上一讲我分享了如何使用 Redis 缓存库存数据,其中提到过库存数据及其内存缓存的实现。要知道,库存数据会被高频访问,为了实现库存数据高性能访问,我们需要把它缓存到内存中。那么,除了库存数据外,秒杀系统还有哪些高频访问数据需要内存缓存呢?
在秒杀系统中,还有这几类数据会被高频访问:活动信息、库存信息、用户抢购次数、黑白名单。其中,活动信息和黑白名单访问量最大,且活动开始后基本不会被修改,特别适合缓存在内存中。库存信息和用户抢购次数在活动开始后虽然时刻在变动,但为了实现高性能中间层流量拦截器,我们也需要将它们在内存中缓存一份。
既然有四种数据需要缓存到内存中,那么内存缓存的核心逻辑该如何实现呢?
还记得上一讲我给你介绍的基于 Redis 的库存缓存吗?它提供了 Set、Get、Del 等方法。同样,内存缓存也需要有这些功能,以便足够通用。
虽然功能大同小异,但内存缓存在细节上跟 Redis 还是有些区别,比如,根据业务特点,我们在实现内存缓存的时候可以采用不同的策略,让内存缓存性能最优。
就拿秒杀系统来说,活动信息和黑白名单在活动开始后基本只有读请求,而库存信息和用户抢购次数在秒杀活动开始后读和写的请求量都很大。其中,活动信息在缓存中 Value 是结构体,而黑白名单、库存信息、用户抢购次数的 Value 是整数。因此,在这几种业务场景中,我们实现的内存缓存需要对结构体和整数这两种数据类型做性能优化。
具体怎么做呢?接下来我给你详细介绍下。
整数内存缓存
整数内存缓存主要是以保存整数为主,这里我将它命名为 IntCache。它的定义在 infrastructure/stores/cache.go 中,如下所示:
type IntCache interface {
Get(key string) (int64, bool)
Set(key string, val int64)
Add(key string, delta int64) int64
Del(key string)
}
总共是有 Get、Set、Add、Del 这四种方法,分别对应获取、设置、增加、删除这四种操作。这些方法具体要怎么实现呢?
首先,内存缓存的数据结构是 KV 结构,对应到 Go 语言中是 map 类型。因此我们需要用 map 来缓存数据。
其次,内存缓存是要在高并发下运行的,必须要考虑到多线程下并发读写数据的问题,通常需要加锁,一般是读写锁。假如并发不是很大,不需要追求极致性能,可以考虑使用 Go 标准库中的 sync.Map。
但是,对秒杀系统来说,它的并发已经达到了我们有足够理由追求极致性能,我们需要评估 sync.Map 的性能,特别是其内部使用了互斥锁,容易产生加锁冲突。为此,还需我们自己去实现性能更好的内存缓存。特别是对于库存信息和用户抢购次数这类数据,我们更要自己实现,因为通用缓存为了考虑通用性,通常会牺牲一些性能。
基于以上两点,我定义了一个intCache 结构体来实现整数缓存,它包含一个读写锁和 map 类型的 data 字段。然后开始实现前面定义的 Get、Set、Add、Del 方法,以及一个用于创建 IntCache 的函数 NewIntCache。具体代码如下:
type intCache struct {
sync.RWMutex
data map[string]*int64
}
func NewIntCache() IntCache {
return &intCache{
data: make(map[string]*int64),
}
}
func (c *intCache) getPtr(key string) *int64 {
c.RLock()
vp, _ := c.data[key]
c.RUnlock()
return vp
}
func (c *intCache) Set(key string, val int64) {
vp := c.getPtr(key)
if vp != nil {
atomic.StoreInt64(vp, val)
} else {
vp = new(int64)
*vp = val
c.Lock()
c.data[key] = vp
c.Unlock()
}
}
func (c *intCache) Get(key string) (int64, bool) {
vp := c.getPtr(key)
if vp != nil {
return atomic.LoadInt64(vp), true
}
return 0, false
}
func (c *intCache) Add(key string, delta int64) int64 {
vp := c.getPtr(key)
if vp != nil {
return atomic.AddInt64(vp, delta)
} else {
var val int64
var ok bool
c.Lock()
if vp, ok = c.data[key]; ok {
val = atomic.AddInt64(vp, delta)
} else {
val = delta
vp = &val
c.data[key] = vp
}
c.Unlock()
return val
}
}
func (c *intCache) Del(key string) {
vp := c.getPtr(key)
if vp != nil {
c.Lock()
delete(c.data, key)
c.Unlock()
}
}
整数内存缓存中,Set、Add、Del 都是改写数据的方法,这类方法中通常需要加写锁来防止数据不一致。但是,写锁是互斥锁,直接加写锁会导致性能下降。因此,我在定义 data 字段时,map 的 Value 类型用的是整数指针,以便结合原子操作来快速修改数据。并且,我还实现了一个 getPtr 方法,通过加读锁来获取对应 key 的整数指针。
在 Set 和 Add 方法中,如果该指针存在,则使用原子操作,否则使用写锁。而在 Del 方法中,如果该指针存在,则加写锁并删除数据,否则直接返回。
接下来,我们在 infrastructure/stores/cache_test.go 中实现单元测试,调用我们实现的 New函数,验证缓存功能是否正常。代码如下所示:
func TestIntCache(t *testing.T) {
c := stores.NewIntCache()
key := "test"
c.Set(key, 1)
if v, ok := c.Get(key); !ok || v != 1 {
t.Fatal("failed")
}
if v := c.Add(key, 5); v != 6 {
t.Fatal("failed")
}
c.Del(key)
if _, ok := c.Get(key); ok {
t.Fatal("failed")
}
}
在 Goland 中点击单元测试函数左边的绿色箭头,或者在项目根目录下执行命令 go test -v ./infrastructure/stores ,便可以运行单元测试。如果代码逻辑正确,你将看到 PASS TestIntCache。
最后,我们来实现 IntCache 的性能测试。同时,我们也为 sync.Map 的 Store、Load、Delete 方法实现性能测试函数,与 IntCache 的 Set、Get、Del 方法对比性能。通过一个环境变量 maxKey,我们可以控制测试过程中使用不同数量的 key 测试性能。具体代码如下:
func initKeys(b *testing.B) []string {
var keys = make([]string, 0)
maxKeyStr := os.Getenv("maxKey")
maxKey, _ := strconv.Atoi(maxKeyStr)
if maxKey <= 0 {
maxKey = b.N
}
for i := 0; i < maxKey; i++ {
keys = append(keys, strconv.Itoa(i))
}
return keys
}
func initIntCache(b *testing.B, c stores.IntCache, keys []string) {
l := len(keys)
for i := 0; i < b.N; i++ {
c.Set(keys[i%l], int64(i))
}
}
func initSyncMap(b *testing.B, c sync.Map, keys []string) {
l := len(keys)
for i := 0; i < b.N; i++ {
c.Store(keys[i%l], int64(i))
}
}
func BenchmarkIntCache_Add(b *testing.B) {
keys := initKeys(b)
c := stores.NewIntCache()
initIntCache(b, c, keys)
l := len(keys)
b.ReportAllocs()
b.StartTimer()
for i := 0; i < b.N; i++ {
c.Add(keys[i%l], 1)
}
b.StopTimer()
}
func BenchmarkIntCache_Set(b *testing.B) {
keys := initKeys(b)
c := stores.NewIntCache()
b.ReportAllocs()
b.StartTimer()
initIntCache(b, c, keys)
b.StopTimer()
}
func BenchmarkSyncMap_Set(b *testing.B) {
keys := initKeys(b)
c := sync.Map{}
b.ReportAllocs()
b.StartTimer()
initSyncMap(b, c, keys)
b.StopTimer()
}
func BenchmarkIntCache_Get(b *testing.B) {
keys := initKeys(b)
c := stores.NewIntCache()
initIntCache(b, c, keys)
l := len(keys)
b.ReportAllocs()
b.StartTimer()
for i := 0; i < b.N; i++ {
c.Get(keys[i%l])
}
b.StopTimer()
}
func BenchmarkSyncMap_Get(b *testing.B) {
keys := initKeys(b)
c := sync.Map{}
initSyncMap(b, c, keys)
l := len(keys)
b.ReportAllocs()
b.StartTimer()
for i := 0; i < b.N; i++ {
c.Load(keys[i%l])
}
b.StopTimer()
}
func BenchmarkIntCache_Del(b *testing.B) {
keys := initKeys(b)
c := stores.NewIntCache()
initIntCache(b, c, keys)
l := len(keys)
b.ReportAllocs()
b.StartTimer()
for i := 0; i < b.N; i++ {
c.Del(keys[i%l])
}
b.StopTimer()
}
func BenchmarkSyncMap_Del(b *testing.B) {
keys := initKeys(b)
c := sync.Map{}
initSyncMap(b, c, keys)
l := len(keys)
b.ReportAllocs()
b.StartTimer()
for i := 0; i < b.N; i++ {
c.Delete(keys[i%l])
}
b.StopTimer()
}
为了测试不同 key 时的性能,我们在项目根目录下执行 go test -v -bench=. ./infrastructure/stores | grep allocs。你将看到以 Benchmark 开头的 5 列数据,分别是:函数名、执行次数、每次耗时、每次分配内存大小、每次分配内存次数。如下所示:
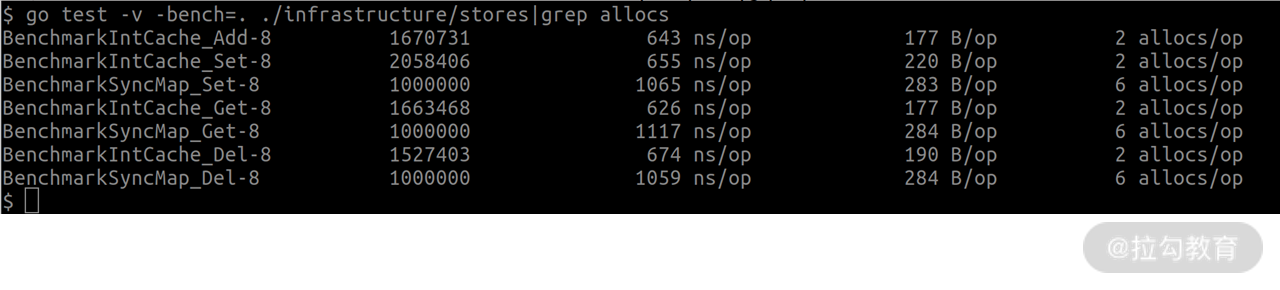
通过对比我们不难发现:当使用完全不同的 key 时,IntCache 性能是 sync.Map 的 1.5 ~ 2 倍,它的内存分配次数是 sync.Map 的 1/3。使用不同 key 对应到秒杀的哪个业务场景呢?那就是用户抢购次数缓存。因为有上百万的用户参与活动,每个用户都有自己的抢购次数,在缓存中会存在大量不同的 key。
而库存数据是少量数据,它对应到性能测试中则是相同的 key 的场景。我们可以在命令前面加上 maxKey=100 环境变量来指定使用 100 个 key 来做性能测试。结果如下:
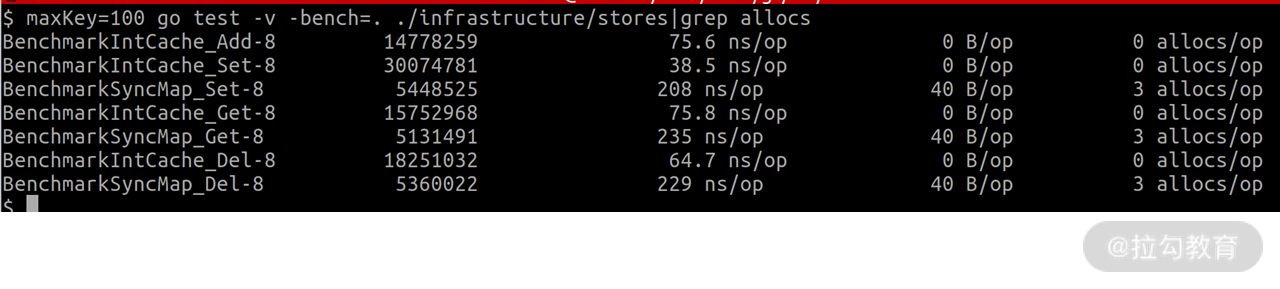
通过对比可以看到,此时 IntCach的性能是 sync.Map 的 3 倍以上。
对象内存缓存
前面我提到黑白名单、库存信息、用户抢购次数可以用整数内存缓存来提升性能,而活动信息则可以用对象内存缓存来提升性能。它的实现过程跟整数内存缓存的类似,区别在于它不需要 Add ,只需要 Get、Set、Del 这三个方法。对象内存缓存的定义如下所示:
type ObjCache interface {
Get(key string) (interface{}, bool)
Set(key string, val interface{})
Del(key string)
}
接下来,我们就可以参考整数内存缓存的实现方式来实现对象内存缓存。具体来说,也就是定义一个 objCache 结构体类型,包含一个读写锁和一个 data 字段。其中 data 字段的类型也是 map,但该 map 的 Value 类型是 interface,这样它能保存任意类型的对象。然后我们再实现它的三个方法,以及一个用于创建对象内存缓存的函数 NewObjCache。代码如下所示:
type objCache struct {
sync.RWMutex
data map[string]interface{}
}
func NewObjCache() ObjCache {
return &objCache{
data: make(map[string]interface{}),
}
}
func (oc *objCache) Set(key string, data interface{}) {
oc.Lock()
oc.data[key] = data
oc.Unlock()
}
func (oc *objCache) Get(key string) (interface{}, bool) {
oc.RLock()
v, ok := oc.data[key]
oc.RUnlock()
return v, ok
}
func (oc *objCache) Del(key string) {
if _, ok := oc.Get(key); ok {
oc.Lock()
delete(oc.data, key)
oc.Unlock()
}
}
在单元测试中,我们调用 NewObjCache 创建一个对象内存缓存,并调用 Set、Get、Del 方法进行测试。代码如下:
func TestObjCache(t *testing.T) {
c := stores.NewObjCache()
key := "test"
c.Set(key, int64(1))
if v, ok := c.Get(key); !ok || v.(int64) != 1 {
t.Fatal("failed")
}
c.Del(key)
if _, ok := c.Get(key); ok {
t.Fatal("failed")
}
}
同样地,我们也参考整数内存缓存,实现对象内存缓存 Get、Set、Del 的性能测试函数。代码如下:
func initObjCache(b *testing.B, c stores.ObjCache, keys []string) {
l := len(keys)
for i := 0; i < b.N; i++ {
c.Set(keys[i%l], int64(i))
}
}
func BenchmarkObjCache_Set(b *testing.B) {
keys := initKeys(b)
c := stores.NewObjCache()
b.ReportAllocs()
b.StartTimer()
initObjCache(b, c, keys)
b.StopTimer()
}
func BenchmarkObjCache_Get(b *testing.B) {
keys := initKeys(b)
c := stores.NewObjCache()
initObjCache(b, c, keys)
l := len(keys)
b.ReportAllocs()
b.StartTimer()
for i := 0; i < b.N; i++ {
c.Get(keys[i%l])
}
b.StopTimer()
}
func BenchmarkObjCache_Del(b *testing.B) {
keys := initKeys(b)
c := stores.NewObjCache()
initObjCache(b, c, keys)
l := len(keys)
b.ReportAllocs()
b.StartTimer()
for i := 0; i < b.N; i++ {
c.Del(keys[i%l])
}
b.StopTimer()
}
注意,为了方便对比数据,我们需要将上面的函数放到整数内存缓存相应函数的下面。由于活动信息数量比较少,我们使用环境变量 maxKey=100 控制 key 的个数并执行性能测试命令。最终输出结果如下:
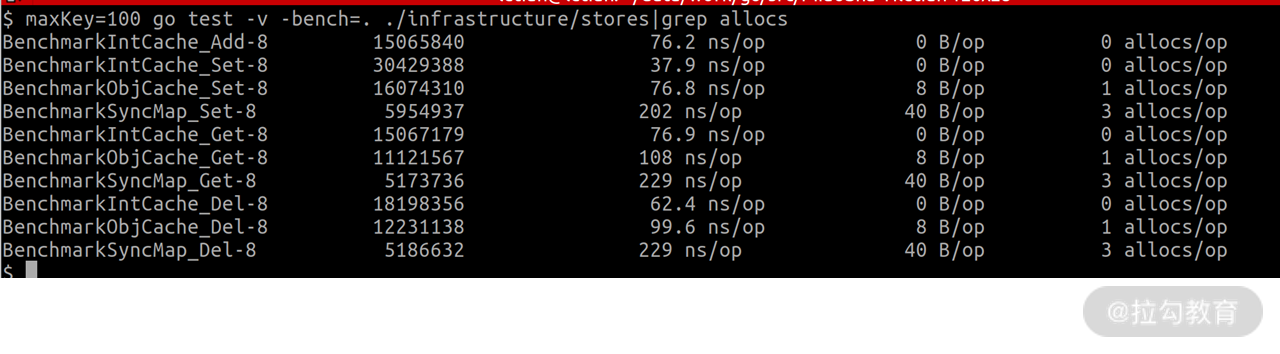
可以看到,对象内存缓存的性能是 sync.Map 的 2 倍以上。
小结
这一讲我给你介绍了内存缓存是如何设计和实现的,并借助 Go 的性能测试框架来对比不同方案的性能。希望你能学以致用,在工作中能快速分析出手头项目应当用哪种缓存方案,在性能和开发成本之间做好权衡。
思考题:
你也可以想想,实现好内存缓存后,该如何从 Redis 中读取数据并初始化内存缓存呢?
可以在留言区给出自己的答案哦。期待你的讨论!
好了,这一讲就到这里了。下一讲,我将给你介绍“如何实现连接池减少连接所需时间”。到时见!
源码地址:https://github.com/lagoueduCol/MiaoSha-Yiletian/tree/main/infrastructure
精选评论
**民:
请教下,怎么同步更新多节点内存缓存,毕竟数据从redis过来,没法像etcd一样有事件通知机制。
讲师回复:
通常是借助MQ做异步更新。本地内存缓存的数据允许短时间内数据不一致