一、Task 任务调度执行流程
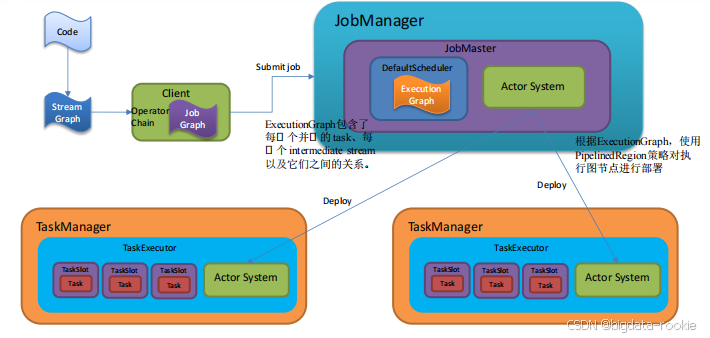
一、Graph 的概念
Flink 中的执行图可以分为四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图。
- StreamGraph:执行用户代码中的 env.execute() 方法后,根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph 经过优化(合并算子链、设置并行度、优化分区策略等)后生成 JobGraph, 是客户端提交给 JobManager 的数据结构。
- ExecutionGraph:JobManager 根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 JobGraph 的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个 TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
例如 example 里的 WordCount 并行度为 2 (Source 为 1 个并行度)的四层执行图的演变过程如下所示:
public static void main(String[] args) throws Exception {
// Checking input parameters
final MultipleParameterTool params = MultipleParameterTool.fromArgs(args);
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// get input data
DataStream<String> text = null;
if (params.has("input")) {
// union all the inputs from text files
for (String input : params.getMultiParameterRequired("input")) {
if (text == null) {
text = env.readTextFile(input);
} else {
text = text.union(env.readTextFile(input));
}
}
Preconditions.checkNotNull(text, "Input DataStream should not be null.");
} else {
System.out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
// get default test text data
text = env.fromElements(WordCountData.WORDS);
}
DataStream<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(value -> value.f0).sum(1);
// emit result
if (params.has("output")) {
counts.writeAsText(params.get("output"));
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
// execute program
env.execute("Streaming WordCount");
}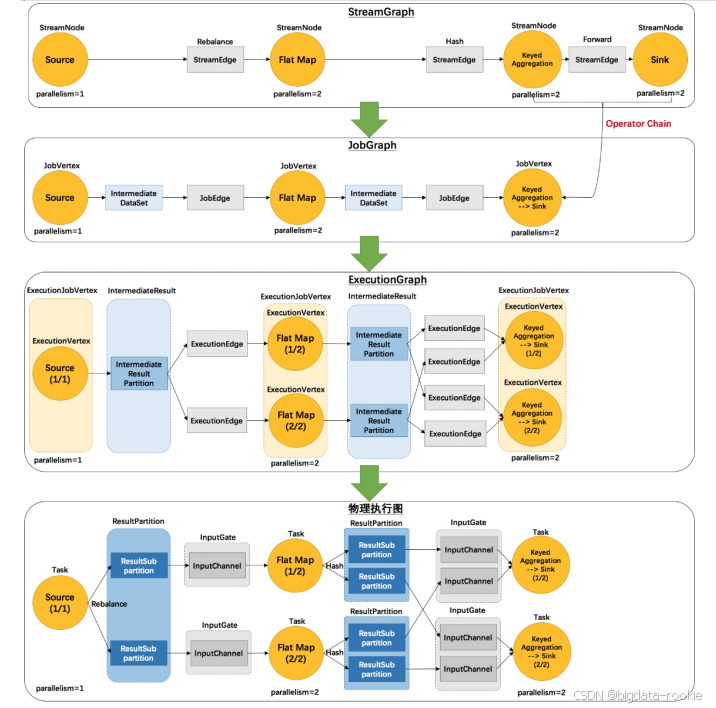
相关术语解释:
StreamGraph:
StreamNode:用来代表 operator 的类,并具有所有的相关属性,如并行度、入边和出边等。
StreamEdge:表示连接两个 StreamEdge 的边。
JobGraph:
JobVertex:经过优化后符合条件的多个 StreamNode 可能会 chain 在一起生成一个 JobVertex,即一个 JobVertex 包含一个或多个 operator,JobVertex 的输入是 JobEdge,输出是 IntermediateDataSet。
IntermediateDataSet:表示 JobVertex 的输出,经过 operator 处理产生的数据集。producer 是 JobVertex,consumer 是 JobEdge。
JobEdge:代表了 JobGraph 中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过 JobEdge 由 IntermediateDataSet 传递给目标 JobVertex。
ExecutionGraph:
ExecutionJobVertex:和 JobGraph 中的 JobVertex 一一对应。每个 ExecutionJobVertex 都有和并行度一样多的 ExecutionVertex。
ExecutionVertex:表示 ExecutionJobVertex 的其中一个并行子任务,输入是 ExecutionEdge,输出是 IntermediateResultPartition。
IntermediateResult:和 JobGraph 中的 IntermediateDataSet 一一对应。一个 IntermediateResult 包含多个 IntermediateResultPartition,其个数等于该 operator 的并行度。
IntermediateResultPartition:表示 ExecutionVertex 的一个输出分区,producer 是 ExecutionVertex,consumer 是若干个 ExecutionEdge。
ExecutionEdge:表示 ExecutionVertex 的输入,source 是 IntermediateResultPartition,target 是 ExecutionVertex。source 和 target 都只能是一个。
Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM 和 TM 之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接收者。
归纳:
- 由于每个 JobVertex 可以有多个 IntermediateDataSet,所以每个 ExecutionJobVertex 可以有多个 IntermediaResult,因此每个 ExecutionVertex 也可以包含多个 IntermediateResultPartition;
- ExecutionEdge 主要的作用是把 ExecutionVertex 和 IntermediateResultPartition 连接起来,表示它们之间的连接关系。
物理执行图:
ResultPartition:代表由一个 Task 生成的数据,和 ExecutionGraph 中的 IntermediateResultPartition 一一对应。
ResultSubPartition:是 ResultPartition 的一个子分区。每个 ResultPartition 包含多个 ResultSubPartition,其数目要由下游消费 Task 数和 DistributionPartition 来决定。
InputGate:代表 Task 的输入封装,和 JobGraph 中 JobEdge 一一对应。每个 InputGate 消费了一个或多个的 ResultPartition。
InputChannel:每个 InputGate 会包含一个以上的 InputChannel,和 ExecutionGraph 中的 ExecutionEdge 一一对应,也和 ResultSubpartition 一对一的相连,即一个 InputChannel 接收一个 ResultSubPartition 的输出。
二、Graph 生成的底层代码
2.1 StreamGraph 在 Client 生成
执行用户代码中的 StreamExecutionEnvironment.execute()
-> execute(getJobName())
-> execute(getSStreamGraph())
-> getStreamGraph(jobName,true)
StreamExecutionEnvironment.java
public StreamGraph getStreamGraph(String jobName, boolean clearTransformations) {
StreamGraph streamGraph = getStreamGraphGenerator().setJobName(jobName).generate();
if (clearTransformations) {
this.transformations.clear();
}
return streamGraph;
}
调用了 StreamGraphGenerator 的 generate() 方法
public StreamGraph generate() {
streamGraph = new StreamGraph(executionConfig, checkpointConfig, savepointRestoreSettings);
shouldExecuteInBatchMode = shouldExecuteInBatchMode(runtimeExecutionMode);
configureStreamGraph(streamGraph);
alreadyTransformed = new HashMap<>();
/*TODO transformations是一个list,依次存放了用户代码里的算子*/
for (Transformation<?> transformation: transformations) {
transform(transformation);
}
final StreamGraph builtStreamGraph = streamGraph;
alreadyTransformed.clear();
alreadyTransformed = null;
streamGraph = null;
return builtStreamGraph;
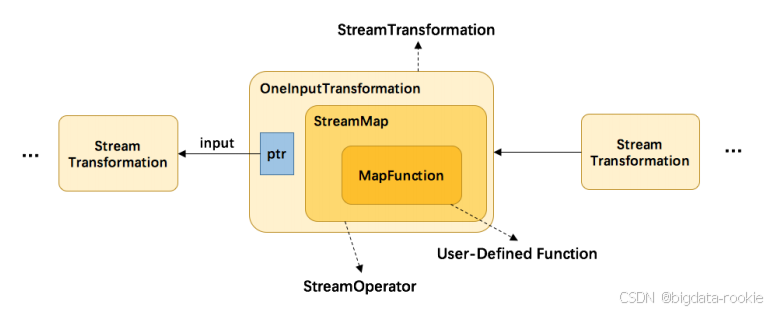
}一个关键的参数是 List<Transformation<?>> transformations。Transformation 代表了从一个或多个 DataStream 生成新的 DataStream 的操作。DataStream 的底层就是一个 Transformation,描述了这个 DataStream 是怎么来的。
DataSteam 上常见的 transformation 有 map、flatmap、filter 等。这些 transformation 会构造出一个 StreamTransformation 树,通过这棵树转换成 StreamGraph。
以 map 为例,分析 List<Transformation<?>> transformations 的数据:
DataStream.java
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
// 通过 java reflection 抽出的 mapper 的返回值类型
TypeInformation<R> outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
return map(mapper, outType);
}
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper, TypeInformation<R> outputType) {
// 返回一个新的DataStream,StreamMap 为 StreamOperator 的实现类
return transform("Map", outputType, new StreamMap<>(clean(mapper)));
}
public <R> SingleOutputStreamOperator<R> transform(
String operatorName,
TypeInformation<R> outTypeInfo,
OneInputStreamOperator<T, R> operator) {
return doTransform(operatorName, outTypeInfo, SimpleOperatorFactory.of(operator));
}
protected <R> SingleOutputStreamOperator<R> doTransform(
String operatorName,
TypeInformation<R> outTypeInfo,
StreamOperatorFactory<R> operatorFactory) {
// read the output type of the input Transform to coax out errors about MissingTypeInfo
transformation.getOutputType();
// 新的 transformation 会连接上当前 DataStream 中的 transformation,从而构建成一棵树
OneInputTransformation<T, R> resultTransform = new OneInputTransformation<>(
this.transformation,
operatorName,
operatorFactory,
outTypeInfo,
environment.getParallelism());
@SuppressWarnings({"unchecked", "rawtypes"})
SingleOutputStreamOperator<R> returnStream = new SingleOutputStreamOperator(environment, resultTransform);
// 所有的 transformation 都会存到 env 中,调用 execute() 时遍历该 list 生成 StreamGraph
getExecutionEnvironment().addOperator(resultTransform);
return returnStream;
}
从上方代码可以了解到,map 转换用户自定义的函数 MapFunction 包装到 StreamMap 这个 Operator 中,再将 StreamMap 包装到 OneInputTransformation,最后该 transformation 存到 env 中,当调用 env.execute() 时,遍历其中的 transformation 集合构造出 StreamGraph。分层实现如下图所示:
 另外,并不是每一个 StreamTransformation 都会转换成 runtime 层中的物理操作。有一些只是逻辑概念,比如 union、split / select、partition 等。如下图所示的转换树,在运行时会优化成下方的操作图。
另外,并不是每一个 StreamTransformation 都会转换成 runtime 层中的物理操作。有一些只是逻辑概念,比如 union、split / select、partition 等。如下图所示的转换树,在运行时会优化成下方的操作图。
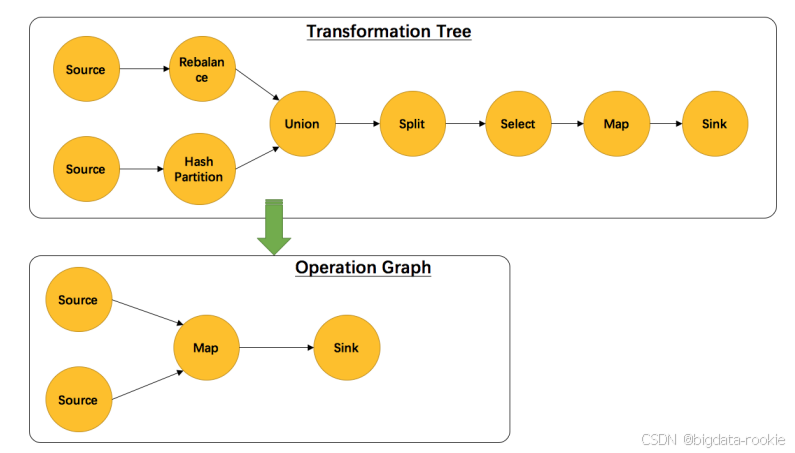 union、split / select、partition 中的信息会被写入到 Source -> Map 的边中。通过源码也可以发现 UnionTransformation、SplitTransformation、SelectTransformation、PartitionTransformation 由于不包含具体的操作,所以都没有 StreamOperator 成员变量,而其他的 StreamTransformation 的子类基本上都有。
union、split / select、partition 中的信息会被写入到 Source -> Map 的边中。通过源码也可以发现 UnionTransformation、SplitTransformation、SelectTransformation、PartitionTransformation 由于不包含具体的操作,所以都没有 StreamOperator 成员变量,而其他的 StreamTransformation 的子类基本上都有。
继续分析 StreamGraph 生成的源码:
StreamExecutionEnvironment.getStreamGraph() -> StreamGraphGenerator.generator() -> StreamGraphGenerator.transform()
StreamGraphGenerator.java
// 对每个 transformation 进行转换,转换成 StreamGraph 中的 StreamNode 和 StreamEdge
// 返回值为该 transform 的 id 集合,通常大小为 1 个(除 FeedbackTransformation)
private Collection<Integer> transform(Transformation<?> transform) {
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
LOG.debug("Transforming " + transform);
if (transform.getMaxParallelism() <= 0) {
// if the max parallelism hasn't been set, then first use the job wide max parallelism
// from the ExecutionConfig.
int globalMaxParallelismFromConfig = executionConfig.getMaxParallelism();
if (globalMaxParallelismFromConfig > 0) {
transform.setMaxParallelism(globalMaxParallelismFromConfig);
}
}
// call at least once to trigger exceptions about MissingTypeInfo
// 为了触发 MissingTypeInfo 的异常
transform.getOutputType();
@SuppressWarnings("unchecked")
final TransformationTranslator<?, Transformation<?>> translator =
(TransformationTranslator<?, Transformation<?>>) translatorMap.get(transform.getClass());
Collection<Integer> transformedIds;
if (translator != null) {
transformedIds = translate(translator, transform);
} else {
transformedIds = legacyTransform(transform);
}
// need this check because the iterate transformation adds itself before
// transforming the feedback edges
if (!alreadyTransformed.containsKey(transform)) {
alreadyTransformed.put(transform, transformedIds);
}
return transformedIds;
}private Collection<Integer> translate(
final TransformationTranslator<?, Transformation<?>> translator,
final Transformation<?> transform) {
checkNotNull(translator);
checkNotNull(transform);
final List<Collection<Integer>> allInputIds = getParentInputIds(transform.getInputs());
// the recursive call might have already transformed this
if (alreadyTransformed.containsKey(transform)) {
return alreadyTransformed.get(transform);
}
final String slotSharingGroup = determineSlotSharingGroup(
transform.getSlotSharingGroup(),
allInputIds.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList()));
final TransformationTranslator.Context context = new ContextImpl(
this, streamGraph, slotSharingGroup, configuration);
return shouldExecuteInBatchMode
? translator.translateForBatch(transform, context)
: translator.translateForStreaming(transform, context);
}
SimpleTransformationTranslator.java
public Collection<Integer> translateForStreaming(final T transformation, final Context context) {
checkNotNull(transformation);
checkNotNull(context);
// 区分 map之类的转换算子(OneInput) 和 keyby值类的分区算子(partition)
final Collection<