什么是知识图谱
这是一个基于这个优秀而全面的知识图谱教程的教程。
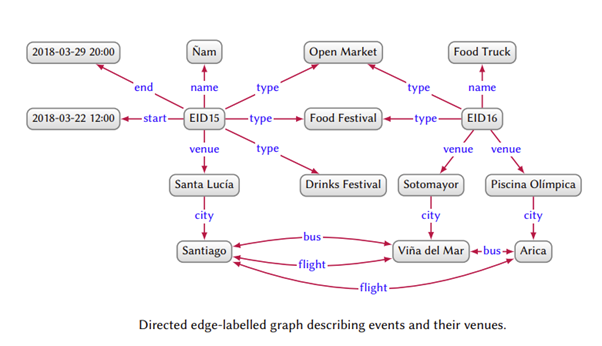
来源:Aidan et al., Knowledge Graphs, https://arxiv.org/pdf/2003.02320.pdf
一、说明
在我们周围的现实世界中,物体和它们之间的关系可以用图形来表示。一组对象以及它们之间的联系自然地表示为图形。
知识图谱 (KG) 知识图谱是一种抽象数据结构,用于表示从多个数据源中提取的结构化相关信息。例如,幼稚园可用于组织互联网上的大量相关知识,并整合企业内部存在的数据。KG中表示的信息应易于人类理解和验证。
- KG 是有向标记的图数据结构,由 4 个组件组成——一组节点、一组连接节点的边、一组每个边一个的标签,以及一个将边与标签关联的赋值函数。
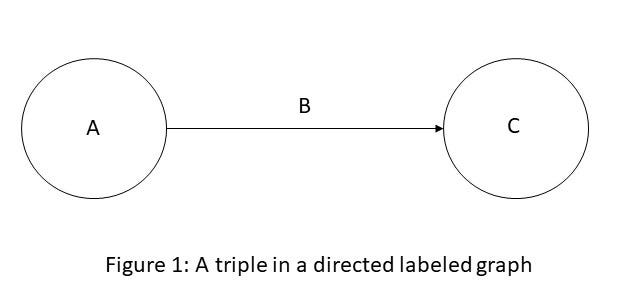
来源:https://ai.stanford.edu/blog/introduction-to-knowledge-graphs/
在上面的有向标记图中,A 和 C 是表示实体 A 和 C 的节点,边 E= (A,C) 具有标签 B。如上图所示,将标签 B 分配给边缘 E 可以写成三元组 (A、B、C)。在这个三元组中,我们可以将 A、B 和 C 分别称为三元组的主语、谓语和宾语。
- 图中的实体可以是人、地点、公司、计算机或椅子等物体、事件、抽象概念,即构成我们物理或精神世界的实体。节点和边具有关联的域特定含义。
- 边缘的标签表示它们连接的实体之间的关系/语义。例如,两个人之间的友谊关系,两个对象之间的容器和包含关系,两个句子文本之间的语义相似性。
- 知识图谱可以使用本体来定义实体、它们的属性以及它们之间允许的关系,以实现逻辑推理,以检索显式存储的隐式知识。
- 使用图表来存储相关信息并不是什么新鲜事。有向图已被用于表示数据流图、决策图、状态图、概念图、描述逻辑、规则语言、概率图形模型、贝叶斯网络等。
- 最近,KG在改进搜索引擎、推荐系统、聊天机器人等应用以及自然语言处理和计算机视觉领域的其他应用方面取得了成功。
- 知识图谱可以用作 ML 算法的输入来表示领域知识。这些 KG 首先需要转换为称为嵌入的数值向量。知识图谱嵌入技术用于将实体和关系转换为低维向量表示,从而允许它们通过机器学习 (ML) 算法进行处理。以 KG 表示的领域知识可以改进 ML 算法的预测。
- 人工智能代理使用知识图谱(语义网络)来表示现实世界的信息,并使用这些信息来推理现实世界。
- KG也可以通过自然语言处理和计算机视觉应用程序作为输出产生,例如,用于实体识别、对象检测、图像理解、视觉问答的任务。
- 您可以将知识图谱视为 ML 算法用来存储和组织结构化但相关的信息的思维导图。
二、图形数据模型
图像、文本、物质分子、社交网络、引文网络、图片中的对象、编程代码、机器学习模型、数学方程式等数据都可以表示为图形。我们可以用几种图表的形式对数据进行建模:
1. 有向边缘标记图:
此图具有一组节点以及这些节点之间的一组边。节点表示实体,边表示这些实体之间的二进制关系。
与符合架构的标准关系模型 (RDBMS) 相比,将数据建模为图形可以更轻松地集成来自新源的数据。图形数据模型也比以树的形式组织数据(如 XML 或 JSON 格式)更好,因为图形组织不需要按层次结构组织数据,并且允许循环。
2. 异质图:
异质图或异质信息网络是每个节点和边被分配一个类型的图。如果一条边连接两个相同类型的节点,则该边是齐次的,否则它是异质的。此图允许根据节点类型对节点进行分区。
3. 属性图
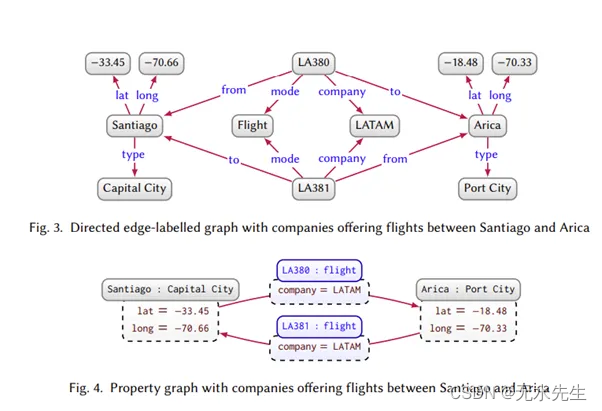
来源:Aidan et al., Knowledge Graphs, https://arxiv.org/pdf/2003.02320.pdf
除了有向、标记图的 4 个分量以及与图的节点和边关联的标签之外,属性图还可以使用属性值对来建模更复杂的关系。
像 Neo4j 这样的流行图形数据库使用属性图对数据进行建模。
4. 图形数据集
图形数据集是命名图形和默认图形的集合。命名图是图 ID 和图的一对,默认图没有 ID,默认引用。这些图形数据集用于管理和查询由互联网上资源描述格式图的相互链接文档组成的链接数据。
5. 超图
超图是一种图,其中复边连接集合(复集)而不是节点对。
6. 图形商店
图形存储是用于存储和索引图形以实现高效查询的数据库。可以将有向的标记图以单个 arity 3 关系的形式存储在关系数据库中,或者作为每个属性的二元关系或给定类型的实体(属性表)的 n 元关系。图形存储还允许在多台计算机上分发图形。
三、查询图形数据
图形查询语言,如SPARQL(用于RDF图),G-CORE(用于属性图)使用常见的基元,如基本图模式、关系运算符、路径表达式等,用于从图中检索匹配数据。
1. 基本图形模式
基本图模式就像一个模板,用于与更大的数据图进行匹配。就像数据图一样,基本图模式有节点和边,它有变量,这些变量充当你正在查询的未知值的占位符。基本图形模式还包括匹配和成功标准。匹配是基本图模式中的变量与数据图中的实际值之间的映射。成功是指基本图模式中的变量与数据图中相应的常量值之间的成功匹配。
2. 复杂的图形模式
复杂图模式使用关系代数算子(如投影、选择、重命名(一元运算符)或连接、并集、差分(二元运算符))组合和操作基本图模式的结果。为了处理重复的结果,查询语言使用两种语义 - Bag 语义(保留重复项)或 Set 语义(消除重复项)。
3. 导航图模式
可以在使用 Graph 查询语言编写的查询中使用路径表达式。路径表达式是一种正则表达式,它允许在两个节点之间匹配任意长度的路径。
为了构建路径表达式,我们使用以下规则:
- 带有标签的单条边表示从一个节点到另一个节点的直接路径 (R)。
- 我们可以使用运算符组合路径表达式,例如,
对于路径 r:
- r^ 表示反向路径(相反方向)
- r* 表示路径 r 的零次或多次重复
- r1|r2 表示路径 r1 或 r2 的分离。
- r1.r2 表示路径 R1 和 R2 的顺序串联。
四、知识图谱的架构
- 语义模式建立了知识图谱中使用的术语(词汇)背后的含义。这样就可以使用这些定义的术语对图形数据进行推理。架构可以定义类来对图中的实体进行分类,它可以捕获类之间的关系。该架构还可以定义图形中边缘标签(属性)的含义。
- 评估架构可确保图中的数据完整并遵守特定的规则和约束。大规模知识图谱通常包含多样化且不完整的数据。验证有助于确保实体存在基本信息。验证架构定义对数据的约束。定义验证架构的常用方法是通过形状。形状以一组节点为目标,并指定对其属性的约束(例如,允许的值数、数据类型)。
- Emergent Schema 是一种通过发现数据图中的固有结构来自动从知识图谱中提取结构的技术。
4.1 知识图谱中的身份
- 标识用于消除知识图谱中实体的歧义。为每个节点分配唯一标识符可确保在将外部数据集成到知识图谱时不会发生命名冲突。例如,使用数字对象标识符 (DOI) 用于文档,ORCID iD 用于研究人员,ISBN 用于书籍,Alpha-2 代码用于国家/地区。也可以通过将节点链接到外部来源(例如,维基百科页面)来提供身份,以提供消除歧义的参考点。
4.2 数据类型
知识图谱可以使用多种数据类型——数字、字符串、布尔值、空间点、时间值。
4.3 知识图谱的词汇化
- 词汇化是指将人类可读标签、注释添加到知识图谱以提高可读性的过程。
- 知识图谱通常使用全局唯一标识符 (GUID) 来表示实体。这些标识符可以是人类可读的(例如,chile:Santiago),也可以是设计上不可人类可读的(例如,维基数据中的wd:Q2887)
4.4 存在节点
存在节点表示涉及知识图谱中未知实体的关系。这些节点表示为空白圆圈。它们捕获了实体之间的关系,而不会对实体的存在产生歧义。
4.5 知识图谱中的上下文
知识图谱中的大多数事实都是上下文相关的,即它们仅在特定上下文(上下文事实)中是真实的。例如,
- 时间背景:事件发生在特定的时间范围内(例如,印度自 1947 年以来一直是一个独立国家)。
- 地理背景:例如,日本的洪水。
- 来源上下文:有关数据来源的信息(例如,来自指定维基百科条目的特定节点上的数据)。
上下文充当特定数据的真实范围,它阐明了数据被视为有效的条件。上下文可以在知识图谱中以不同的粒度应用:
- 单个节点(例如,城市存在的特定时间)
- 单个边(例如,基于源的连接的有效性)
- 边集(子图)
可以指定上下文:
1. 直接就像图表中的任何其他数据点一样。
2. 作为再现——以一般方式对陈述(或关于边缘)进行陈述。
3. 作为更高层次的表示,使用命名图和属性图直接在边缘结构中对上下文进行编码。
4. 上下文和推理注释 - 注释定义了代表特定上下文域的数学模型。然后,这些模型可用于这些上下文中的自动推理。
4.6 从知识图谱中提取演绎知识
演绎可用于从知识图谱中表示的信息中获取知识。机器需要正式的规则和前提来像人类一样进行推论。这些规则定义了从一组给定的语句(蕴涵制度)中可以逻辑上得出的结论。
捕获这些规则的两种方法是模式中的子类关系和本体。
本体
本体是特定上下文(域)中术语的正式定义。例如,事件本体可以指定事件具有一个场地和开始时间,也可以允许多个场地和开始时间。
- 本体包含有关知识图谱中的解释、个体、属性、类和其他特征的信息。
- 本体根据定义的术语指导知识图谱中的数据建模。它们通过建立基于本体定义的规则来自动化蕴涵。它们通过对术语的共同理解,提高了单个知识图谱中的一致性和多个图之间的互操作性。
- 本体论还指示图中的蕴涵。我们说,当且仅当前一个图的任何模型也是后一个图的模型时,一个图需要另一个图。也就是说,后一个图在前一个图上没有新信息,因此作为前一个图的逻辑结果成立。
知识图谱中演绎推理的推理规则
- 推理规则是一种捕获 if-then 样式关系以进行自动推理的方法。
- 这些规则由主体(条件)和头部(结论)组成。如果身体模式与数据图中的子图匹配,则需要头部模式(被视为有效推论)。
- 这些规则根据本体论条件捕获蕴涵,并在知识图谱中实现自动推理。
- 通过将规则迭代应用于图形,将所需的信息添加回去,直到无法生成新信息,这称为具体化。然后可以直接查询生成的图形。
- 规则语言示例 — Datalog、Horn Clauses、OWL 2RL/RDF。
知识图谱的描述逻辑 (DL)
- DL 将知识结构中元素的含义形式化。
- DL 是建立在三个元素之上的一系列逻辑:个体、类(概念)和属性(角色)
4.7 从知识图谱中提取归纳知识
提取演绎知识涉及使用规则,但归纳知识提取涉及从一组给定的输入观察中概括模式,然后可用于进行预测。
- 我们可以应用无监督学习、自监督或监督学习来从图中学习。
- 在无监督方法的情况下,我们可以在图上使用聚类算法来检测社区、查找中心节点、边等。我们可以使用自监督学习来学习图嵌入(知识图谱的低维数字表示)。嵌入的图形将输入边映射到输出合理性分数,指示边为真的可能性。在监督学习的情况下,我们可以使用图神经网络来学习图结构并做出预测。
虽然上述技术学习数值模型,但我们可以使用符号学习来学习符号模型,即以自监督的方式从图中以规则或公理形式出现的逻辑公式。
图形分析
图形分析技术 -
1. 中心性 - 用于测量最重要的节点或边。具体的节点中心性度量包括度、介数、接近度、特征向量、RageRank、HITS、Katz 等。
2. 社区检测 — 用于识别图中的社区,即内部连接比与图其余部分连接更密集的子图。
3. 连通性 — 估计图形的连通性。
4. 节点相似性 — 通过节点在其邻域内的连接方式找到与其他节点相似的节点。
5. 路径查找 — 查找图形中指定节点之间的路径。
许多框架可用于分布式大规模图形分析。例如,Apache Spark (GraphX)、GraphLab、Pregel、Shark 等。
数据图分析策略:
1. 投影 — 通过选择性地从数据图中选择一个子图来投影图,从中删除所有边缘元数据。
2. 加权 — 根据某些函数将边缘元数据转换为数值。
3. 转换 — 将图转换为较低的 arity 模型。
4. 自定义 — 更改分析程序以合并边缘元数据。
图形查询语言可以投影或转换适合特定分析任务的图形。SPARQL、Cypher 和 G-CORE 等查询语言允许输出图,此类查询可用于选择子图进行分析。分析还用于对大型图形的查询结果进行排名,选择最重要的结果呈现给用户。
4.8 通过知识图谱嵌入和图神经网络使用图的监督学习
知识图谱嵌入
- 知识图谱嵌入技术在连续的低维向量 (50>=d>=1000) 空间中创建图的密集表示,可用于机器学习任务。
- 图嵌入由每个节点的实体嵌入组成:一个具有 d 维的向量,我们用 e 表示;以及每个边标签的关系嵌入:一个具有 d 维的向量,我们用 R 表示。这些向量的目标是抽象和保留图中的潜在结构。
要计算图形嵌入,最常见的方法是:
- 给定一条从节点 S 到节点 O 的边,标签为 P,使用评分函数接受节点 S 的实体嵌入、边标签 P 的实体嵌入和节点 O 的实体嵌入,并计算边的合理性:它为真的可能性有多大。
- 给定一个数据图,然后目标是计算维度 D 的嵌入,根据给定的评分函数,使正边(通常是图中的边)的合理性最大化,并最小化负示例的合理性(通常是图中节点或边标签已更改的边,使它们不再出现在图中)。
- 然后,使用上述过程生成的嵌入可用于许多低级任务,这些任务涉及计算它们的图形的节点和边缘标签。
图嵌入的常用技术:
- 平移模型 — 这些模型将边缘标签(关系)解释为节点(实体)之间的转换。该技术学习实体和关系的向量表示,旨在最小化源实体和关系向量之和与正示例的目标实体向量之间的距离。它最大化了反面示例的距离。
- 张量分解模型提取近似于图结构的潜在因子。知识图谱可以编码为 3 阶张量,其中元素表示具有特定关系的实体之间的连接。该张量可以分解为实体和关系的因子或嵌入。例如,实体向量和关系向量之间的元素相乘可用于对边的合理性进行评分并创建嵌入。
- 嵌入的神经模型 — 神经模型使用非线性函数来计算图边的合理性分数。例如,一种使用卷积核的方法,通过将每个向量包装在几行上并连接两个矩阵,从边和关系生成矩阵。串联矩阵用作一组 (2D) 卷积层的输入,该卷积层返回特征图张量。特征图张量被矢量化并使用参数化线性变换投影到 d 维中。然后根据该向量和表示边的向量的点积计算合理性分数。
- 像 GPT 和 Gemini 这样的语言模型会计算它们训练的文本的嵌入。这些语言模型可用于计算图形嵌入。然而,图形和文本序列之间是有区别的——图形由三个术语的无序序列集(即一组边)组成,但自然语言中的文本由任意长度的术语序列(即单词的句子)组成。基于文本嵌入模型 Word2Vec,有一个模型 RDF2Vec,它对图形执行有偏的随机游走,并将路径(遍历的节点和边缘标签的序列)记录为“句子”,然后将其作为输入输入到 word2vec 模型中。另一个模型 KGloVe 基于 GloVe 模型。与 GloVe 模型一样,KGlove 认为在文本窗口中经常出现的单词更相关,KGloVe 使用个性化的 PageRank25 来确定与给定节点最相关的节点,然后将其结果输入到 GloVe 模型中。
- 蕴涵感知嵌入模型创建联合嵌入,同时考虑数据图及其本体(规则)。
五、图神经网络
通过创建图嵌入,我们可以将图与现有的机器学习模型一起使用。但是,我们也可以调整自定义 ML 模型,以将图形作为输入和输出。其中一种模型被称为图神经网络(GNN)。
图神经网络是一种神经网络,它将有向图作为输入,其中节点和边与特征向量相关联,这些特征向量可以捕获节点和边缘标签、权重等。
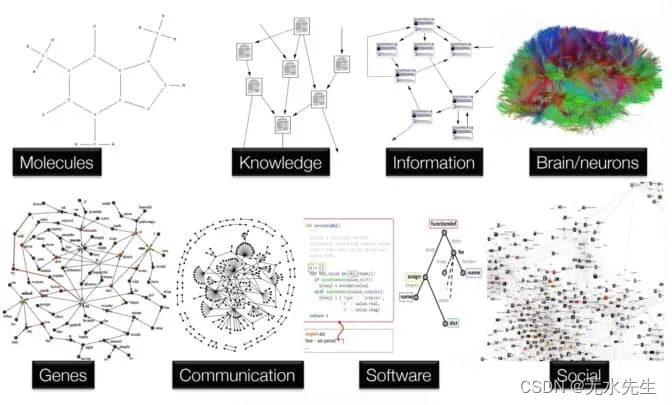
图片来源: What Are Graph Neural Networks? | NVIDIA Blogs
神经网络已经对应于加权的有向图,其中节点 serbes 作为人工神经元,边缘作为加权连接。但是,传统的前馈神经网络和可以处理图形的神经网络之间存在差异。在传统的前馈神经网络中,节点的顺序层是同构的,其中一层中的每个节点都连接到下一层中的所有节点。图是异质的,由实体之间的关系及其边所代表的确定。
图神经网络(GNN)是一种基于数据图拓扑的神经网络架构。即,节点根据数据图连接到它们的邻居。
GNN 支持特定任务的端到端监督学习:给定一组标记示例,GNN 可用于对图的元素或图本身进行分类。GNN 已被用于对编码化合物、图像、文档等中的对象的图形进行分类;以及预测流量、构建推荐系统、验证软件等。
给定标记示例,GNN 甚至可以取代图算法;例如,GNN已被用于以监督方式查找知识图谱中的中心节点。
图上的预测任务一般有三种类型:图级、节点级和边缘级。在图形级任务中,我们预测整个图形的单个属性。对于节点级任务,我们预测图中每个节点的一些属性。对于边缘级任务,我们希望预测图形中边缘的属性或存在。
GNNS的类型:
- 递归图神经网络: 递归图神经网络将有向图作为输入,其中节点和边与特征向量相关联,这些特征向量可以捕获节点和边缘标签、权重等。这些特征向量在整个过程中保持固定。图中的每个节点还与一个状态向量相关联,该状态向量根据来自节点相邻节点的信息递归更新,即相邻节点的特征和状态向量以及使用参数函数(称为转移函数)延伸到/从它们延伸到/从它们延伸的边缘的特征向量。第二个参数函数称为输出函数,用于根据节点自身的特征和状态向量计算节点的最终输出。这些函数以递归方式应用于固定点。这两种参数函数都可以使用神经网络实现,其中,给定图中一组部分监督节点,即标有其所需输出参数的节点,用于过渡和输出函数,可以学习最接近监督输出的节点。为了确保收敛到固定点,应用了某些限制,即在每次应用函数时,数值空间中的点会靠得更近。
- 卷积图神经网络:对于图神经网络,将小核应用于图像局部区域的核心思想应用于图中的节点及其邻居。这种GNN被称为卷积图神经网络(ConvGNNs)。转换函数在ConvGNN中通过卷积实现。图的光谱或空间表示可以与ConvGNN一起使用,以定义邻域或注意力机制,可用于学习其特征对当前节点最重要的节点。
- 递归GNNs(RecGNNs)将邻域的信息递归聚合到一个固定点,并以统一的步骤使用相同的函数参数,而ConvGNNs应用固定数量的卷积层,ConvGNN的不同卷积层可以在每个不同的步骤中应用不同的核/权重。
Kowledge 图上的符号学习
- 知识图谱嵌入和图神经网络等监督技术通过图学习数值模型。但这种模型缺乏可解释性。
- 符号学习是一种更易于解释的方法。它涉及学习符号语言中的假设,以“解释”一组给定的正边和负边。然后,这些假设作为可解释的模型,可用于进一步的演绎推理。规则挖掘和公理最小化是两种类型的符号学习。
六、创建知识图谱
- 用于创建知识图谱的方法取决于领域、所涉及的参与者、应用程序、可用数据源。
- 您可以以增量方式构建知识图谱,从初始核心开始,该核心可以根据需要从其他来源增量扩充。
- 例如,最初我们可以只包括我们清楚地知道的主要实体及其关系,并在我们发现实体和关系时逐步添加它们。
6.1 为您的知识图谱收集数据:
- 您需要与其他人(员工、领域专家、公众)合作来收集数据。
- 对于文本数据,我们可以使用来自报纸、书籍、科学期刊、社交媒体等的语料库等文本源来获取数据。文本数据需要通过标记化、词性标记、依赖解析、命名实体识别、实体链接、关系提取等步骤进行预处理。
标记数据源:您可以按如下方式从 Web 中提取标记数据:
- 基于包装器的提取,用于从标记文档中查找和提取有用的信息。Web 表提取,用于提取嵌入在 HTML 网页中的表。
- 深层网络爬虫以搜索网络论坛上的信息。
- 从结构化数据源(CSV、JSON、XML、关系数据库)收集数据。您需要将关系数据库中的关系映射到图形,类似 JSON、XML 通常具有树结构,您需要将其映射到图形元素,您也可以从其他图形中提取图形的知识。
6.2 为您的知识图谱创建模式/本体
一旦数据被提取出来创建你的知识图谱,你需要使用本体工程方法或自动学习本体为它创建一个模式。有几种方法可以系统地手动创建基于数据的本体。本体的自动学习不需要人工干预。
七、评估知识图谱的质量
- 准确性:准确性是指图中节点和边编码的实体和关系正确表示现实生活中现象的程度。准确性可以进一步细分为三个维度:句法准确性、语义准确性和及时性。
- 句法准确性是数据相对于为域和/或数据模型定义的语法规则的准确程度。
- 语义准确性是数据值正确表示现实世界现象的程度。
- 及时性是知识图谱当前与现实世界状态保持同步的程度。
2. 覆盖率 — 覆盖率是指避免遗漏与领域相关的元素,否则可能会产生不完整的查询结果或蕴涵、有偏见的模型等
- 完整性:指所有必需信息在特定数据集中存在的程度。它包括模式完整性、属性完整性、填充完整性、链接性完整性。
- 代表性侧重于评估知识图谱中包含/排除的内容中的高级偏见。该指标假设它是理想知识图谱的样本,并询问该样本的偏差程度。
3. 连贯性:知识图谱与模式级别定义的形式语义和约束的符合或连贯程度。
- 一致性意味着知识图谱在所考虑的特定逻辑蕴涵方面没有(逻辑/形式)矛盾。
- 有效性意味着知识图谱没有约束冲突,例如由形状表达式捕获。
4. 简洁性:指仅包含以简洁易懂的方式表示的相关内容。
- 简洁性是指避免包含与域无关的架构和数据元素
- 表征简洁性是指内容在知识图谱中紧凑表示的程度。
- 可理解性是指人类用户可以毫不含糊地解释数据的难易程度。
八、知识图谱的细化
一旦创建了幼稚园,它就有了通过完成缺失的信息和修复不一致的知识来改进的空间。
- 完成:填补知识图谱中缺失的边缘,即被认为是正确的边缘,但知识图谱既没有给出也没有包含。这是使用链接预测技术完成的,例如使用知识图谱嵌入的一般链接预测、规则/公理挖掘、类型链接预测、身份链接预测(预测身份链接涉及搜索引用同一实体的节点)。此类技术通常使用值匹配器和上下文匹配器。值匹配器确定给定属性上两个实体(字符串、数字、日期、对象等)的值的相似程度。上下文匹配器考虑基于各种节点和边的实体的相似性。
九、知识图谱的更正
当完成在知识图谱中发现新边缘时,更正会识别并删除知识图谱中现有的错误边缘。两种主要的纠正方法是事实验证和不一致修复。
- 事实验证:事实验证的任务涉及为事实/边缘分配合理性或真实性分数,通常在 0 到 1 之间。理想的事实检查函数将理想的知识图谱假定为基本事实,并将返回 1 表示存在于基本事实中的事实,返回 0 表示不存在于基本事实中的事实。
- 不一致修复:由于公理(例如,不相交性),知识图谱中可能会出现不一致。我们需要检测并修复这种不一致之处。可以通过将实体包含在两个不相交的类中,或者通过删除类型赋值来修复简单的不一致。可以使用自动修复方法。
十、发布您的知识图谱
- 如果您希望公开发布您的知识图谱,请遵循 FAIR 原则 — 可查找性、可访问性、互操作性、可重用性和链接数据原则:(1) 使用国际化资源标识符 (IRI) 作为事物的名称。(2) 使用 HTTP IRI,以便查找这些名称。(3) 查找 HTTP IRI 时,提供有关 IRI 使用标准数据格式命名的实体的有用内容。(4) 在返回的内容中包含相关实体的 IRI 链接。
十一、知识图谱的访问协议。
为了允许公众与您的知识图谱进行交互,您需要使用协议来定义代理可以发出的请求以及他们可以期望的响应。对于公共访问,该协议应该是开放的、免费的和普遍可实施的。KG 的一些访问协议是:
- 转储 — 知识图谱 (KG) 通常通过转储提供对其数据的访问。转储本质上是包含特定格式的知识图谱内容的文件(或文件集合)。转储提供了一种相对简单的方法,可以在特定时间点下载知识图谱的完整快照。转储文件的格式取决于知识图谱本身。常见的格式包括 RDF(资源描述框架)、JSON(JavaScript 对象表示法)和特定于某些知识图谱的自定义格式。
您可以使用以下方法获取 kG 的转储:
- 下载链接:直接在知识图谱网站上下载。
- API:知识图谱可以通过 API 提供对转储的编程访问。
- 请求访问:您可能需要直接联系知识图谱提供商以请求访问转储。
2. 节点查找:用于执行节点查找的协议接受节点 (id) 请求并返回描述该节点的(子)图
控制知识图谱的使用
- 许可:W3C 开放数字版权语言 (ODRL) 提供了一个信息模型和相关词汇表,用于指定与知识图谱相关的操作的权限、职责和禁令。
- 使用策略:您可以使用 WebAccessControl 框架限制对知识图谱部分的访问。
- 加密已发布知识图谱的部分内容。
- 对知识图谱的某些部分进行匿名化,以保护隐私。
十二、突出的知识图谱
- 打开知识图谱:
- DBpedia:DBpedia 项目旨在提取嵌入在维基百科文章中的半结构化数据的图形结构表示,从而能够以统一的方式集成、处理和查询这些数据。通过链接到外部开放资源,包括图像、网页和外部数据集(如 DailyMed、DrugBank、GeoNames、MusicBrainz、纽约时报和 WordNet),进一步丰富了生成的知识图谱。
- YAGO: Yet Another Great Ontology (YAGO) 从维基百科中提取图形结构数据,然后与 WordNet 的分层结构统一。
- WIkidata:维基数据是一个集中的、协作编辑的知识图谱,为维基百科和任意其他客户端提供数据。
- 特定领域的开放知识图谱 — OpenCitations、SciGraph、Microsoft Academic Knowledge Graph、LinkedGeoData、Bio2RDF。
2. 专有知识图谱
- 用于网络搜索的 Google Knowlegde Graph。
- 亚马逊、Airbnb、优步为商业构建了知识图谱。
- Meta和LinkedIn为社交媒体构建了知识图谱。
- Thompson Reuters、Accenture、Capital One、Wells Fargo 构建了金融知识图谱。
- IBM、阿斯利康为医疗保健行业制造了 KG。
十三、知识图谱研究的未来方向
知识图谱研究的目标是从不同的数据来源中提取最有价值的知识。
该研究涉及图数据库、知识表示、逻辑、机器学习、图算法、本体工程、数据质量、自然语言处理、信息提取、隐私和安全等领域。
KG研究的当前主题包括属性图的形式语义、上下文数据的推理和查询、基于相似性的查询松弛、形状归纳、上下文知识图谱嵌入、蕴涵感知知识图谱嵌入、表达图神经网络、规则和公理挖掘。目标是提高图形的可伸缩性、质量、多样性和可用性。
引用: