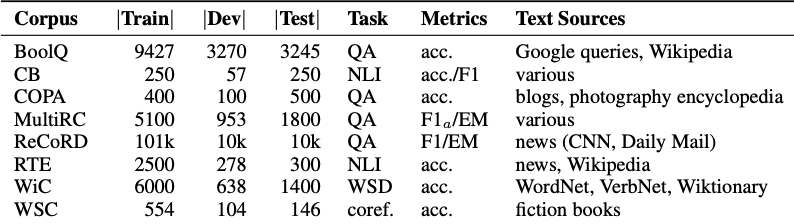
Dataset’s used:
数据集的使用:
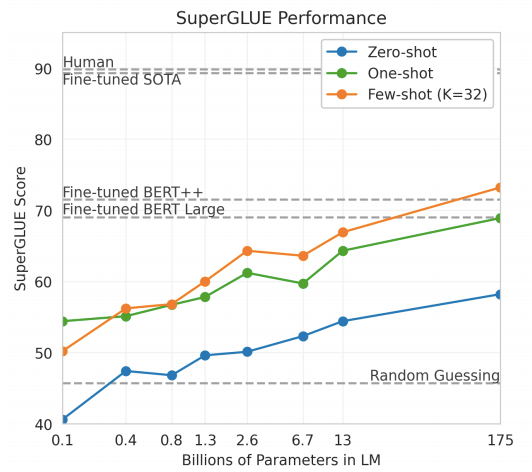
For GPT-3 few-shot tuning 32 examples were used in context.
对于GPT-3,上下文中使用了少量调整的32个示例。
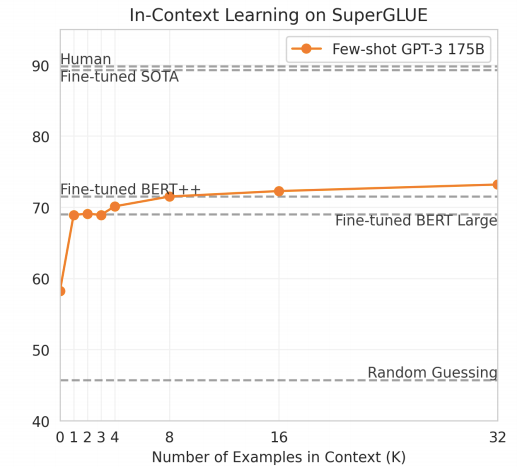
As we can see more the examples the accuracy of GPT-3 increased but in very small number. GPT-3 FS surpassed the fine-tuned BERT-Large when 8 examples were given in context.
我们可以看到更多示例,但GPT-3的准确性有所提高,但数量很少。 在上下文中给出了8个示例时,GPT-3 FS超过了经过微调的BERT-Large。
自然语言推论(NLI) (Natural Language Inference (NLI))
In this type of task the model determines the relation between two sentences. It’s a classification type of problem where model classifies the second sentence into three classes: 1. Supports the first sentence 2. Contradicts the first sentence 3. Neutral
在这种类型的任务中,模型确定两个句子之间的关系。 这是问题的分类类型,其中模型将第二个句子分为三类:1.支持第一个句子2.与第一个句子相反3.中立
RTE dataset is used for testing the model on NLI task. Along with RTE more difficult Adversarial NLI (ANLI) was used for testing the GPT-3 model. IN ANLI GPT-3 performed slightly better than random chance but well below the SOTA.
RTE数据集用于在NLI任务上测试模型。 与RTE一起使用更困难的Adversarial NLI(ANLI)来测试GPT-3模型。 在ANLI中, GPT-3的表现略高于随机机会,但远低于SOTA。
ANLI is divided into three sets based in difficulty: round 1, round 2, round 3.
ANLI根据难度分为三组:第一轮,第二轮,第三轮。



综合和定性任务 (Synthetic and Qualitative Tasks)
In this the GPT-3 is tested to perform various synthetic tasks such as arithmetic operations, rearranging and unscrambling the letters in a word, solve SAT-style analogy problems, using new words in a sentence, correcting English grammar, and news article generation.
在此测试中,对GPT-3进行了测试,以执行各种综合任务,例如算术运算,重新排列和解构单词中的字母,解决SAT风格的类比问题,使用句子中的新单词,纠正英语语法以及生成新闻文章。
算术 (Arithmetic)
In this the ability of GPT-3 to perform arithmetic operations is tested. Various arithmetic operations such as addition, subtraction and multiplication are tested.
在此测试了GPT-3执行算术运算的能力。 测试了各种算术运算,例如加法,减法和乘法。
The arithmetic problems consists of the following types:
算术问题包括以下类型:
- 2 digit addition (2D+) 2位加法(2D +)
- 2 digit subtraction (2D-) 2位减法(2D-)
- 3 digit addition (3D+) 3位加法(3D +)
- 3 digit subtraction (3D-) 3位减法(3D-)
- 4 digit addition (4D+) 4位加法(4D +)
- 4 digit subtraction (4D-) 4位减法(4D-)
- 5 digit addition (5D+) 5位加法(5D +)
- 5 digit subtraction (5D-) 5位减法(5D-)
- 2 digit multiplication (2Dx) 2位数乘法(2Dx)
- One-digit composite (1DC) 一位数复合(1DC)
The model performs better in few-shot setting than other type of settings. And, as the number of digits increases the accuracy reduces greatly. GPT-3 has made a huge jump on this set than the smaller models.
与其他类型的设置相比,该模型在几次拍摄设置中的性能更好。 并且,随着位数的增加,准确性大大降低。 与较小的型号相比,GPT-3在该装置上有了巨大的进步。
Examples of the questions asked to GPT-3:Q: What is 17 minus 14?
Q: What is (2 * 4) * 6?
Q: What is 95 times 45?
Q: What is 98 plus 45?
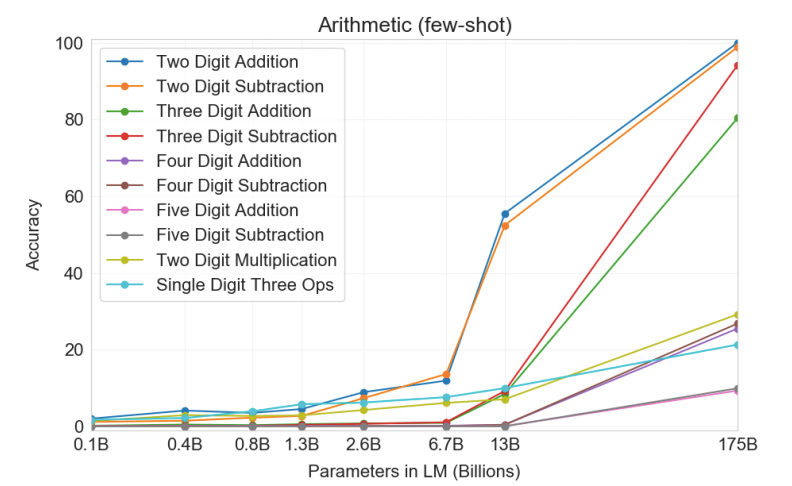
As the digit gets increased the accuracy of the model decreases exponentially. And more the complex operations such as multiplication and composite equations the model performance is degraded.
随着数字的增加,模型的准确性呈指数下降。 而且,复杂的运算(例如乘法和复合方程)还会降低模型性能。
The model may have memorized the smaller digit arithmetic operations as they are available more frequently on the internet than the big numbers. The training set was searched for “<NUM1> + <NUM2> = ” and “<NUM1> -<NUM2> = ” and only 0.8% and 0.1% matched were found for the test cases. But, it is possible that the training set may have “forty-two + twenty-three equals sixty-five” or “adding forty-two to twenty-three gives sixty-five” type of equations and the model may have mapped the integer and operations to this strings.
该模型可能已经记住了较小的数字算术运算,因为在互联网上比大数字更容易使用它们。 在训练集中搜索“ <NUM1> + <NUM2> =”和“ <NUM1>-<NUM2> =”,对于测试用例仅找到0.8%和0.1%匹配。 但是,训练集可能具有“三十二+二十三等于六十五”或“将四十二与二十三相加得到六十五”等式,并且该模型可能已经映射了整数和对该字符串的操作。
The model was inspected on wrong results and was found that it works incorrectly when the operation includes carry.
检查了该模型的错误结果,结果发现当该操作包含进位时,该模型无法正常工作。
单词加扰和处理任务 (Word Scrambling and Manipulation Tasks)
In this various operations are done on the word and is given as an input to the model. The model needs to predict the original word.
在这种情况下,对单词进行各种操作,并将其作为模型的输入。 该模型需要预测原始单词。
This tasks include 5 type of tasks:
此任务包括5种类型的任务:
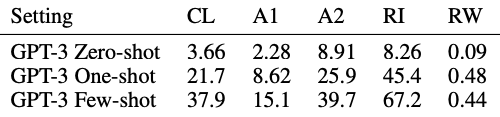
Cycle letters in word (CL) — The letters of the words are cycled and model is asked to find the original word.
单词中的循环字母(CL) - 循环单词的字母,并要求模型查找原始单词。

2. Anagrams of all but first and last characters (A1) — All the letters of the word are scrambled except the first and last letter. The model needs to output the original word.
2. 除第一个和最后一个字符外的所有字母的拼音(A1) —除第一个和最后一个字母外,单词的所有字母都被打乱。 该模型需要输出原始单词。

3. Anagrams of all but first and last 2 characters (A2) — All the letters of the word are scrambled except the first 2 and last 2 letters. The model need to output the original word.
3. 除前2个字符外的所有字母的拼音(A2) -除前2个和后2个字母以外,所有单词的字母都被打乱。 该模型需要输出原始单词。

4. Random insertions in word (R1) — A random punctuation or space is inserted between letters and model needs to predict the original word.
4. 在单词中随机插入(R1) -在字母之间插入随机标点或空格,并且模型需要预测原始单词。
5. Reversed words (RW) — The word is spelled backwards and the model needs to predict the original word.
5.逆向单词(RW) -单词被反向拼写,模型需要预测原始单词。

The model performs poorly in zero-shot setting and shows average performance in one-shot setting. The model was given 100 examples for few-shot setting in which it performs considerably well.
该模型在零连拍设置下表现不佳,在一次连拍设置下显示出平均性能。 该模型为100个示例提供了几次曝光设置,在其中表现良好。
SAT类比 (SAT Analogies)
In this the model needs to answer the questions based on analogy. This questions were asked in SAT the college entrance exam. The random guessing accuracy is 20% while the average score of college students is 57%. GPT-3 few-shot setting achieves 65.2% of accuracy and one-shot setting achieves 59.1% accuracy well above the student average. The accuracy of zero-shot setting is 53.7%. For few-shot setting number of examples given were 20.
在这个模型中,模型需要根据类比回答问题。 SAT高考中曾问过这些问题。 随机猜测的准确性为20%,而大学生的平均分数为57%。 GPT-3单发设置可达到65.2%的准确度,单发设置可达到59.1%的准确度,远高于学生的平均水平。 零位设置的准确性为53.7%。 对于少量设置,给出的示例数为20。

新闻文章生成 (News Article Generation)
In this the model is provided the title and subtitle using which it needs to write an article of around 200 words. The model was tested on few-shot setting only as model was not able to understand whether it needs to write an article or need to respond as follow up tweet.
在该模型中,模型提供了标题和副标题,使用该标题和副标题需要编写大约200个单词的文章。 仅在模型无法理解是否需要撰写文章或需要作为后续推文来响应的情况下,才对该模型进行了几次测试。
The GPT-3 performance is compared with the control model which deliberately produces bad articles. Humans were used to distinguish the article whether it was human made or made by model. Humans accurately detected the article was generated by control model with 86% accuracy. But as the model size increased the human were able to detect with 52% accuracy that the article was generated by the model.
将GPT-3的性能与故意产生不良物品的控制模型进行了比较。 使用人类来区分商品是人工制作还是模型制作。 人类可以准确地检测到该物品是由控制模型生成的,准确率为86%。 但是随着模型尺寸的增加,人类能够以52%的准确率检测到该物品是由模型生成的。
Most articles which were detected as made by the model contained wrong factual information or had a repeated sentences and unusual phrasing.
该模型检测到的大多数文章包含错误的事实信息,或者具有重复的句子和不寻常的措词。
The model was also tested on articles with 500 words but still the human were able to distinguish with human articles by 52% only.
该模型还在500个单词的文章上进行了测试,但人类仍然只能与人类文章区分开52%。

When you google any sentence from the above article you’ll get various articles on the some topic with similar sentences. It’s possible that GPT-3 as trained on whole internet may just have summarised all the articles of the relevant topic in less than 500 words. Instead of generating articles it maybe just merging various sentences from different articles hence, making articles similar to humans. We will know whether the GPT-3 can generate the article if we provide the title very unique.
当您用Google搜索上述文章中的任何句子时,您将获得具有该句子相似主题的各种文章。 在整个互联网上接受培训的GPT-3可能只用不到500个单词就总结了相关主题的所有文章。 与其生成文章,不如仅仅合并来自不同文章的各种句子,从而使文章类似于人类。 如果我们提供非常独特的标题,我们将知道GPT-3是否可以生成该文章 。

学习和使用新词 (Learning and Using Novel Words)
In this the model is tested if it can use the word in a sentence after defining the word once.
在此模型中,测试了模型一次定义单词后是否可以在句子中使用单词。
So to test the model on this task the word definition is given once so one-shot setting but the example is provided for the each word defined hence, few-shot setting with respect to task description.
因此,要在此任务上测试模型,只需一次设置单词定义即可,但是为定义的每个单词提供了示例,因此,相对于任务描述仅设置了几下。

The words were human made and hence, model has no prior knowledge of that. We can see the model generated all the sentences logical using the defined word.
这个词是人为制造的,因此模型没有先验知识。 我们可以看到模型使用定义的单词生成了所有符合逻辑的句子。
纠正英语语法 (Correcting English Grammar)
The model is tested if it ca predict the wrong grammar and can modify the sentence with right grammar. The model is tested on few-shot setting.
测试模型是否可以预测错误的语法并可以用正确的语法修改句子。 该模型在几次拍摄设置下进行了测试。

As we can see, the model is tested on very basic grammar instead of complicated grammar such as clauses. It’ll be good to see the model performance on such bad grammar as it’s a complicated task even for humans.
如我们所见,该模型是在非常基本的语法而不是诸如子句之类的复杂语法上进行测试的。 最好能看到模型的语法如此糟糕,因为即使对于人类来说,这也是一项复杂的任务。
衡量和防止记忆基准 (Measuring and Preventing Memorization Of Benchmarks)
As the training dataset was generated through crawling the internet it is possible that the training dataset may contain various test set examples. If it happens then the confidence on the accuracy reported by the model on various tasks may be unreliable.
由于训练数据集是通过爬网生成的,因此训练数据集可能包含各种测试集示例。 如果发生这种情况,则模型在各种任务上报告的准确性的置信度可能不可靠。
The training dataset was searched for the test set example and the documents are considered match if N words are similar among both the sets. N is equal to the 5th percentile example length in words of each sets. Smaller value of N caused huge number of matches which were found illogical. So minimum value of N was kept 8 and maximum 13. N words are matched or the whole sentence is matched depending on the minimum length. If the match is found the example is considered as dirty otherwise clean example.
在训练数据集中搜索了测试集示例,如果两个集合中的N个单词相似,则认为文档匹配。 N等于每组单词的第5个百分位数示例长度。 N的值较小会导致大量的不符合逻辑的比赛。 因此,N的最小值保持为8,最大值为13。根据最小长度,匹配N个单词或匹配整个句子。 如果找到匹配的示例,则认为该示例不干净,否则为干净示例。
GPT-3 was tested for various tasks on the clean dataset and the accuracy is compared with the original score. If the accuracy almost matches then it means that contamination even if present does not effect the model accuracy. If the accuracy is lower than the original score implies that contamination is inflating the results.
对GPT-3进行了干净数据集上各种任务的测试,并将准确性与原始分数进行了比较。 如果精度几乎匹配,则意味着即使存在污染也不会影响模型精度。 如果准确度低于原始分数,则表明污染加剧了结果。
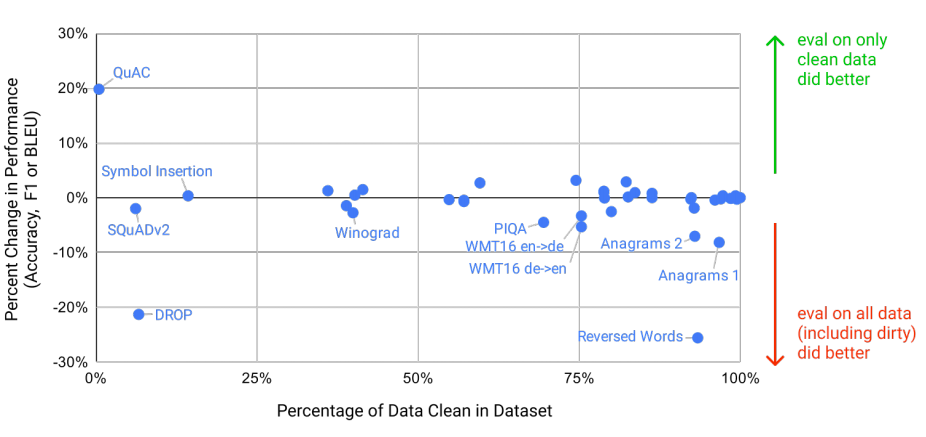
For dataset QuAC 0% of clean data is present in the dataset and still the accuracy changed positively by 20% which must mean there was something wrong with it. They found around 90% of dataset contaminated. But, after further analysis deduced that the training set included only passages but not question and answers.
对于数据集QuAC,数据集中存在0%的干净数据,但准确度仍发生了20%的正变化,这必须表示它有问题。 他们发现约90%的数据集被污染。 但是,经过进一步的分析得出的结论是,训练集仅包括段落而不是问答。
GPT-3 has various limitations and there is still chance of improvements in fields such as text synthesis. GPT-3 is based on the training dataset and hence, can’t think of it’s own. If majority of humans has some bias towards gender, race, religion then the model will also represent those bias. For more limitations and bias you can read here. MIT technology review also published a blog on limitations of GPT-3.
GPT-3具有各种局限性,在文本合成等领域仍有改进的机会。 GPT-3基于训练数据集,因此无法想到它本身。 如果大多数人对性别,种族,宗教有偏见,那么该模型也将代表这些偏见。 要了解更多限制和偏见,请点击此处 。 MIT技术评论还发布了有关GPT-3局限性的博客。
GPT-3 is model which just predicts which word should come next. It does not understand the context and does not understand the actual meanings of the word. The model lacks logical reasoning and common sense reasoning. The model output can be changed just by tweaking the dataset.
GPT-3是仅预测下一个单词的模型。 它不了解上下文,也不了解单词的实际含义。 该模型缺乏逻辑推理和常识推理。 只需调整数据集即可更改模型输出。
翻译自: https://towardsdatascience.com/gpt-3-just-another-language-model-but-bigger-1add6e9277fa
gpt 语言模型