一 题记
目标是在某款 RV1106 低算力小板下跑通OCR文字识别算法,做个简单的应用,RK 官方模型库rk_model_zoo 有PP-OCR 的例子,但在 rv1106 上尚未支持。于是便打算折腾一吧。
二 方案甄选
参考国外某大佬的比较:
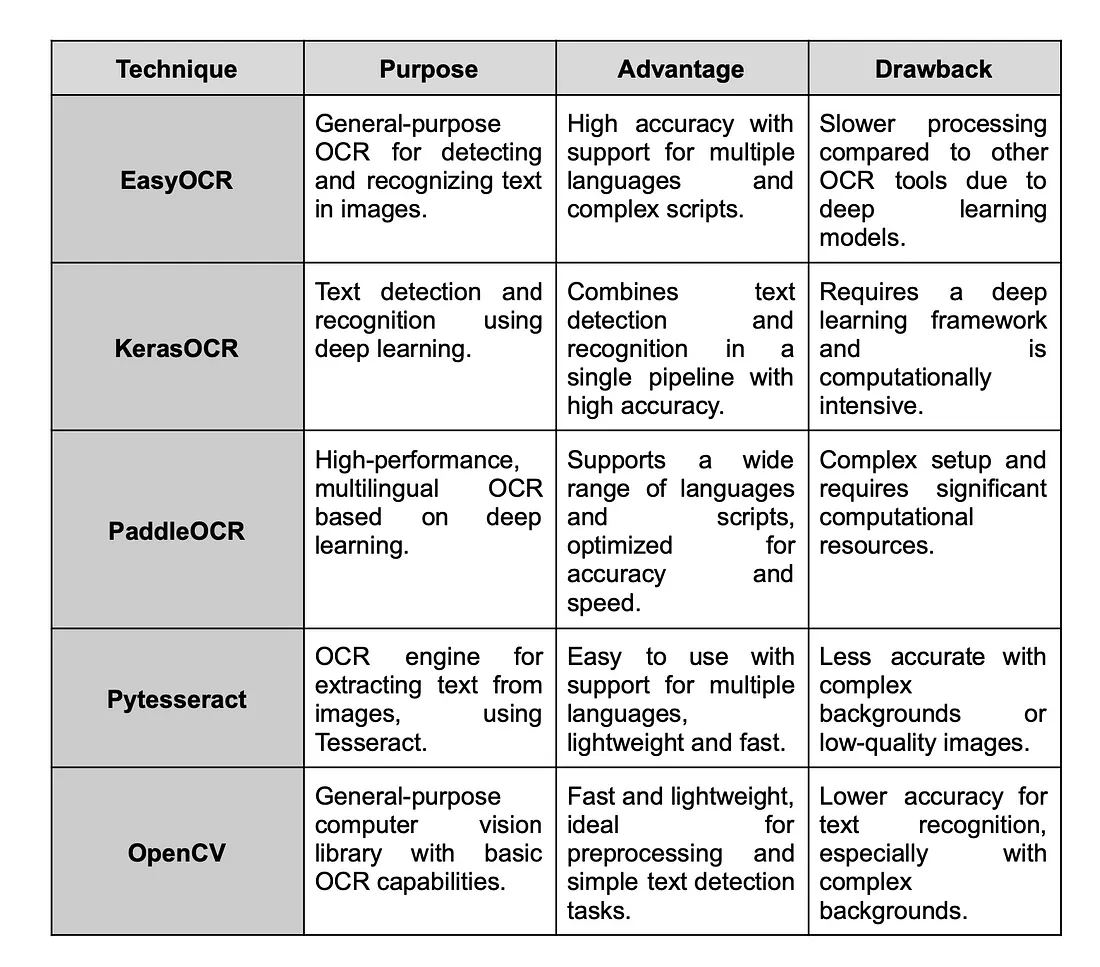
对比了几种方案, paddleOCR 在性能和精度上 应该算得上最优, 工程部署上的事情应该不是大问题。
hugging-face 的在线比较 : (PaddleOCR + EasyOcr + kerasOCR)
https://huggingface.co/spaces/pragnakalp/OCR-image-to-text
简单测试了一下,ppocr 在复杂的比如模糊的反光的照片下效果要好一些。
三 思路梳理
3.1 OCR 处理的通用流程
图像预处理(尺寸,归一化)=> 检测文字区域(OCR-DET) => 子图规一化(尺寸,角度变换) => 文字识别(OCR-REC)
- 其中 OCR-DET 和 OCR-REC 需要 预训练的算法模型来做
- 图像预处理是要将图像 调整到模型输入的大小,在 RKNN 平台,要固定输入图像的尺寸。
- 子图规一化,是将检测区域的子图像扣出来,拉成 横平竖直的规整图像。主要是做视角和尺寸的变换(仿射变换)。但 paddleOCR 可以识别 0 度和180度图像 , 90度和270度与不是模型的输入顺序,需要 通过 方向分类模型判断方向,旋转,然后再做仿射变换。
3.2 模型部署转换的流程
paddle模型 ==> 固定输入的onnx 模型 ==> rknn 模型
因为 rknn不支持动态输入,所以转 onnx 时要固定输入
其他tricks:
paddle 转 onnx模型本身是支持优化的,onnx 转 rknn 时工具也有针对rknn 平台的优化, 用类似 onnx-sim 工具再做优化价值不大。 不如实际 RKNN 跑起来做性能评估针对性的优化。
四 paddleOCR 转 rknn
4.1 基础环境
最好是用个 conda环境或 docker,python推荐 3.10 版本, 与其他 python包 依赖库版本冲突问题很难解决。
paddleOCR和 rknn_toolkit2 环境可以安装在一起
- paddleOCR
pip install paddlepaddle paddle2onnx- rknn_toolkit2
git clone https://github.com/airockchip/rknn-toolkit2
cd rknn-toolkit2
pip install -r packages/x86_64/requirements_cp310-2.3.2.txt
pip install packages/x86_64/rknn_toolkit2-2.3.2-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl4.2 下载模型
来源 :
https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.9/doc/doc_ch/models_list.md
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_det_infer.tar
wget https://paddleocr.bj.bcebos.com/PP-OCRv4/chinese/ch_PP-OCRv4_rec_infer.tar
wget https://paddleocr.bj.bcebos.com/dygraph_v2.0/ch/ch_ppocr_mobile_v2.0_cls_infer.tar4.3 paddle2onnx
- 检测模型
tar xf ch_PP-OCRv4_det_infer.tar
MODEL=ch_PP-OCRv4_det_infer
#export base model to onnx
paddle2onnx --model_dir $MODEL \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file $MODEL/model.onnx \
--opset_version 12
# Seting fix input shape
python -m paddle2onnx.optimize --input_model $MODEL/model.onnx \
--output_model $MODEL/ch_ppocrv4_det.onnx \
--input_shape_dict "{'x':[1,3,544, 960]}"- 识别模型
tar xf ch_PP-OCRv4_rec_infer.tar
MODEL=ch_PP-OCRv4_rec_infer
# export base model to onnx
paddle2onnx --model_dir $MODEL \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--save_file $MODEL/model.onnx \
--opset_version 12
# Seting fix input shape
python -m paddle2onnx.optimize --input_model $MODEL/model.onnx \
--output_model $MODEL/ch_ppocrv4_rec.onnx \
--input_shape_dict "{'x':[1,3,48,320]}"
4.4 onnx2rknn
参考这里:
https://github.com/airockchip/rknn_model_zoo/issues/89
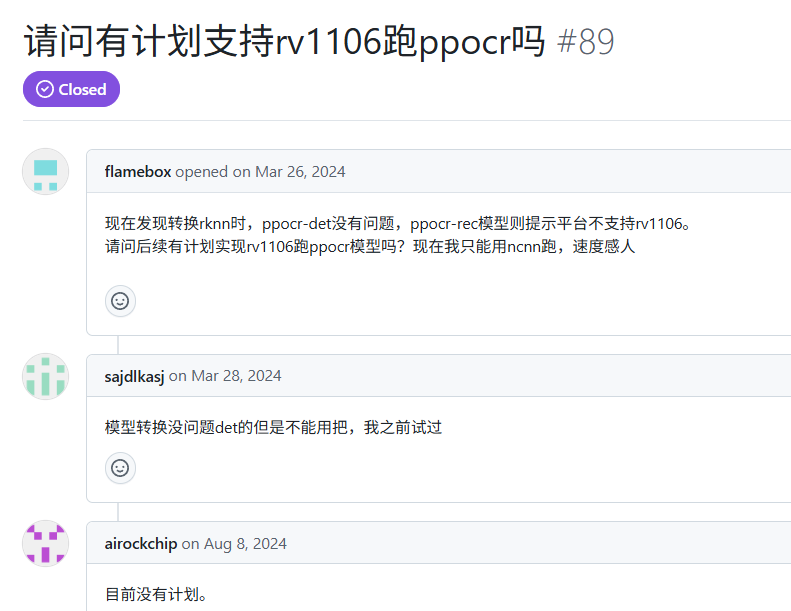
目前RK官方的例子里 ppocr-det 能转换成功,执行不成功, ppocr-rec 没有做 RV1106 转换脚本 ,试了魔改一下能转换成功, 但执行的时候提示有不支持的算子 (可能是ReduceMean的通道数问题)
下面来一一解决
4.4.1 PPOCR-Det 转 RKNN
使用这个脚本:
https://github.com/airockchip/rknn_model_zoo/blob/main/examples/PPOCR/PPOCR-Det/python/convert.py
python3 convert.py ch_ppocrv4_det.onnx rv1106 i8 ch_ppocrv4_det.rknn推理时要修改一下 这个代码 :
- 模型输入输出要用 rknn_create_mem分配 cma 内存之后 调用 rknn_set_io_mem , rv1106 不支持虚拟地址 推理,参考 https://github.com/airockchip/rknn_model_zoo/blob/main/examples/yolov5/cpp/rknpu2/yolov5_rv1106_1103.cc
- 转换的模型 output_attr 的数据FMT 会读取错(可能 rknn的bug), 此时 要强制 output_attrs[0].fmt = NHWC,再设置rknn_set_io_mem 可以成功.
4.4.2 PPOCR-REC 转 RKNN
修改转换脚本 :
https://github.com/airockchip/rknn_model_zoo/blob/main/examples/PPOCR/PPOCR-Rec/python/convert.py
#默认打开量化
DEFAULT_QUANT = True
#提供量化数据集
dataset='./dataset.txt'
# 配置
rknn.config(mean_values=[[127.5,127.5,127.5]], std_values=[[127.5,127.5,127.5]], target_platform=platform)
# BUILD
ret = rknn.build(do_quantization=do_quant, dataset=DATASET_PATH)这样可以成功转换出模型, 同时需要修改推理代码:
参考 4.4.1 说明 修改:
到板子下执行
会报错:
E RKNN: unsupport cpu exNorm op, op name: exNorm:p2o.ReduceMean.0_2ln in current, please try updating to the latest version of the toolkit2 and runtime from: https://console.zbox.filez.com/l/I00fc3 (PWD: rknn) E RKNN: rknn fallback cpu failed
日志显示 ReduceMean 这个算子fallback 到 cpu 也没法兼容 , 白折腾了?
ps: 演砸了,后事如何 请看下回分解。。
4.5 ppocr-det 拆分后再转rknn
4.5.1 模型分析
使用 Netron 查看 ch_ppocrv4_rec.onnx, ReduceMean 出现在后小半部分,
考虑先把 onnx 拦腰斩断,前半部分转rknn , 后半部分用onnx 推理
找到了这条长蛇的七寸
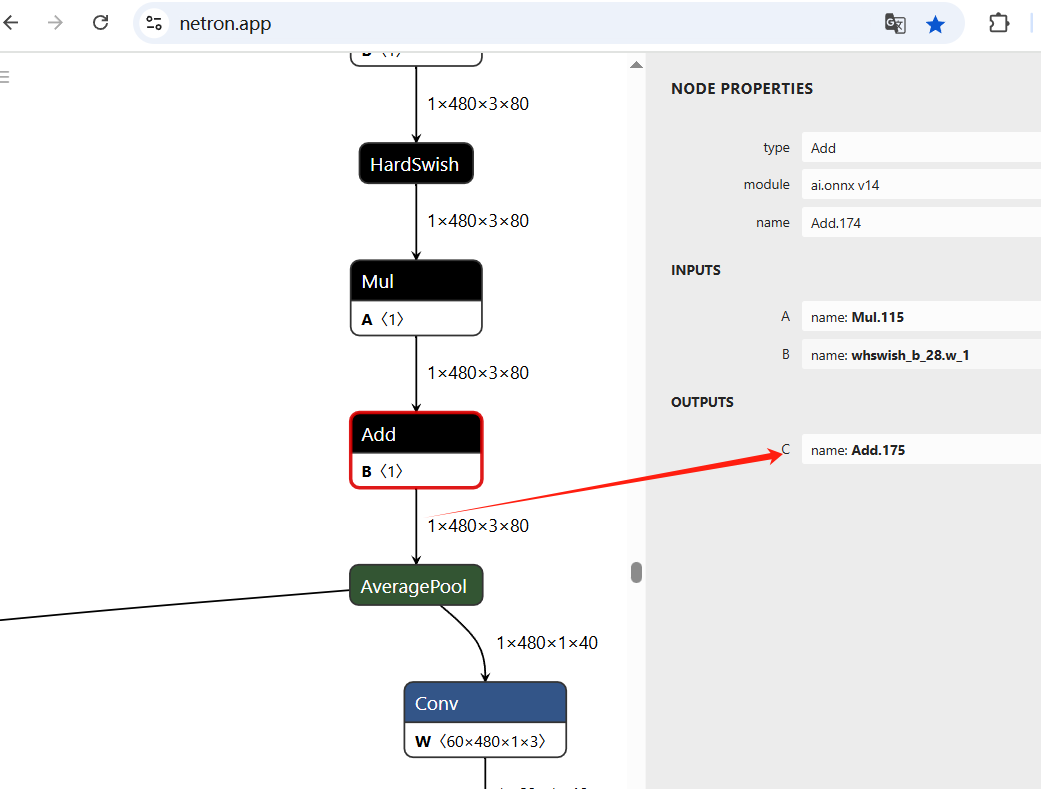
4.5.2 使用 onnxutils 工具进行拆分
import onnx
#first.onnx
input_path = "ch_PP-OCRv4_rec_infer.onnx"
output_path = "first.onnx"
input_names = ["x"]
output_names = ["Add.175"]
onnx.utils.extract_model(input_path, output_path, input_names, output_names)
#second.onnx
input_path = "ch_PP-OCRv4_rec_infer.onnx"
output_path = "second.onnx"
input_names = ["Add.175"]
output_names = ["softmax_2.tmp_0"]
onnx.utils.extract_model(input_path, output_path, input_names, output_names)
4.5.3 拆分之后的处理
拆分之后 第一个模型输出为1x480x3x80 , 转 rknn , 输出为 1x480x3x80 int8 要转 fp32
第二个模型为 onnx 就用onnxruntime 来推理
4.5.4 转换后速度
first.rknn 推理时间 <40ms , second.onnx 用 onnxruntime 推理 100~200ms ( 英文模型时间会更短)
比起 ppocr-rec.onnx 直接用 onnxruntime推理 (> 2s 时间) 大大缩短了执行时间